本文主要分享【人工智能的深度学习】,技术文章【李沐动手学深度学习V2-BERT预训练和代码实现】为【cv_lhp】投稿,如果你遇到李沐动手学深度学习笔记相关问题,本文相关知识或能到你。
利用 李沐动手学深度学习V2-bert和代码实现中实现的BERT模型和 李沐动手学深度学习V2-bert预训练数据集和代码实现中从WikiText-2数据集生成的预训练样本,下面在WikiText-2数据集上对BERT进行预训练。
首先,加载WikiText-2数据集作为小批量的预训练样本,用于遮蔽语言模型和下一句预测。批量大小是512,BERT输入序列的最大长度是64。注意在原始BERT模型中,最大长度是512。
import torch
import d2l.torch
from torch import nn
batch_size,max_len = 512,64
train_iter,vocab = d2l.torch.load_data_wiki(batch_size,max_len)
原始BERT 有两个不同模型尺寸的版本。基本模型( BERTBASE )使用12层(Transformer编码器块),768个隐藏单元(隐藏大小)和12个自注意头。大模型( BERTLARGE )使用24层,1024个隐藏单元和16个自注意头。值得注意的是,前者有1.1亿个参数,后者有3.4亿个参数。下面定义了一个小的BERT,使用了2层、128个隐藏单元和2个自注意头。
net = d2l.torch.BERTModel(len(vocab),num_hiddens=128,norm_shape=[128],ffn_num_input=128,ffn_num_hiddens=256,num_heads=2,num_layers=2,dropout=0.2,key_size=128,query_size=128,value_size=128,hid_in_features=128,mlm_in_features=128,nsp_in_features=128)
devices = d2l.torch.try_all_gpus()[0:2]
loss = nn.CrossEntropyLoss(reduction='none')#注意此处不用对loss求和
在定义训练代码实现之前,定义了一个辅助函数_get_batch_loss_bert。给定训练样本,该函数计算遮蔽语言模型和下一句子预测任务的损失。注意BERT预训练的最终损失是遮蔽语言模型损失和下一句预测损失的和。
#计算一个batch的前向传播的损失loss
def _get_batch_loss_bert(net,loss,vocab_size,tokens_X,segments_X,valid_lens_X,mlm_pred_positions_X,mlm_weights_X,mlm_pred_positions_Y,nsp_Y):
# 前向传播
_,mlm_pred_positions_Y_hat,nsp_Y_hat = net(tokens_X,segments_X,valid_lens_X,mlm_pred_positions_X)
# mlm_loss = loss(mlm_pred_positions_Y_hat.reshape(-1,vocab_size),mlm_pred_positions_Y.reshape(-1))*mlm_weights_X.reshape(-1,1)
# 计算遮蔽语言模型损失
m_l = loss(mlm_pred_positions_Y_hat.reshape(-1, vocab_size), mlm_pred_positions_Y.reshape(-1))
mlm_l = torch.matmul(m_l,mlm_weights_X.reshape(-1))#两个都是一维向量,向量点乘
# mlm_l = mlm_l.sum() / (mlm_weights_X.sum() + 1e-8)
mlm_loss = mlm_l.sum()/(mlm_weights_X.sum()+1e-8) #求一个batch的均值mlm loss:代表预测的每个词元的平均loss
# 计算下一句子预测任务的损失
nsp_loss = loss(nsp_Y_hat,nsp_Y)
nsp_loss = nsp_loss.sum()/len(nsp_loss) #求一个batch的均值nsp loss:代表预测每个序列对的平均loss
batch_total_loss = mlm_loss+nsp_loss
return mlm_loss,nsp_loss,batch_total_loss
通过调用上述两个辅助函数,下面的train_bert函数定义了在WikiText-2(train_iter)数据集上预训练BERT(net)的过程。训练BERT可能需要很长时间。以下函数的输入num_steps指定了训练的迭代步数,而不是像train_ch13函数那样指定训练的轮数。
def train_bert(train_iter,net,loss,vocab_size,devices,num_steps):
net = nn.DataParallel(module=net,device_ids=devices).to(devices[0])
optim = torch.optim.Adam(params=net.parameters(),lr=3e-3)
step = 0
# 遮蔽语言模型损失的和,下一句预测任务损失的和,句子对的数量,计数
accumulator = d2l.torch.Accumulator(4)
