大家好,我是云祁,好久不见~
今天来和大家聊聊数仓常见的一些建模方法和具体的实例演示,一起来看看吧。
一、为什么需要数据建模?
在开始今天的话题之前,我们不妨思考下,到底为什么需要进行数据建模?
随着从IT时代到DT时代的跨越,数据开始出现爆发式的增长,这当中产生的价值也是不言而喻。如何将这些数据进行有序、有结构地分类组织存储,是我们所有数据从业者都要面临的一个挑战。
如果把数据看作图书馆里的书,我们希望看到它们在书架上分门别类地放置,而不是乱糟糟的堆砌在一起。
大数据的数仓建模正是通过建模的方法,更好的组织、存储数据,以便在性能、成本、效率和数据质量之间找到最佳平衡点,一般我们会从以下面四点考虑:
- 性能:能够快速查询所需的数据,减少数据I/O的吞吐。
- 成本:减少不必要的数据冗余,实现计算结果的复用,降低大数据系统中的存储成本和计算成本。
- 效率:改善用使用数据的体验,提高使用效率。
- 质量:改善数据统计口径的不一致性,减少数据计算错误的可能性,提供高质量的、一致的数据访问平台。
因此,毋庸置疑,大数据系统、数据平台都需要数据模型方法来帮助更好的组织和存储数据,数据建模的工作,也正是围绕上述四个指标取得最佳的平衡而努力。
二、从 OLTP 和 OLAP 系统的区别看模型方法论的选择
OLTP系统通常面向的主要数据操作是随机读写,主要采用3NF的实体关系模型存储数据,从而在事务处理中解决数据的冗余和一致性问题。
OLAP系统面向的主要数据操作是批量读写,事务处理中的一致性不是OLAP所关注的,其主要关注数据的整合,以及在一次性的复杂大数据查询和处理的性能,因此它需要采用不同的建模方法,例如维度建模。
如果大家想进一步了解 OLAP系统,可以学习这篇文章: 关于OLAP数仓,这大概是史上最全面的总结!
三、典型的数据仓库建模方法论
数据仓库本质是从数据库衍生出来的,所以数据仓库的建模也是不断衍生发展的。
从最早的借鉴关系型数据库理论的范式建模,到逐渐提出维度建模等等,越往后建模的要求越高,越需满足3NF、4NF等。但是对于数据仓库来说,目前主流还是维度建模,会夹杂着范式建模。
数据仓库建模方法论可分为:E-R模型、维度模型、Data Vault模型、Anchor模型。
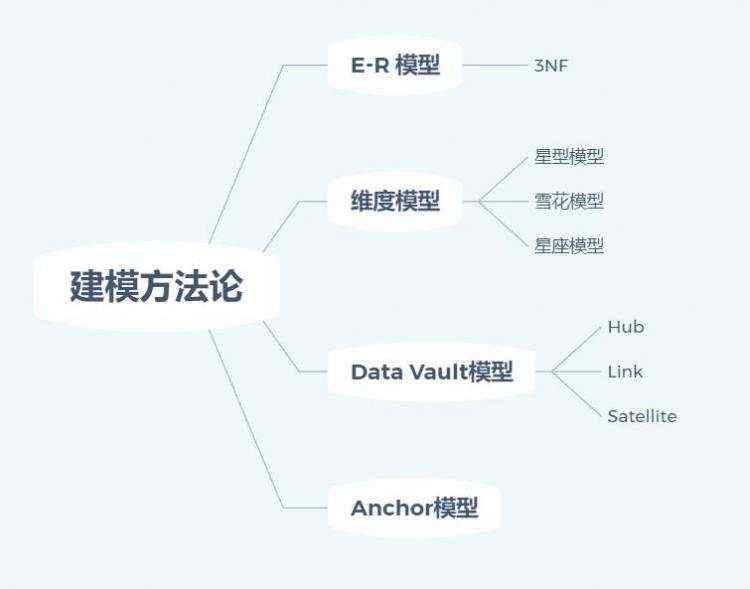
3.1 E-R模型
将事物抽象为“实体”、“属性”、“关系”来表示数据关联和事物描述,这种对数据的抽象建模通常被称为E-R实体关系模型。
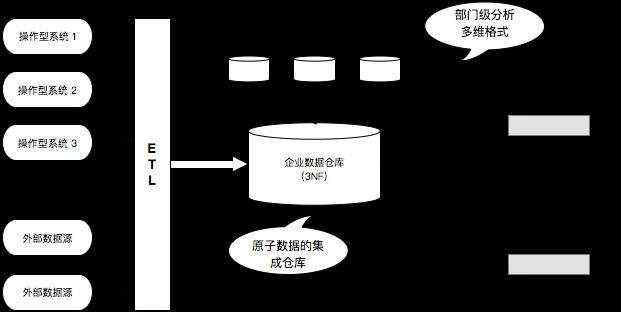
数据仓库之父 Bill Inmon 提出的建模方法,从全企业的高度设计一个3NF模型,用实体关系(Entity Relationship)模型来描述企业业务,满足3NF。
