点击蓝字关注我们


扫码关注我们
公众号 : 计算机视觉战队
扫码回复:LocalGAN,获取下载链接
概述
本次分享的文章主要两点贡献。
首先引入了一个新的局部稀疏注意层(local sparse attention layer),该层保留了二维几何形状和局部性。文章证明,用文章的结构替换SAGAN的密集注意力层,我们就可以获得非常显着的FID,初始得分(Inception score )和纯净的视觉效果。在其他所有参数保持不变的情况下,FID分数在ImageNet上从18.65提高到15.94。我们为新层提议的稀疏注意力模式(sparse attention patterns)是使用一种新的信息理论标准设计的,该标准使用信息流图。
文章还提出了一种新颖的方法来引起对立的对抗网络的产生,就是使用鉴别器的注意力层来创建创新的损失函数(an innovative loss function)。这使我们能够可视化新引入的关注头,并表明它们确实捕获了真实图像二维几何的有趣方面。
背景
生成对抗网络在建模和生成自然图像方面取得了重大进展。转置的卷积层是基本的体系结构组件,因为它们捕获了空间不变性,这是自然图像的关键属性。中心局限性是卷积无法对复杂的几何形状和长距离依赖性进行建模–典型的例子是生成的狗的腿数少于或多于4条。
为了弥补这一限制,在深度生成模型中引入了注意层。注意使得能够在单层中对远距离空间相关性进行建模,即使它们相距很远,它也可以自动找到图像的相关部分。注意层首先在SAGAN中引入,然后在BigGAN中进一步改进,这导致了一些目前最著名的GAN。(First introduced in SAGAN and further improved in Big-GAN, attention layers have led to some of the best known GANs currently available.)
注意层有一些限制。首先是它们在计算上效率低下:标准的密集注意力需要内存和时间复杂度在输入大小上成倍增加。其次,密集的注意层在统计上是无效的:需要大量的训练样本来训练注意层,当引入多个注意头(attention heads)或注意层(attention layers)时,这个问题变得更加明显。统计效率低下还源于以下事实,即注意力集中并不能从位置中受益,因为图像中的大多数依赖关系都与附近的像素邻域有关。最近的工作表明,大多数注意力层负责人(attention layer heads )学会了关注局部区域。
为了减轻这些限制,最近在稀疏变压器(Sparse Transformers)中引入了稀疏注意层(sparse attention layers)。在那篇论文中,介绍了不同类型的稀疏注意内核(sparse attention kernels),并将其用于获得图像,文本和音频数据的优秀的结果。他们所做的主要观察是,稀疏变压器中引入的模式实际上是针对一维数据(如文本序列)设计的。稀疏变压器通过重塑张量以显着扭曲图像像素二维网格距离的方式应用于图像。因此,稀疏变压器中引入的局部稀疏注意内核(sparse attention kernels)无法捕获图像局部性。