animator = d2l.torch.Animator(xlabel='step',ylabel='loss',xlim=[1,num_steps],legend=['mlm_loss','nsp_loss'])
timer = d2l.torch.Timer()
num_steps_reached = False
while step<num_steps and not num_steps_reached:
for (tokens_X,segments_X,valid_lens_X,mlm_pred_positions_X,mlm_weights_X,mlm_pred_positions_Y,nsp_Y) in train_iter:
tokens_X = tokens_X.to(devices[0])
segments_X = segments_X.to(devices[0])
valid_lens_X = valid_lens_X.to(devices[0])
mlm_pred_positions_X = mlm_pred_positions_X.to(devices[0])
mlm_weights_X = mlm_weights_X.to(devices[0])
mlm_pred_positions_Y = mlm_pred_positions_Y.to(devices[0])
nsp_Y = nsp_Y.to(devices[0])
optim.zero_grad()
timer.start()
mlm_loss,nsp_loss,l = _get_batch_loss_bert(net,loss,vocab_size,tokens_X,segments_X,valid_lens_X,mlm_pred_positions_X,mlm_weights_X,mlm_pred_positions_Y,nsp_Y)
l.backward()
optim.step()
accumulator.add(mlm_loss,nsp_loss,tokens_X.shape[0],1)
timer.stop()
animator.add(step+1,(accumulator[0]/accumulator[3],accumulator[1]/accumulator[3]))
step+=1
if step == num_steps :
num_steps_reached = True
break
print('mlm_loss:',accumulator[0]/accumulator[3],'\nnsp_loss:',accumulator[1]/accumulator[3],'\n',accumulator[2]/timer.sum(),'sentence pairs/s on',devices)
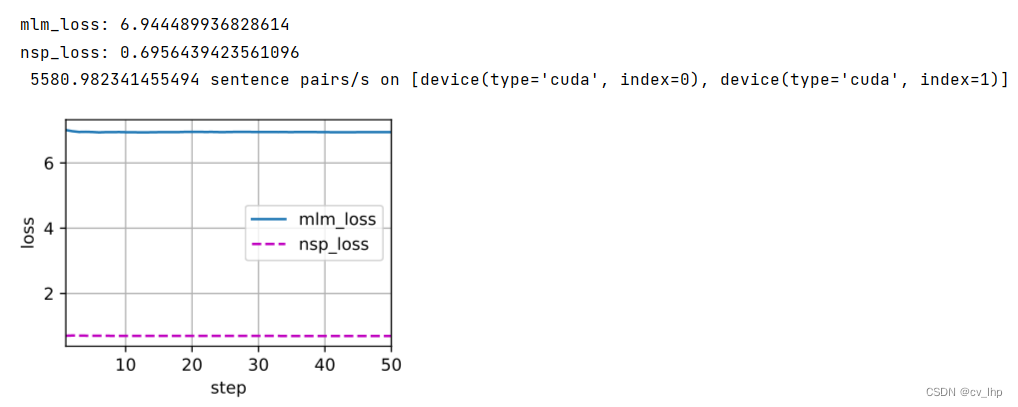
在预训练过程中,绘制出遮蔽语言模型损失和下一句预测损失,如下图所示。
(在下面实验中,可以看到遮蔽语言模型损失明显高于下一句预测损失,为什么?crossentropy的原因,log在[0,1]之间变化很大,从而导致遮蔽语言模型损失明显高于下一句预测损失,因为mlm预测出来的特征有len(vocab_size)这么大,导致每一个特征维概率数值比较小,而nsp预测出来的特征只有两个,因此每个特征维概率数值比较大,从而经过log,再添加一个负号取反,从而导致nsp预测出来的loss比较小)
在预训练BERT之后,可以用它来表示单个文本、文本对或其中的任何词元。下面的函数返回tokens_a和tokens_b中所有词元的BERT(net)表示。
def get_bert_encoding(net,tokens_a,tokens_b=None):
tokens,segments = d2l.torch.get_tokens_and_segments(tokens_a,tokens_b)
tokens_ids = torch.tensor(vocab[tokens],device=devices[0]).unsqueeze(0)
segments = torch.tensor(segments,device=devices[0]).unsqueeze(0)
valid_len = torch.tensor(len(tokens),device=devices[0]).unsqueeze(0)
encoded_X,_,_ = net(tokens_ids,segments,valid_len)
return encoded_X
考虑“a crane is flying”这句话,进行BERT的输入表示。插入特殊标记“”(用于分类)和“”(用于分隔)后,BERT输入序列的长度为6。因为零是“”词元,encoded_text[:, 0, :]是整个输入语句的BERT表示。为了评估一词多义词元“crane”,我们还打印出了该词元的BERT表示的前三个元素。
tokens_a = ['a','crane','is','flying']
encoded_text = get_bert_encoding(net,tokens_a)
# 词元:'
','a','crane','is','flying','
'
encoded_text_cls = encoded_text[:,0,:]
encoded_text_crane = encoded_text[:,2,:]
encoded_text.shape,encoded_text_cls.shape,encoded_text_crane[0,:3]
输出结果如下:
(torch.Size([1, 6, 128]),
torch.Size([1, 128]),