数据仓库的3NF与OLTP系统中的3NF的区别在于,它是站在企业角度面向主题的抽象,而不是针对某个具体的业务流程。
采用 E-R模型建设数据仓库模型的出发点是整合数据,对各个系统的数据以整个企业角度按主题进行相似的组合和合并,并进行一致性处理,为数据分析决策服务,但是并不能直接用于分析决策。
作为一种标准的数据建模方案,它的实施周期非常长,一致性和扩展性比较好,能经得起时间的考验。但是随着企业数据的高速增长、复杂化,数仓如果全部使用E-R模型进行建模就显得越来越不适合现代化复杂、多变的业务组织,因此一般只有在数仓底层ODS、DWD会采用E-R关系模型进行设计。
E-R建模步骤分为三个阶段:
- 高层模型:一个高度抽象的模型,描述主要的主题以及主题间的关系,用于描述企业的业务总体概况。
- 中层模型:在高层模型的基础上,细化主题的数据项。
- 物理模型(底层模型):在中层模型的基础上,考虑物理存储,同时基于性能和平台特点进行物理属性的设计,也可能做一些表的合并、分区的设计等。
E-R模型在实践中最典型的代表是 Teradata 公司基于金融业务发布的 FS-LDM (Financial Services Logical Data Model ),它通过对金融业务的高度抽象和总结,将金融业务划分为10大主题,企业基于此模型适当调整和扩展就能快速实施落地。
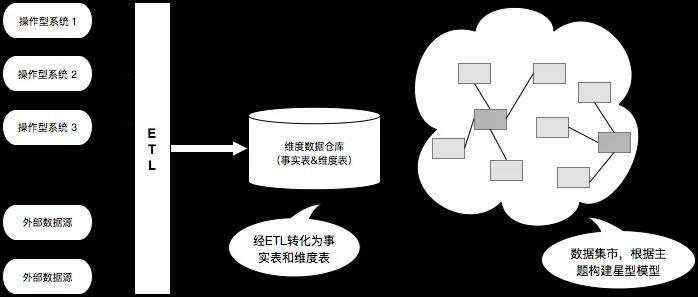
3.2 维度模型
维度模型是数据仓库领域 Ralph Kimball 大师倡导的,是数据仓库工程领域最流行的数仓建模经典。
维度建模以分析决策的需求出发构建模型,构建的数据模型为分析需求服务,因此它重点解决用户如何更快速完成分析需求,同时还有较好的大规模复杂查询的响应性能。
其中典型的代表就是使用星型模型,以及在一些特殊场景下使用的雪花模型。
其设计主要分为以下几个步骤:
- 选择需要进行分析决策的业务过程。业务过程可以是单个业务事件,比如交易的支付、退款等;也可以是某个事件的状态,比如当前账户的余额;还有就是一系列相关业务事件组成的业务流程,具体需要我们分析的是某些事件发生的情况,还是当前状态,或是事件流转效率。
- 选择粒度。在事件分析中,我们要预判所有分析需要细分的程度,从而决定选择的粒度。粒度是维度的一个组合。
- 识别维表。选择好粒度之后,就需要基于这个粒度来设计维表,包括维度属性,用于分析时进行分组和筛选。
- 选择事实。确定分析需要衡量的指标。
在 Ralph Kimball 提出对数据仓库维度建模,我们将数据仓库中的表划分为事实表、维度表两种类型。
针对维度建模中事实表和维度表的设计,之前有详细介绍过,感兴趣的同学可以看:维度建模技术实践——深入事实表 、维度建模的灵魂所在——维度表设计。