Local GAN
Full Information Attention Sparsifification
如前所述,p个步骤中的注意分散用二进制掩码{M1,…,MP}。问题是如何为这些注意力步骤设计一套好的面具(masks)。我们从信息论的角度介绍了一个工具来指导这个设计。
信息流图(Information Flow Graphs)是在[Alexandros G Dimakis, P Brighten Godfrey, Yunnan Wu, Martin J Wainwright, and Kannan Ramchandran. Network coding for distributed storage systems. IEEE transactions on information theory, 56(9):4539–4551, 2010]中通过网络信息流引入到分布式存储系统模型中的有向无环图。对于我们的问题,这个图模拟了信息是如何跨注意步骤流动的。对于给定的掩码集合{M1,…,MP}我们创建了一个多部图G(V = {V0, V1,…VP}其中,Vi、Vi+1之间的有向连接由掩模Mi确定。分区代理中的每一组顶点对第i步的注意标记作出响应。
如果一个注意稀疏化对应的信息流图从每个节点a∈v0到每个节点b∈Vp有一条有向路径,则我们说这个注意稀疏化是完全信息(Full Information )。请注意,子图2a中显示的固定模式并没有完整的信息:没有从v0的节点1到V2的节点2的路径。
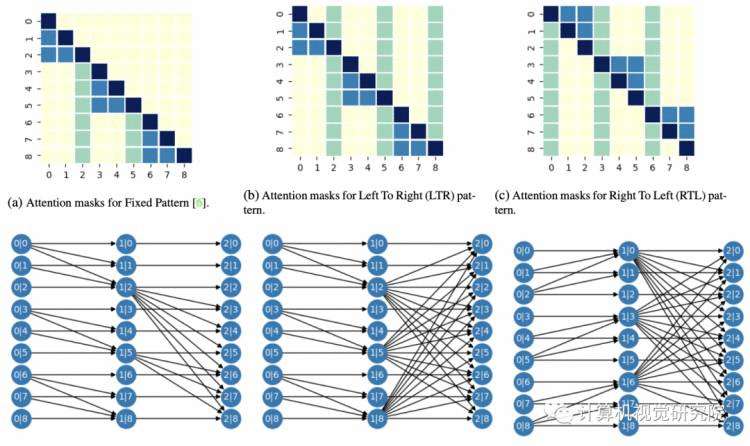
图2
[6]:Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse transformers. arXiv preprint arXiv:1904.10509, 2019.
(a)固定模式[6]的注意掩模(Attention masks)
(b)左至右(LTR)模式的注意掩模
(c)右至左(RTL) pat-的注意掩模
(d)与固定模式相关的信息流图。这个模式没有完整的信息,也就是说,节点之间的依赖关系是注意力层无法建模的。例如,没有从v0的节点0到V2的节点1的路径
(e)与LTR相关的信息流图。该模式具有完整的信息,即在v0的任意节点与V2的任意节点之间存在一条路径。注意,与固定注意模式[6]相比,边缘的数量只增加了一个常数,如2d所示
(f)与RTL有关的信息流图。这个模式也有完整的信息。RTL是LTR的“转置”版本,因此在第一步中,每个节点右侧的本地上下文都是参与的。
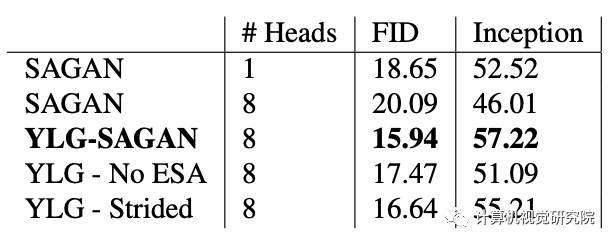
表1
稀疏注意通常被认为是一种减少密集注意的计算开销的方法,希望性能损失很小。然而,我们发现,选择具有二维局部性的注意力掩模,其效果出人意料地优于密集的注意力层(对比表1的第二行和第三行)。这就是我们所说的密集注意力统计效率低下的一个例子。具有局部性的稀疏注意层会产生更好的归纳偏差,因此可以在有限样本情况下表现得更好。在无限数据的限制下,密集的注意力总是可以模拟稀疏的注意力,或者表现得更好,就像一个完全连接的层可以模拟卷积层来选择可能的权值一样。
