作者:Jack捷L | 来源:互联网 | 2023-06-21 12:11
开源syslog日志系统scribescribe官网https:github.comfacebookarchivescribe简介Scribe是facebook开源的日志收集系
开源 syslog 日志系统 scribe
scribe 官网
https://github.com/facebookarchive/scribe
简介
Scribe 是 facebook 开源的日志收集系统,在 facebook 内部已经得到大量的应用,目前在各大互联网公司内部已经得到大量的应用。
它能够从各种日志源上收集日志,存储到一个中央存储系统 (可以是 NFS,分布式文件系统等)上,以便于进行集中统计分析处理。它为日志的“分布式收集,统一处理”提供了一个可扩展的,高容错的方案。
它最重要的特点是容错性好。当中央存储系统的网络或者机器出现故障时,scribe 会将日志转存到本地或者另一个位置,当中央存储系统恢复后,scribe 会将转存的日志重新传输给中央存储系统。
其通常与 Hadoop 结合使用,scribe 用于向 HDFS 中 push 日志,而 Hadoop 通过 MapReduce 作业进行定期处理。
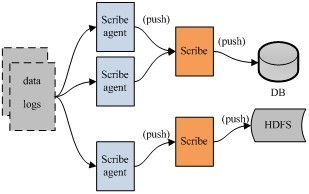
架构:
scribe 的架构比较简单,主要包括三部分,分别为 scribe agent, scribe 和 存储系统。
(1) scribe agent
scribe agent 实际上是一个 thrift client。 向 scribe 发送数据的唯一方法是使用 thrift client, scribe 内部定义了一个 thrift 接口,用户使用该接口将数据发送给 server。
(2) scribe
scribe 接收到 thrift client 发送过来的数据,根据配置文件,将不同 topic 的数据发送给不同的对象。scribe 提供了各种各样的 store,如 file, HDFS 等,scribe 可将数据加载到这些 store 中。
(3) 存储系统
存储系统实际上就是 scribe 中的 store,当前 scribe 支持非常多的 store,包括 file(文件),buffer(双层存储,一个主储存,一个副存储),network(另一个scribe服务器),bucket(包含多个 store,通过 hash 的将数据存到不同 store 中),null (忽略数据),thriftfile(写到一个 Thrift TFileTransport 文件中)和 multi(把数据同时存放到不同 store 中)。
【CentOS-7】
安装环境软件
sudo yum install git make bison libtool automake openssl-devel gcc-c++ python-devel# libevent,是一个用 C 语言编写的、轻量级的开源高性能事件通知库
# 安装 libevent libevent-devel
yum install libevent libevent-devel# flex,是一个生成词法分析器的工具,它可以利用正则表达式来生成匹配相应字符串的 C 语言代码。
# 安装 flex
yum install flex # 安装 byacc
yum install byacc # 安装 openjdk
yum install java-1.7.0-openjdk # 一个构建工具,它通过自动完成所有的编译代码,运行测试以及打包重新部署的结果等繁琐费力的任务来帮助软件团队开发大程序
# 安装 ant
yum install ant# Autoconf 是一个用于包,以适应多种 Unix 类系统的 shell 脚本的工具。
# 安装 autoconf
yum install autoconf# Boost是为C++语言标准库提供扩展的一些C++程序库的总称。
# 安装 boost
yum install boost boost-devel# libevent,是一个用 C 语言编写的、轻量级的开源高性能事件通知库
# 安装 libevent
yum install libevent# 安装 libicu-devel
yum install libicu-devel# 安装 thrift
wget http://rpmfind.net/linux/epel/7/x86_64/Packages/t/thrift-0.9.1-15.el7.x86_64.rpm
yum install thrift-0.9.1-15.el7.x86_64.rpm# 安装 fb303
wget http://rpmfind.net/linux/epel/7/x86_64/Packages/f/fb303-0.9.1-15.el7.x86_64.rpm
yum install fb303-0.9.1-15.el7.x86_64.rpm
刷新动态链接库
/sbin/ldconfig
下载 scribe
git clone https://github.com/facebookarchive/scribe.git
Readme
Archived Repo
=============This is an archived project and is no longer supported or updated by Facebook.
Please do not file issues or pull-requests against this repo. If you wish to
continue to develop this code yourself, we recommend you fork it.-------------Introduction
============Scribe is a server for aggregating log data that's streamed in real
time from clients. It is designed to be scalable and reliable.See the Scribe Wiki for documentation:
http://wiki.github.com/facebook/scribeKeep up to date on Scribe development by joining the Scribe Discussion Group:
http://groups.google.com/group/scribe-server/License (See LICENSE file for full license)
===========================================
Copyright 2007-2008 FacebookLicensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.Hierarchy
=========scribe/aclocal/Contains scripts for building/linking with Boostexamples/Contains simple examples of using Scribeif/Contains Thrift interface for Scribelib/Contains Python package for Scribesrc/Contains Scribe sourcetest/Contain php scripts for testing scribeRequirements
============[libevent] Event Notification library
[boost] Boost C++ library (version 1.36 or later)
[thrift] Thrift framework (version 0.5.0 or later)
[fb303] Facebook Bassline (included in thrift/contrib/fb303/)fb303 r697294 or later is required.
