项目中会时不时遇到展示pdf文件的需求,比如需要展示某些合同或者一些PPT报告之类的。我们在做《娱乐宝》、《票票专业版》项目期间都遇到了这样的需求。针对如何展现pdf文件的内容,一般无外乎以下几种方案:
而这几种方案在实际操作过程中又分别有各自的问题,我们首先讨论第一种方案。让客户端渲染PDF有两种方式:1. 借助系统已有的功能,比如webbiew。2. 利用开源的pdf渲染库。iOS中webview自带了pdf渲染功能,同时支持缩放等操作,体验相当好,但安卓不支持,需要自己开发实现。而第三方PDF渲染库普遍比较大,一般都要好几兆,为了这样一个非核心功能引入这么大一个库,客户端同学是坚决不会答应的。第二种方案初看起来不错,至少省去了客户端兼容的成本。调研了下JS渲染PDF方面的实现,比较著名的是Mozzila的pdf.js。但这个库也有一些问题:
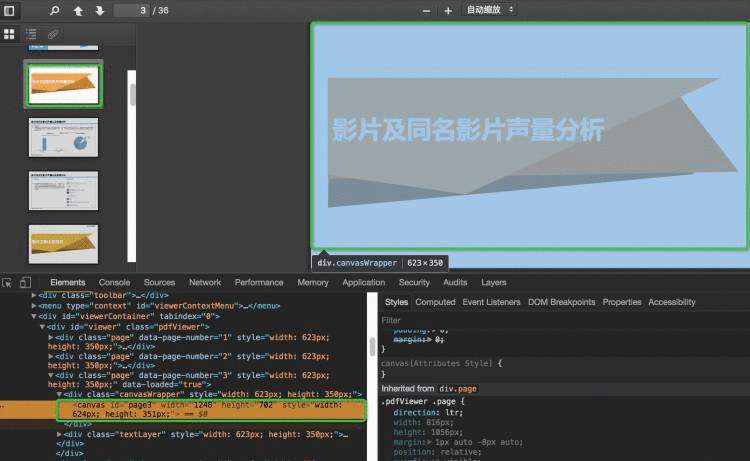
前两个问题通过一些技术手段还能绕过去,但后两个几乎无解了,尤其是用canvas渲染图片。canvas在移动端太耗性能了,Canvas太多的话会造成浏览器渲染性能严重下降,iphone下甚至会导致APP崩溃。采用Canvas渲染图片的证据。
不同字体设置导致渲染结果不一致的问题:
此外在测试过程中还发现:那个库提供的Demo页面在UC下打开且打开的PDF文件比较大的情况下,多翻几页之后会出现页面加载不出来的情况,因此这个库在H5下的兼容问题堪忧。 因此采用JS库渲染PDF目前来看不太适合应用在H5项目中,在PC项目中还可以考虑下。
经过排除后目前只剩下将PDF转换为图片然后用H5来渲染这一方案了,至于此方案的具体实现,可以参照之前发布的一篇文章《一个简单H5活动页面模板的设计》。这个方案比较简单可靠,但面临一个很烦人的问题:需要将PDF的每一页转换为图片然后拼接为长图。如果这个过程需要人工来完成将是非常繁琐的,而如果文件比较大的话那简直是噩梦了,因此这个过程是必须由程序自动来完成的。
如果由程序完成将PDF转换为长图,必须要实现两个功能:
还好这两个功能都有相应的软件支持,而且这两个软件的命令行支持都非常好,而且都支持brew进行安装。将PDF转换为图片最著名的库莫过于GhostScript,在项目中我们也选用了这个库。将PDF的每一页转换为图片可以通过下面的命令来实现
gs -sDEVICE=pngalpha \ # 输出格式为png-o "./tmp-pdf-page/$filename-%d.png" \ # 设置每一页对应图片的名称-r144 "$pdfname"; # 设置每英寸内的像素数
将多张图片拼合为一张有多种软件可以实现,比较有名的是ImageMagick和GraphicsMagick。ImageMagick资历最老,文档最全,支持的特性最多,但运行起来比较缓慢。GraphicsMagick脱胎于ImageMagick 5.x,支持的特性比较少,命令格式几乎与ImageMagick通用,运行速度飞快,但文档非常少,而且有些特性不支持(本文后面程序中所使用的切功能:shave在测试时没有调试通过)。考虑到这个功能无论在本机还是服务端调用都不是很频繁,因此我们使用了ImageMagick。下面的代码可以实现将多张图片拼接为一张长图,为了输出的图片更加美观,图片之间添加了一定的白色空白。
convert ./tmp-pdf-page/$filename-*.png \-background white \-bordercolor white \ # 设置图片边框颜色-border 0x50 \ # 图片上下添加50像素边框 ,因此图片之间有100px的边框-append \ # 图片直接垂直拼接,如果水平拼接可用+append-shave 0x50 \ # 删除合并后图片的上下边框,GraphicsMagick不支持此操作-resize 1080 \ # 将拼接后的图片宽度调整为1080-quality 85 \ # 设置输出的JPG图片质量-sharpen 0x1.0 \ # 拼接后的图片字体有点发虚,在垂直方向做锐化处理 $filename-dest.jpg
有一点需要说明下,安装GhostScript后,ImageMagick内部可以直接调用GhostScript实现将PDF转换为长图,具体实现可以参考如下:
convert demo.pdf \-resize 620 \ # 设置每张图片尺寸-alpha remove \ -density 620 \ # 设置分辨率,按文档应该越高越好 -mattecolor '#cccccc' \ # 设置间隔颜色,作用与上面代码中的border相同-frame 10x5 \ # 设置图片间隔宽度-append \-quality 85 \-frame 0x5 \-sharpen 0x1.0 \demo.jpg
这段代码省去了第一步利用GhostScript将PDF转换为多张图片的步骤,但效果不是很理想,无论怎么设置分辨率(density)和JPG质量(quality),转换出来的图片都有点糊,因此实际项目中我们使用了分开处理的方案。
