有许多分布式计算系统可以实时或近实时处理大数据。 本文将从对三个Apache框架的简短描述开始,并试图对它们之间的某些相似之处和不同之处提供一个快速的高级概述。
阿帕奇风暴
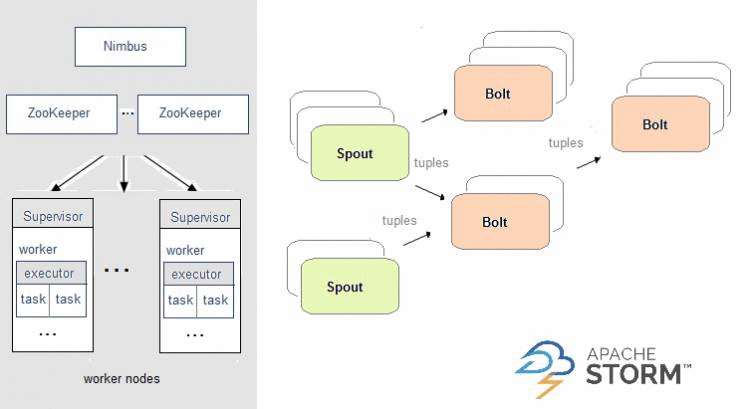
在风暴 ,你设计要求的T opology实时计算的图,然后喂到集群,其中主节点将分发工作节点来执行它之间的代码。 在拓扑中,数据在喷口之间传递, 喷口以不可变的键值对集(称为元组)的形式发射数据流,而螺栓则转换这些流(计数,过滤器等)。 螺栓本身可以选择将数据发送到处理管道中的其他螺栓。
阿帕奇火花
Spark Streaming (Spark API的核心扩展)不会像Storm那样一次处理流。 相反,它将在处理它们之前将它们切成小批时间间隔。 连续数据流的Spark抽象称为DStream (对于离散流 )。 DStream是RDD ( 弹性分布式数据集 )的微型批次。 RDD是分布式集合,可以通过任意功能和数据滑动窗口上的转换( 窗口计算 )并行操作。

阿帕奇·萨姆扎(Apache Samza)
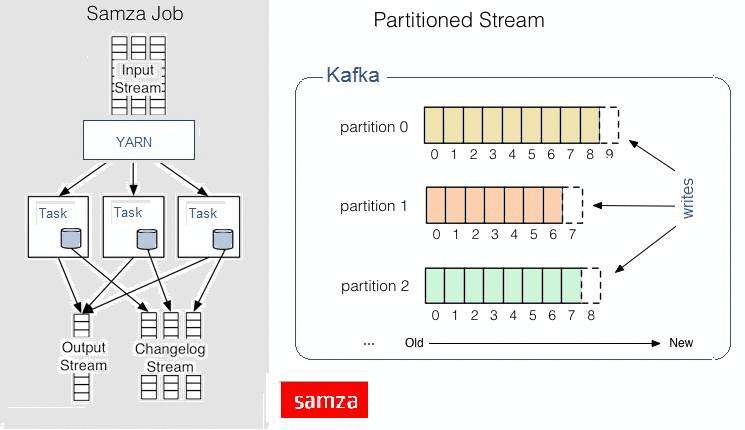
Samza的流式传输方法是在收到消息时一次处理一次。 Samza的流原语不是元组或Dstream ,而是消息 。 流被分成多个分区 ,每个分区都是只读消息的有序序列,每个消息具有唯一的ID( 偏移量 )。 该系统还支持批处理 ,即按顺序使用来自同一流分区的多个消息。 尽管Samza通常依赖于Hadoop的YARN ( 另一个资源协商者 )和Apache Kafka ,但Samza的执行和流模块都可以插入。
共同点
所有这三个实时计算系统都是开源, 低延迟 , 分布式,可伸缩和容错的 。 它们都使您能够通过跨具有故障转移功能的计算机集群中分布的并行任务来运行流处理代码。 它们还提供了简单的API,以抽象出底层实现的复杂性。
这三个框架针对相似的概念使用不同的词汇表:
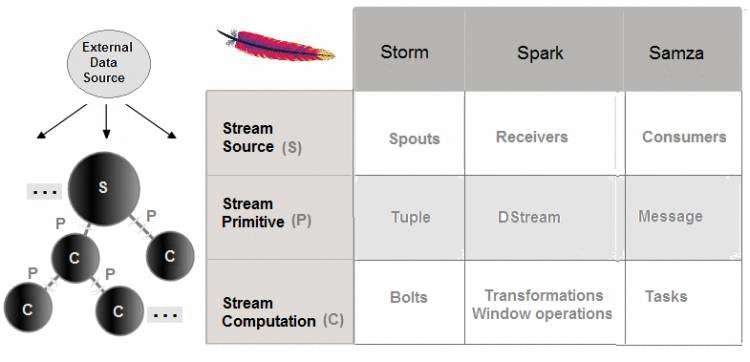
比较矩阵
下表总结了一些区别:

交付模式一般分为三类:
- 最多一次 :消息可能会丢失。 通常这是最不希望的结果。
- 至少一次 :可以重新发送邮件(不丢失,但重复)。 对于许多用例来说,这已经足够了。
- 恰好一次 :每封邮件仅发送一次,且一次(无损失,无重复)。 尽管很难在所有情况下都保证,但这是一个理想的功能。
另一方面是状态管理 。 存储状态有不同的策略。 Spark Streaming将数据写入分布式文件系统(例如HDFS)。 Samza使用嵌入式键值存储。 使用Storm,您将不得不在应用程序层滚动自己的状态管理,或者使用称为Trident的更高级别的抽象。
用例
这三个框架特别适合于有效处理连续的大量实时数据。 那么使用哪一个呢? 没有硬性规定,最多只有一些通用准则。
如果您想要一个允许增量计算的高速事件处理系统, Storm将会很合适。 如果您进一步需要按需运行分布式计算,而客户端正在同步等待结果,则可以直接使用分布式RPC (DRPC)。 最后但并非最不重要的一点,因为Storm使用Apache Thrift ,所以您可以用任何编程语言编写拓扑。 但是,如果您需要状态持久性和/或仅一次交付,则应查看更高级别的Trident API,该API还提供了微分批处理。
一些使用Storm的公司: Twitter,Yahoo!,Spotify,天气频道 。
说到微批处理,如果您必须有状态的计算,一次发送并且不介意更高的延迟,则可以考虑使用Spark Streaming……特别是如果您还计划进行图形操作,机器学习或SQL访问。 Apache Spark堆栈使您可以将多个库与流( Spark SQL , MLlib , GraphX )结合起来,并提供方便的统一编程模型。 特别是, 流算法 (例如,流k均值 )使Spark可以实时进行决策。

一些使用Spark的公司: Amazon,Yahoo!,NASA JPL,eBay Inc.,百度…
如果您要处理的状态很多(例如,每个分区有许多GB), Samza会将存储和处理放在同一台机器上,从而可以有效地处理内存中无法容纳的状态。 该框架还通过其可插拔 API提供了灵活性:默认执行,消息传递和存储引擎都可以用您选择的替代方案来代替。 此外,如果您有来自不同团队,具有不同代码库的多个数据处理阶段,则Samza的细粒度作业将特别适合,因为可以在添加或删除它们的同时将涟漪效应降至最低。
一些使用Samza的公司: LinkedIn,Intuit,Metamarkets,Quantiply,Fortscale…
结论
我们只刮过《三个阿帕奇人》的表面。 我们没有涵盖其他许多功能,以及这些框架之间的细微差别。 另外,重要的是要牢记上述比较的局限性,因为这些系统在不断发展。
翻译自: https://www.javacodegeeks.com/2015/02/streaming-big-data-storm-spark-samza.html



![R语言中向量(Vector)数据类型的元素索引与访问:利用中括号[]和赋值操作符在向量末尾追加数据以扩展其长度](https://img5.php1.cn/3cdc5/92e2/2be/c2a171af6e5eeb5a.png)



 京公网安备 11010802041100号
京公网安备 11010802041100号