作者:中青33期_840 | 来源:互联网 | 2023-09-05 08:45
首先要安装Scala, 然后再装spark
链接:https://pan.baidu.com/s/1ztL8u7tjm7t6Gm2yg-gWig
提取码:km7m
这里面是scala2.11.8和spark2.2.3
然而Scala又是在java虚拟环境下运行的,没装jvm的得先装
1.下载解压然后放到指定位置,打开gedit ~/.bashrc文件, 加路径进去
export SCALA_HOME=/home/hadoop/scala
export PATH=$SCALA_HOME/bin:$PATH
这个是基于用户的, 如果你想所有用户都用到的话,就把它放进
gedit /etc/profile下
然后source /etc/profile一下
再然后输入scala -version有反应就说明成功了

然后开始装spark了, 也是先解压到指定的位置(你自己喜欢)
然后配置gedit ~/.bashrc
export SPARK_HOME=/home/hadoop/spark
export PATH=$SPARK_HOME/bin:$PATH
完了再scource ~/.bashrc
再进到cd spark/conf, 再 cp spark-env.sh.template spark-env.sh
然后加入到spark-env.sh文件下
export JAVA_HOME=/home/hadoop/java/jdk1.8.0_191
export SCALA_HOME=/home/hadoop/scala
export HADOOP_HOME=/home/hadoop/hadoop-2.7.6
export HADOOP_CONF_DIR=/home/hadoop/hadoop-2.7.6/etc/hadoop
export SPARK_MASTER_IP=hadoop1
export SPARK_MASTER_PORT=7077
# 还有一些其他配置项可以百度看看
现在就可以进入spark sbin/start-all.sh
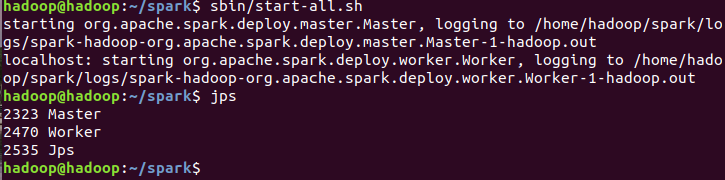
然后再去浏览器看看
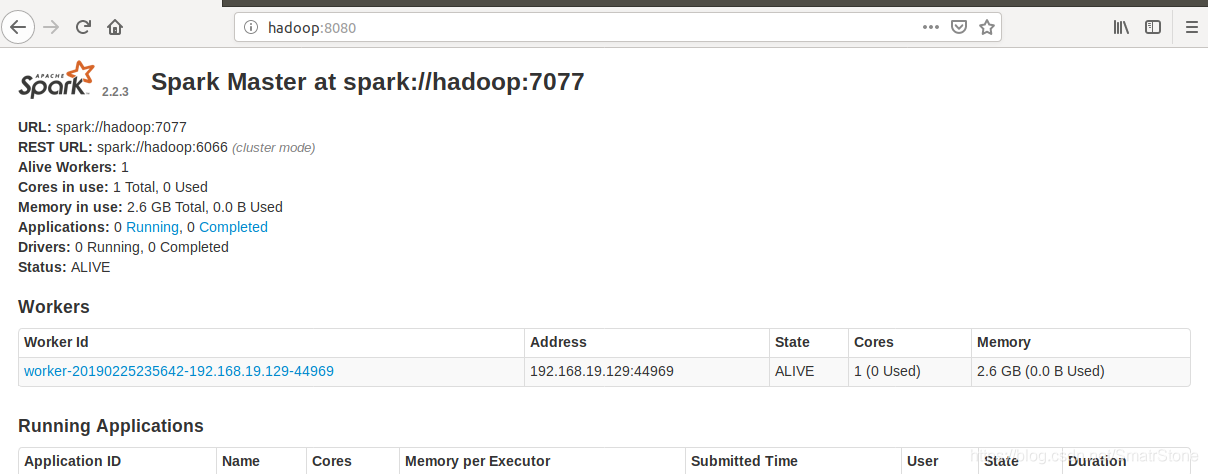
这样就成功了








 京公网安备 11010802041100号
京公网安备 11010802041100号