[hadoop] optional. version 0.19.1 or higher (http://hadoop.apache.org)These libraries are open source and may be freely obtained, but they are not
provided as a part of this distribution.Helpful tips:
-Thrift, fb303, and scribe installation expects python to be installedunder /usr. See PY_PREFIX option in 'configure --help' to change this path.
-Some python installs do not include python site-packages in the defaultpython include path. If python cannot find the installed packages forscribe or fb303, try setting the environment variable PYTHONPATH to thelocation of the installed packages. This path gets output during'make install'. (Eg: PYTHOnPATH='/usr/lib/python2.5/site-packages').To build
========./bootstrap.sh
make(If you have multiple versions of Boost installed, see Boost configure options below.)Subsequent builds
=================./bootstrap
makeOR./configure
makeNOTE: After the first run with bootstrap.sh you can use "[ ./bootstrap | ./configure ] " followed by "make"
to create builds with different configurations. "bootstrap" can be passed the same arguments as "configure".Make sure that if you change configure.ac and|or add macros run "bootstrap.sh".
to regenerate configure. In short whenever in doubt run "bootstrap.sh".Configure options
=================To find all available configure options run
./configure --helpUse *only* the listed options.Examples:
# To disable optimized builds and turn on debug. [ default has been set to optimized]
./configure --disable-opt# To disable static libraries and enable shared libraries. [ default has been set to static]
./configure --disable-static# To build scribe with Hadoop support
./configure --enable-hdfs# If the build process cannot find your Hadoop/Jvm installs, you may need to specify them manually:
./configure --with-hadooppath=/usr/local/hadoop --enable-hdfs CPPFLAGS="-I/usr/local/java/include -I/usr/local/java/include/linux" LDFLAGS="-ljvm -lhdfs"# To set thrift home to a non-default location
./configure --with-thriftpath=/myhome/local/thrift# If Boost is installed in a non-default location or there are multiple Boost versions
# installed, you will need to specify the Boost path and library names
./configure --with-boost=/usr/local --with-boost-system=boost_system-gcc40-mt-1_36 --with-boost-filesystem=boost_filesystem-gcc40-mt-1_36Install
=======as root:
make installRun
===See the examples directory to learn how to use Scribe.Acknowledgements
================
The build process for Scribe uses autoconf macros to compile/link with Boost.
These macros were written by Thomas Porschberg, Michael Tindal, and
Daniel Casimiro. See the m4 files in the aclocal subdirectory for more
information.
运行
# 查看脚本
cat bootstrap.sh# 执行脚本
./bootstrap.sh --prefix=/usr/local/scribe --with-thriftpath=/usr/local/thrift/ --with-fb303path=/usr/local/fb303/ --with-boost=/usr/local/boost/
Scribe 的配置文件分为全局配置和存储配置两部分:
全局配置
port:指示scribe服务器在哪一个端口上监听,默认是0,通过命令行参数选项-P可以指定端口,也能够通过配置文件指定。在源代码中就赋值给变量port。max_msg_per_second:默认值是0,如果这个参数值是0将被忽略。随着最近的改变这个参数很少被关联使用到,max_queue_size参数将被应用到限制每秒最大的消息数。在scribeHandler::throttleDeny被使用。max_queue_size(按字节):接收消息的队列的最大字节,默认是5,000,000字节。在scribeHandler::Log使用。check_interval(秒):用于控制多长时间检查一次存储,默认值是5.new_thread_per_category(是/否):如果为是,将为每一个分类场景创建一个新的线程,否则将创一个单线程为每一个在配置文件中定义的存储。对于前缀存储或默认存储,如果这个参数设置成“否”将导致所有匹配这个分类的消息都由一个单独的存储来处理。否则将为每一个唯一的分类名创建一个新的存储。默认为“是”。num_thrift_server_threads:为接收消息的监听线程数量,默认是3.max_conn:最大的链接数。
其他开源的日志系统
scribe主页:https://github.com/facebook/scribe
chukwa主页:http://incubator.apache.org/chukwa/
kafka主页:http://sna-projects.com/kafka/
Flume主页:https://github.com/cloudera/flume/
参考:
https://www.cnblogs.com/likehua/p/3796826.html
https://blog.csdn.net/weixin_34200628/article/details/89997699










 京公网安备 11010802041100号
京公网安备 11010802041100号