我们将YLG的稀疏模式设计为模式的自然扩展,同时确保相应的信息流图支持完整的信息。第一个模式称为从左到右(LTR),它将[6]模式扩展到双向上下文中。第二种模式,我们称之为从右到左(RTL),是LTR的一个置换版本,对应的9×9掩模和相关的信息流图如图2b、2e (LTR)和2c、2f (RTL)所示。这些模式只允许注意到n√n个位置,显著降低了密集注意的二次复杂度。使用多个注意力步骤创建非常稀疏的完整信息图是可能的,但是设计和训练它们仍然是未来的工作;在这篇论文中,我们主要关注两步分解。我们在附录中包括了更多关于信息流图的细节,以及我们如何使用它们来设计注意力模式。
注意层有一些限制。首先是它们在计算上效率低下:标准的密集注意力需要内存和时间复杂度,它们在输入大小上成倍增加。其次,密集的注意层在统计上是无效的:需要大量的训练样本来训练注意层,当引入多个注意头或注意层时,这个问题变得更加明显[6]。统计效率低下还源于以下事实,即注意力集中并不能从位置中受益,因为图像中的大多数依赖关系都与附近的像素邻域有关。最近的工作表明,大多数注意力层负责人(attention layer heads)学会了主要参加当地社区的活动。
上图说明了我们在本文中研究的注意层的不同的2步稀疏化。第一行演示了我们对这两个步骤应用的不同布尔掩码。细胞的颜色。j]表示节点i是否可以出席节点j,我们用深蓝色表示两个步骤中的出席位置。用浅蓝色表示第一个掩模的位置,用绿色表示第二个掩模的位置。黄色细胞对应的位置,我们不关注任何步骤(稀疏性)。第二行说明了与上述注意遮罩相关的信息流图。信息流图显示了信息在注意层中是如何“流动”的。直观地,它可视化了我们的模型如何使用2步分解来寻找图像像素之间的依赖关系。在每个多部图中,第一个顶点集的节点对应于注意之前的图像像素。从第一个顶点集V0的一个节点到第二个顶点集V1的一个节点的一条边,意味着V0的节点可以在第一个注意步骤中注意到V1的节点。V1和v2之间的边说明了注意的第二步。
二维位置
上图中所示的稀疏变压器(Sparse Transformers)的因数分解模式及其完整的信息扩展从根本上与一维数据(如文本序列)匹配。
将这些层应用到图像上的标准方法是将三维图像张量(有三个颜色通道)重塑为一个引起注意的二维张量X∈RN×C。这对应于N个标记,每个标记包含一个c维的输入图像区域表示。这一重塑将这N个标记线性排列,极大地扭曲了图像在二维中的邻近部分。此行为在图3左边的子图中进行了说明。
图2
我们认为这就是一维稀疏化不适合于图像的原因。事实上,[6]的作者提到,固定模式(图2a)是为文本序列设计的,而不是为图像设计的。我们的主要发现是,如果正确考虑图像的二维结构,这些模式可以很好地应用于图像。
因此,问题是如何考虑二维局域性。我们可以直接在网格上创建二维的注意力模式,但这会产生大量的计算开销,而且还会阻止我们扩展已知工作良好的一维稀疏化。相反,我们使用以下技巧修改一维稀疏性,以识别二维局部性:(i)我们列举根据他们的曼哈顿距离图像的像素的像素位置(0,0)(打破关系使用行优先),(ii)改变任何给定的指标一维sparsification匹配曼哈顿距离枚举,而不是重塑枚举,和(iii)应用这个新的一维稀疏模式(dimensional sparsifification pattern),尊重二维位置,一维重塑版本的形象。我们将此过程称为ESA(枚举、移位、应用),并在图3中对此进行了说明。