在这里,我就以常见的电商场景为例:在一次购买的事件中,涉及主体包括客户、商品、商家,产生的可度量值会包括商品数量、金额、件数等。
事实表根据粒度的角色划分不同,可分为事务事实表、周期快照事实表、累积快照事实表等。
- 事务事实表:用于承载事务数据,任何类型的事件都可以被理解为一种事务,比如商家在交易过程中的常见订单、买家付款,物流过程中的揽货、发货、签收,退款中的申请退款。
- 周期快照事实表:快照事实表以预定的间隔采样状态度量,比如自然年至今或者历史至今的下单金额、支付金额、支付买家数、支付商品件数等等状态度量。
- 累计快照事实表:数据不断更新,选取多业务过程日期。用来记录具有时间跨度的业务处理过程的整个过程的信息,每个生命周期一行,通常这类事实表比较少见。
我们继续就上述的电商场景,聊聊在维表设计时需要关注的一些东西:
- 缓慢变化维度:例如会员表的手机号、地址、生日等属性。
- 退化维度 :订货单表的订单编号、物流表的物流编号等。
- 雪花维度:满足第三范式的维度关系结构。
- 非规范化扁平维度:商品维表众中产品、品牌、类目、品类等。
- 多层次维度:地区维度的省、市、区县,商品的类目层级。
- 角色维度:日期维度在物流中扮演发货日期、送货日期、收获日期等不同角色。
接下来就是针对维度建模按照数据的组织类型,可以划分为星型模型、雪花模型、星座模型。
- 星型模型:星型模型主要是维表和事实表,以事实表为中心,所有维度直接关联在事实表上,呈星型分布。
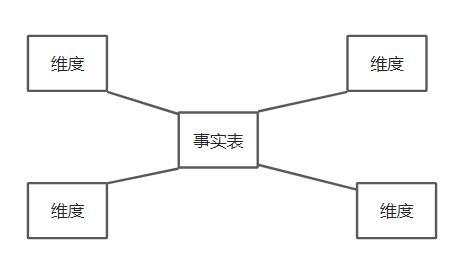
2. 雪花模型,在星型模型的基础上,维度表上又关联了其他维度表。这种模型维护成本高,性能方面会差一些。
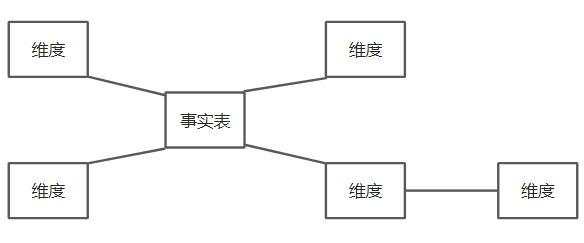
3. 星座模型,是对星型模型的扩展延伸,多张事实表共享维度表。实际上数仓模型建设后期,大部分维度建模都是星座模型。
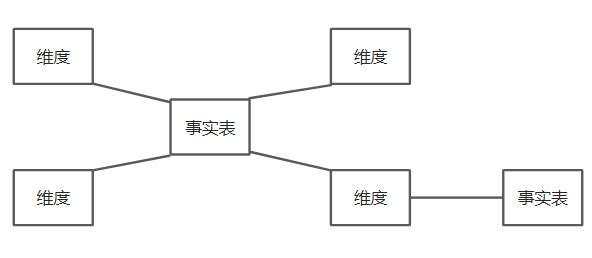
简单总结下就是:
- 星型模型和雪花模型主要区别就是对维度表的拆分。
- 对于雪花模型,维度表的涉及更加规范,一般符合3NF,有效降低数据冗余,维度表之间不会相互关联。
- 星型模型,一般采用降维的操作,反规范化,不符合3NF,通过利用冗余来避免模型过于复杂,提高易用性和分析效率,效率相对较高。
3.3 DataVault 模型
Data Vault 是 Dan Linstedt 发起创建的一种模型,它是 E-R 模型的衍生,其设计的出发点也是为了实现数据的整合,但不能直接用于数据分析决策。
它强调建立一个可审计的基础数据层,也就是强调数据的历史性、可追溯性和原子性,而不要求对数据进行过度的一致性处理和整合。
同时它基于主题概念将企业数据进行结构化组织,并引入了更进一步的范式处理来优化模型,以应对源系统变更的扩展性。 Data Vault 型由以下几部分组成:
- Hub - 中心表:是企业的核心业务实体,由实体 Key、数仓序列代理键、装载时间、数据来源组成,不包含非键值以外的业务数据属性本身。
- Link - 链接表:代表 Hub 之间的关系。这里与 ER 模型最大的区别是将关系作为一个独立的单元抽象,可以提升模型的扩展性。它可以直接描述 1:1、1:2和n:n的关系,而不需要做任何变更。它由 Hub的代理键、装载时间、数据来源组成。
- Satellite - 卫星表:数仓中数据的主要载体,包括对链接表、中心表的数据描述、数值度量等信息。
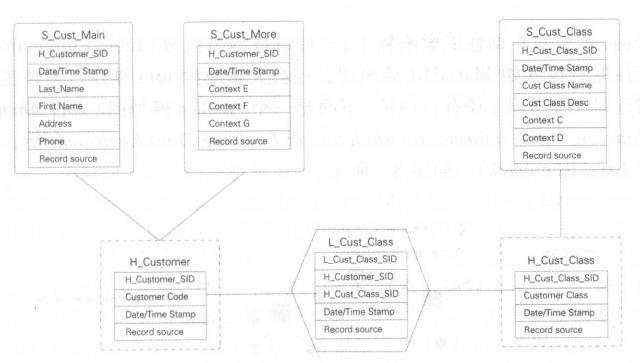
Data Vault 模型比 E-R 模型更容易设计和产出,它的 ETL 加工可实现配置化。我们可以将 Hub 想象成人的骨架,那么 Link 就是连接骨架的韧带,而 SateIIite 就是骨架上面的血肉。
3.4 Anchor 模型
Anchor 对 Data Vault 模型做了进一步的规范化处理,它的核心思想是所有的扩展只是添加而不是修改,因此将模型规范到6NF,基本变成了 k-v 结构化模型。
- Anchors :类似于 Data Vault 的 Hub ,代表业务实体,且只有主键。
- Attributes :功能类似于 Data Vault 的 Satellite,但是它更加规范化,将其全部 k-v 结构化, 一个表只有一个 Anchors 的属性描述。
- Ties :就是 Anchors 之间的关系,单独用表来描述,类似于 Data Vault 的 Link ,可以提升整体模型关系的扩展能力。
- Knots :代表那些可能会在 Anchors 中公用的属性的提炼,比如性别、状态等这种枚举类型且被公用的属性。
由于过度规范化,使用中牵涉到太多的Join操作,这里我们就仅作了解。
四、总结
以上为四种基本的建模方法,目前主流建模方法为: E-R模型、维度模型。
E-R模型通常用于OLTP数据库建模,应用到构建数仓时就更偏向于数据整合,站在企业整体考虑,将各个系统的数据按相似性一致性、合并处理,为数据分析、决策服务,但并不便于直接用来支持分析。
维度建模是面向分析场景而生,针对分析场景构建数仓模型;重点关注快速、灵活的解决分析需求,同时能够提供大规模数据的快速响应性能。针对性强,主要应用于数据仓库构建和OLAP引擎低层数据模型。
数据仓库模型的设计是灵活的,不会局限于某一种模型,需要以实际的需求场景为导向,需要兼顾灵活性、可扩展性以及技术可靠性及实现成本。
我是「云祁」,一枚热爱技术、会写诗的大数据开发猿,欢迎大家关注呀!
Respect ~






 京公网安备 11010802041100号
京公网安备 11010802041100号