tensor([-0.0458, -0.8055, -0.3796], device='cuda:0', grad_fn=<SliceBackward0>))
考虑一个句子“a crane driver came”和“he just left”。类似地encoded_pair[:, 0, :]是来自预训练BERT的整个句子对的编码结果。注意多义词元“crane”与上下文不同时经过BERT输出表示后的前三个元素也会不同,这支持了BERT表示是上下文敏感的。
tokens_a, tokens_b = ['a', 'crane', 'driver', 'came'], ['he', 'just', 'left']
encoded_pair = get_bert_encoding(net,tokens_a,tokens_b)
encoded_pair_cls = encoded_pair[:,0,:]
encoded_pair_crane = encoded_pair[:,2,:]
encoded_pair.shape,encoded_pair_cls.shape,encoded_text_crane[0,:3]
输出结果如下:
(torch.Size([1, 10, 128]),
torch.Size([1, 128]),
tensor([-1.1288, 0.2452, -0.3381], device='cuda:0', grad_fn=<SliceBackward0>))
import torch
import d2l.torch
from torch import nn
batch_size, max_len = 512, 64
train_iter, vocab = d2l.torch.load_data_wiki(batch_size, max_len)
net = d2l.torch.BERTModel(len(vocab), num_hiddens=128, norm_shape=[128], ffn_num_input=128, ffn_num_hiddens=256,
num_heads=2, num_layers=2, dropout=0.2, key_size=128, query_size=128, value_size=128,
hid_in_features=128, mlm_in_features=128, nsp_in_features=128)
devices = d2l.torch.try_all_gpus()[0:2]
loss = nn.CrossEntropyLoss(reduction='none')
#计算一个batch的前向传播的损失loss
def _get_batch_loss_bert(net, loss, vocab_size, tokens_X, segments_X, valid_lens_X, mlm_pred_positions_X, mlm_weights_X,
mlm_pred_positions_Y, nsp_Y):
# 前向传播
_, mlm_pred_positions_Y_hat, nsp_Y_hat = net(tokens_X, segments_X, valid_lens_X, mlm_pred_positions_X)
# mlm_loss = loss(mlm_pred_positions_Y_hat.reshape(-1,vocab_size),mlm_pred_positions_Y.reshape(-1))*mlm_weights_X.reshape(-1,1)
# 计算遮蔽语言模型损失
m_l = loss(mlm_pred_positions_Y_hat.reshape(-1, vocab_size), mlm_pred_positions_Y.reshape(-1))
mlm_l = torch.matmul(m_l, mlm_weights_X.reshape(-1)) #两个都是一维向量,向量点乘
# mlm_l = mlm_l.sum() / (mlm_weights_X.sum() + 1e-8)
mlm_loss = mlm_l.sum() / (mlm_weights_X.sum() + 1e-8) #求一个batch的均值mlm loss:代表预测的每个词元的平均loss
# 计算下一句子预测任务的损失
nsp_loss = loss(nsp_Y_hat, nsp_Y)
nsp_loss = nsp_loss.sum() / len(nsp_loss) #求一个batch的均值nsp loss:代表预测每个序列对的平均loss
batch_total_loss = mlm_loss + nsp_loss
return mlm_loss, nsp_loss, batch_total_loss
def train_bert(train_iter, net, loss, vocab_size, devices, num_steps):
net = nn.DataParallel(module=net, device_ids=devices).to(devices[0])
optim = torch.optim.Adam(params=net.parameters(), lr=3e-3)
step = 0
# 遮蔽语言模型损失的和,下一句预测任务损失的和,句子对的数量,计数
accumulator = d2l.torch.Accumulator(4)
animator = d2l.torch.Animator(xlabel='step', ylabel='loss', xlim=[1, num_steps], legend=['mlm_loss', 'nsp_loss'])