图3
图3:重塑和ESA图像网格单元的枚举,显示如何将图像网格投影到直线上。(左)使用标准重塑的8×8图像的像素计数。此投影仅在行中维护局部性。(右)使用ESA框架对8×8幅图像的像素进行枚举。我们使用从开始的曼哈顿距离(0,0)作为枚举的标准。虽然由于在一维上的投影存在一定的失真,但局域性基本保持不变。
与真正的二维距离相比,ESA技巧引入了一些失真。然而,我们发现这并不是太局限,至少对于128×128分辨率。另一方面,ESA提供了一个重要的实现优势:理论上它允许使用一维的块-稀疏内核(block-sparse kernels)。目前,这些内核只存在于gpu上,但是让它们在TPUs上工作仍在开发中。
实验&验证
我们在颇具挑战性的ImageNet数据集上进行了实验。我们选择SAGAN作为我们模型的基线,因为它与BigGAN不同,它有官方的开源Tensorflow代码。BigGAN不是开源的,因此也没有对其进行培训或修改的可能性。

在我们所有的实验中,我们只改变了SAGAN的注意层,保持所有其他超参数不变(参数的数量不受影响)。我们在单个云TPU v3设备(v3-8)上使用1e - 4的学习速率(generator)和4e - 4的识别器对所有模型进行了最多150万步的训练。对于所有的模型,我们都报告了获得的最佳性能,即使它是在训练的早期获得的。
注意力机制。我们从固定的模式开始(图2a)并对其进行修改:首先,我们创建完整的信息扩展,生成模式Left-ToRight (LTR)和Right-To-Left (RTL)(分别参见图2b和2c)。我们使用不同的头并行地实现多步注意。由于每个模式都是两步稀疏化,因此会产生4个注意头。为了鼓励学习模式的多样性,我们使用每个模式两次,所以在我们的新注意力层中头的总数是8。我们使用ESA过程来呈现这些模式,使其能够识别二维几何图形。
(Non-Square Attention)在SAGAN中,查询图像和注意层中的关键图像具有不同的维度。这使事情变得复杂,因为我们讨论的稀疏模式是为自我关注而设计的,其中查询和关键节点的数量是相同的。其中,SAGAN的查询图像为32×32,关键图像为16×16。我们用最简单的方法来处理这个问题:我们为16×16的图像创建蒙版,然后将这些蒙版移动到32×32图像的区域。因此,32×32的查询图像的每16×16块对应于16×16的关键图像,并具有完整的信息。
表1
结果:如表1所示,通过FID和Inception评分,YLG-SAGAN(第3行)的表现大大优于SAGAN。具体来说,YLG-SAGAN将Inception分数提高到57.22(8.95%的改进),将FID提高到15.94(14.53%的改进)。定性地说,我们观察到的是具有简单几何形状和同质性的类别的非常好看的样本。直观地说,二维的局部性可以产生重要的类别,如山谷或山脉,因为这些类别的图像转换通常比其他类别更平滑,因此依赖关系大多是局部的。
除了显著提高的分数外,使用YLG稀疏层而不是密集注意层的一个重要好处是,我们观察到模型达到最佳性能所需的训练时间显著减少。经过130多万步的训练,SAGAN得到了最好的FID分数,而YLGSAGAN仅经过86.5万步(训练时间缩短约40%)就得到了最优分数。图4显示了SAGAN和YLG-SAGAN FID和Inception分数作为训练时间的函数。
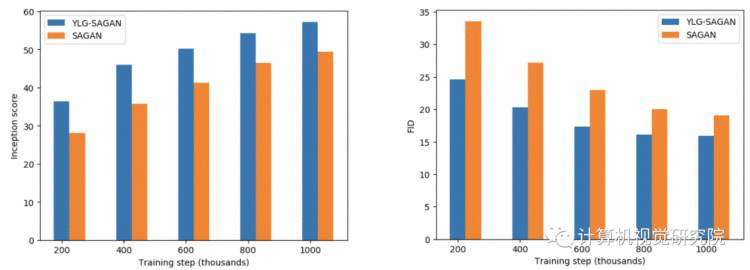
图4
我们创建了两个拼贴来显示来自我们的YLG版本的SAGAN的样本。在图7的上面板中,我们展示了由我们的YLG-SAN生成的不同品种的狗。在下面的面板中,我们使用YLG-SAGAN从ImageNet数据集随机选择的类中生成样本。
Ablation Studies
(Number of Attention Heads)原始的SAGAN实现使用了一个单头注意机制。在YLG中,我们使用多个头来执行并行的多步稀疏注意。以前的工作已经表明,多个头可以提高自然语言处理任务的性能。为了理解多个头部如何影响SAGAN性能,我们训练了一个8头部版本的SAGAN。结果报告在表1的第二行。多个头实际上大大降低了原始SAGAN的性能,将Inception的分数从52.52降低到46.01。我们提供了这个结果的事后解释。SAGAN查询向量的图像嵌入只有32个向量位置。通过使用8个正面,每个正面只能得到4个位置来表示它的向量。我们的直觉是,一个4位向量表示是不充分的有效编码的图像信息密集的头,这是导致性能下降。需要注意的是,YLGSAGAN并不存在这个问题。原因是每个头是稀疏的,这意味着只关注一个百分比的位置,而密集的头关注。因此,较小的向量表示不会影响性能。有多个发散稀疏头允许YLG层发现复杂的依赖关系,在整个图像空间的多步骤的注意。
二维的位置:如上面所述,YLG使用ESA过程,将一维稀疏模式应用于二维结构的数据。我们的动机是,网格局部性可以帮助我们稀疏的注意力层更好地对局部区域建模。为了通过实验验证这一点,我们训练了一个没有ESA过程的YLG版本。我们称这个模型为YLG,而不是ESA。结果如表1第4行所示:没有ESA程序,YLG的性能与原始的SAGAN基本相同。实验结果表明,ESA方法是网格结构数据一维稀疏模式的关键。如果使用ESA框架,FID将从17.47提高到15.94,初始分数从51.09提高到57.22,而模型架构中没有任何其他差异。因此,ESA是一个即插即用的框架,它可以极大地提高FID和Inception分数指标的性能。ESA允许使用快速、稀疏的一维模式,这种模式被发现可以很好地将文本序列适应到图像中,具有极大的性能优势。在下面我们可视化注意力地图,以展示我们的模型如何在实践中利用ESA框架。
稀疏方式 我们的YLG层使用LTR和RTL模式(分别如图2b和2c所示)。我们的直觉是,同时使用多个模式可以提高性能,因为模型将能够使用多个不同的路径发现依赖关系。为了测试这种直觉,我们使用带条纹的[6]模式的完全信息扩展来运行一个实验。我们选择这个模式是因为它被发现是有效的建模图像[6]由于它的周期结构。与LTR和RTL模式一样,我们扩展了Strided模式,使其具有完整的信息4。我们指的是YLG模型,它代替了LTR和RTL模式,有8个头实现了YLG - Strided模式。在我们的实验中,我们再次使用ESA技巧。我们报告表1的第5行上的结果。YLG在FID和Inception分数上都远远超过了SAGAN,但仍然落后于YLG。尽管在稀疏变换[6]中,条纹模式被认为比我们在YLG中使用的模式更适合于图像,但是这个实验强烈地表明网格局域性是造成差异的原因,因为这两个模型都比SAGAN好得多。此外,该实验表明,与使用单个稀疏模式相比,使用多个稀疏模式可以提高性能。需要注意的是,在同一注意力层使用多个不同的模式也需要缩放人头的数量。虽然SAGAN的YLG变化没有受到注意头增加的负向影响,但如果注意头数量增加更严重,则可能会对性能产生潜在的危害,类似于8个头对SAGAN性能的危害。