因为操作比较多,我们写了个bash脚本对这些逻辑做封装,使用方式为:bash convert.sh demo.pdf,脚本完整代码如下:
bash convert.sh demo.pdf
#!/bin/bash## 计算pdf文件名,参考资料:# http://www.runoob.com/linux/linux-shell-variable.html# https://stackoverflow.com/questions/965053/extract-filename-and-extension-in-bash/965072# https://stackoverflow.com/questions/965053/extract-filename-and-extension-in-bash# https://stackoverflow.com/questions/3362920/get-just-the-filename-from-a-path-in-a-bash-script# pdfname=$1filename="${pdfname%%.*}"## 创建临时文件夹存储每张pdf页面对应的图片mkdir tmp-pdf-page## 将pdf转换为多张pnggs -sDEVICE=pngalpha -o "./tmp-pdf-page/$filename-%d.png" -r144 "$pdfname";## 将多张图片合并为一张,每张图片直接添加50像素间隔,最后# 将图片尺寸设置1080宽度后裁掉第一张和最后一张的边框,并# 进行锐化处理后输出为jpg。# 参考资料:# http://www.imagemagick.org/Usage/crop/#border# http://www.imagemagick.org/Usage/crop/#frameconvert ./tmp-pdf-page/$filename-*.png \-background white \-bordercolor white \-border 0x50 \-append \-shave 0x50 \-resize 1080 \-quality 85 \-sharpen 0x1.0 \$filename-dest.jpg## 删除单张pdf文件对应的图片rm -rf ./tmp-pdf-page
转换后图片在线上的实际效果
答案是可以,这一方案依赖的两个软件:ImageMagick和GhostScript在Linux和Mac下均有提供,所以可以无缝移植的服务端。最早做这个方案的研究是在一年多以前,当时在做《娱乐宝》项目,每个项目上线都要上传合同,所以把生成图片并上传CDN的功能做到了小二后台中。当时是直接利用ImageMagick将PDF转换为长图的功能,没有使用先用GhostScript转换为多图然后再用ImageMagick拼接的方案。当时的效果不是很理想,文字总是比较糊。但当时一来没有找到理想的解决方案,二来支付宝对于图片的大小有要求,所以就将就着用了。后来项目中又遇到了这个需求,所以花了些时间整理和优化了下,所以有了本文提到的这个方案。
移植到服务端没有问题,但有几点需要注意下:
目前这个方案还是不是特别理想,一个让人很不爽的地方是:因为每个pdf页面都需要生成一张图片,所以程序运行期间需要建立多个临时文件。我一向对临时文件深恶痛绝,因为临时文件不仅会凭空增加磁盘访问量,而且如果管理不好的话会造成垃圾文件越堆越多,而如果不巧这个程序运行在服务端那就有可能把磁盘都占满了。在写此文之前,我曾尝试了多个方法把这个临时文件干掉,但最终都不是很理想。
首先GhostScript提供将结果输出到标准IO的功能,但ImageMagick的append功能无法支持从标准IO读取多张图片文件,因此此方案行不通。GraphicsMagick也不支持从命令行读取多张方案,但gm与GhostScript协同调用的效果比ImageMagick的效果要好,转换后的效果与本文中用两部实现的效果相当,但需要自己手动计算PDF页数,而且因为不支持-shave参数,需要自己手动对最后转换后的图片进行必要的裁切。我们的使用场景主要是开发本机调用,开发时间所限,没有对GraphicsMagick方案进行进一步调研。如果是部署到服务端,建议使用GraphicsMagick,不仅效率高而且不会产生临时文件,GraphicsMagick直接将PDF转换为长图的代码:
gm convert -density 1080 \-mattecolor red \-frame 0x50 \-append \-shave 0x50 \ # 裁剪功能在GM下没有生效,不知是否是使用不当还是这种情况下不支持。-resize 1080 \ -quality 85 \test.pdf[1-4] \ # 这里需要手动制定要转换的页码范围test-tmp.jpg









 京公网安备 11010802041100号
京公网安备 11010802041100号