timer = d2l.torch.Timer()
num_steps_reached = False
while step < num_steps and not num_steps_reached:
for (tokens_X, segments_X, valid_lens_X, mlm_pred_positions_X, mlm_weights_X, mlm_pred_positions_Y,
nsp_Y) in train_iter:
tokens_X = tokens_X.to(devices[0])
segments_X = segments_X.to(devices[0])
valid_lens_X = valid_lens_X.to(devices[0])
mlm_pred_positions_X = mlm_pred_positions_X.to(devices[0])
mlm_weights_X = mlm_weights_X.to(devices[0])
mlm_pred_positions_Y = mlm_pred_positions_Y.to(devices[0])
nsp_Y = nsp_Y.to(devices[0])
optim.zero_grad()
timer.start()
mlm_loss, nsp_loss, l = _get_batch_loss_bert(net, loss, vocab_size, tokens_X, segments_X, valid_lens_X,
mlm_pred_positions_X, mlm_weights_X, mlm_pred_positions_Y,
nsp_Y)
l.backward()
optim.step()
accumulator.add(mlm_loss, nsp_loss, tokens_X.shape[0], 1)
timer.stop()
animator.add(step + 1, (accumulator[0] / accumulator[3], accumulator[1] / accumulator[3]))
step += 1
if step == num_steps:
num_steps_reached = True
break
print('mlm_loss:', accumulator[0] / accumulator[3], '\nnsp_loss:', accumulator[1] / accumulator[3], '\n',
accumulator[2] / timer.sum(), 'sentence pairs/s on', devices)
train_bert(train_iter, net, loss, len(vocab), devices, num_steps=50)
def get_bert_encoding(net, tokens_a, tokens_b=None):
tokens, segments = d2l.torch.get_tokens_and_segments(tokens_a, tokens_b)
tokens_ids = torch.tensor(vocab[tokens], device=devices[0]).unsqueeze(0)
segments = torch.tensor(segments, device=devices[0]).unsqueeze(0)
valid_len = torch.tensor(len(tokens), device=devices[0]).unsqueeze(0)
encoded_X, _, _ = net(tokens_ids, segments, valid_len)
return encoded_X
tokens_a = ['a', 'crane', 'is', 'flying']
encoded_text = get_bert_encoding(net, tokens_a)
# 词元:'
','a','crane','is','flying','
'
encoded_text_cls = encoded_text[:, 0, :]
encoded_text_crane = encoded_text[:, 2, :]
encoded_text.shape, encoded_text_cls.shape, encoded_text_crane[0, :3]
tokens_a, tokens_b = ['a', 'crane', 'driver', 'came'], ['he', 'just', 'left']
encoded_pair = get_bert_encoding(net, tokens_a, tokens_b)
encoded_pair_cls = encoded_pair[:, 0, :]
encoded_pair_crane = encoded_pair[:, 2, :]
encoded_pair.shape, encoded_pair_cls.shape, encoded_text_crane[0, :3]
BERT预训练第一篇:李沐动手学深度学习V2-bert和代码实现
BERT预训练第二篇:李沐动手学深度学习V2-bert预训练数据集和代码实现
BERT预训练第三篇:李沐动手学深度学习V2-BERT预训练和代码实现
本文《李沐动手学深度学习V2-BERT预训练和代码实现》版权归cv_lhp所有,引用李沐动手学深度学习V2-BERT预训练和代码实现需遵循CC 4.0 BY-SA版权协议。








 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有