Inverting Generative Models with Attention
我们感兴趣的是将我们稀疏的注意力可视化在真实的图像上,而不仅仅是生成的图像。这自然导致了将图像投影到发生器范围内的问题,也称为反转。对于给定的实图像x∈Rnand一个生成器G(z),求逆就等于找到一个潜变量z∈Rk,因此G(z)∈rn尽可能地逼近给定的图像x。求逆的一种方法是尝试解决以下非凸优化问题:
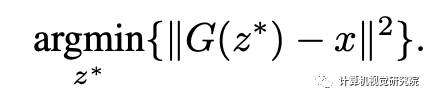
为了解决这个优化问题,我们可以从一个随机的初始化z0进行梯度下降,从而使这个潜在空间中的投影距离最小化。该方法在多篇文献中被独立引入,并进一步推广到求解超越反演的逆问题。最近的研究表明,对于具有随机权值和充分层展开的全连通发生器,梯度下降将被证明收敛于正确的最优反演。
不幸的是,这个理论不适用于具有注意层的生成器。即使在经验上,梯度下降反演法也不适用于更大的生成模型,如SAGAN和YLG-SAGAN。正如我们在实验中所展示的,优化器陷入了局部极小状态,产生的重构只与目标时间隐约相似。其他的反演方法已经在文献中尝试过,比如联合训练一个编码器,但是这些方法都没有已知的成功地反演具有注意层的复杂生成模型。
我们提出了一种新的反演方法,利用鉴别器来解决不同表示空间中的极小化问题。有趣的是,鉴别器产生了一个更平滑的损失场景,特别是如果我们以一种特殊的方式使用注意层。更详细地说,我们从一个随机潜在变量z和一个给定的实像x开始。我们用D0表示鉴别器网络一直到(但不包括)注意层,并得到表示形式D0(G(z))和D0(x)。我们可以通过梯度下降来最小化这些鉴别器表示的距离:

然而,我们发现,我们可以使用真实图像的注意图来进一步增强反演。我们将使用SAGAN体系结构的例子来说明这一点。在萨根判别器的注意内,计算出注意图M∈R32×32×16×16。对于32×32图像的每个像素,该注意图是16×16图像像素上的一个分布。我们可以使用这个注意力地图来提取一个显著性地图。对于16×16图像的每个像素,我们可以对32×32图像中所有像素的概率进行平均,得到形状16×16的概率分布。我们用字母s来表示这个分布,直观地,这个分布代表了图像中每个像素对于鉴别器的重要性。
我们提出的反演算法是通过梯度下降来最小化鉴别器的嵌入距离,由:
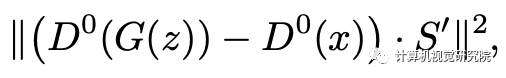
其中s0是显著性映射S到D0(x)维度的投影版本。我们实际上计算每个人的显著性映射s0a,并使用它们的和作为我们优化反演的最终损失函数。
Inversion as lens to attention
给定任意真实图像,我们现在可以求解z,从生成器生成相似的生成图像,并可视化注意力图。

图5
我们以红脚鹬的真实图像为例来说明我们的方法(图5a)。图5b显示了用于反转发电机的标准方法是如何失败的:喙,腿和石头丢失了。图5c显示了我们方法的结果。使用我们通过反演发现的z,我们可以将注意力层的地图投影回原始图像,从而获得有关YLG层如何工作的宝贵见解。

图6
我们提出第二次反转,这次是靛蓝鸟(图6a)。图6b显示了反转的标准方法如何失败:鸟的头部和树枝未重建。我们还将说明特定查询点所在的位置。我们首先说明该模型利用了ESA的局部偏差:我们绘制了生成器头0的查询点(0,0)的注意力图。这个点(用蓝点表示)是背景的一部分。我们清楚地看到了这一点所处位置的局部偏差。二维局部关注的另一个示例在图6e中显示。该图说明了生成器头4的注意图,该图针对鸟的身体上的一个查询点(蓝点)。该点位于鸟的身体边缘和鸟的头部。
我们提出第二次反转,这次是靛蓝鸟(图6a)。图6b显示了反转的标准方法如何失败:鸟的头部和树枝未重建。我们还将说明特定查询点所在的位置。我们首先说明该模型利用了ESA的局部偏差:我们绘制了生成器头0的查询点(0,0)的注意力图。这个点(用蓝点表示)是背景的一部分。我们清楚地看到了这一点所处位置的局部偏差。二维局部关注的另一个示例在图6e中显示。该图说明了生成器头4的注意图,该图针对鸟的身体上的一个查询点(蓝点)。该点位于鸟的身体边缘和鸟的头部。
最后,图6f显示了一些查询点与远距离有关,表明当这些注意点出现在图像中时,注意力机制能够利用位置和远距离关系。

总结

To the left we present real images and to the right our inversions using YLG SAGAN
本次介绍了一种针对二维数据设计的局部稀疏注意层。我们相信,我们的层将广泛适用于任何关注二维数据的模型。一个有趣的未来方向是注意力层的设计,它被认为是一个多步骤的网络。这两个相互冲突的目标是使这些网络尽可能地稀疏(为了计算和统计效率),同时支持良好的信息流。我们引入信息流图作为一种数学抽象,并提出完整信息作为这种注意力网络的期望标准。

最后,我们提出了一种解决GANs反演问题的新方法。我们的技术以两种方式使用鉴别器:第一,利用它的注意力来获得像素的重要性;第二,作为反演损失景观的平滑表示。这种新的反演方法使我们能够在真实图像的近似上可视化我们的网络,并测试生成模型在这个重要的覆盖任务中有多好。我们相信这是使用生成模型解决逆问题的第一个关键步骤,我们计划在未来进一步探索。
感谢《bigbigvegetable的总结》

如果想加入我们“计算机视觉研究院”,请扫二维码加入我们。我们会按照你的需求将你拉入对应的学习群!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!
扫码关注我们
公众号 : 计算机视觉战队
扫码回复:LocalGAN,获取下载链接









 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有