前言:由于需要讲课,做了关于RNN的ppt,文章内有两个程序分别是用RNN来预测和分类。这里假设大家已经有感知器或者BP神经网络的基础。 若格式等问题可以访问我的博客 https://blog.csdn.net/a984297068/article/details/80808003 或点击文章尾部阅读原文。
一. RNN提出原因
在很多实际应用中,数据是相互依赖的。某些任务需要能够更好的处理序列的信息,即前面的输入和后面的输入是有关系的。如:处理视频的时候,不能只单独的去分析每一帧,而要分析这些帧连接起来的整个序列。
循环神经网络主要用来处理序列数据
二. RNN应用
1.机器翻译
机器翻译是将一种源语言语句变成意思相同的另一种源语言语句,如将英语语句变成同样意思的中文语句。需要将源语言语句序列输入后,才进行输出,即输出第一个单词时,便需要从完整的输入序列中进行获取。

2.语音识别
语音识别是指给一段声波的声音信号,预测该声波对应的某种指定源语言的语句以及该语句的概率值。
3.图像描述生成 (Generating Image Descriptions)

和卷积神经网络(convolutional Neural Networks, CNNs)一样,RNNs已经在对无标图像描述自动生成中得到应用。将CNNs与RNNs结合进行图像描述自动生成。该组合模型能够根据图像的特征生成描述。
三. RNN循环神经网络
3.1单向循环神经网络
RNN模型展开后的效果图

RNN在每一时间步t有相同的网络结构。
设输入层的神经元个数为n,隐藏层神经元个数为m,输出层的神经元个数为r。U是连接输入层和隐藏层的权重矩阵;W是连接上一时间步的隐藏层单元与当前时间步的隐藏层单元的权重矩阵;V是连接隐藏层单元和输出层单元的权重矩阵。
RNN模型在每一个时间步的网络结构图

X表示RNN输入层,其中,xt表示序列中的第t时刻或第t时间步的输入数据,通常是一个向量。中间部分是网络的隐藏层,记为S,与输入层一样,st 通常是一个向量。
隐藏层输出

Sigmoid可以替换为tanh、relu等激活函数。通常来说需要设定一个特殊的初始隐藏单元,即初始状态,一般设置为0向量。从上式可以看出,第t时间步的记忆信息由前面(t-1)时间步的记忆结果和当前输入x t 共同决定的,这些记忆信息保存在隐藏层中,不断向后传递,跨越多个时间步,影响每一个新输入数据的处理。不同类型的递归神经网络模型,本质上式隐藏层设计的不同。
输出层输出

o表示RNN输出层,其中,ot表示序列在第t时间步的输出结果,与输入层和隐藏层不同,输出层的设计比较灵活,并没有规定每一时间步都必须有输出。例如:在文本情感分类中,关心的是整个句子的情感结果,而不是每一个单词,因此只需要在最后时间步有输出层即可。对于分类模型,输出层的结果一般情况下仅依赖于当前的隐藏层数据,如上式。–其中U、W、V代表着相同的权重矩阵
3.2双向循环神经网络
Bi-RNN模型展开

在有些问题中,当前时刻的输出不仅和之前的状态有关,还可能和未来的状态有关系。比如预测一句话中缺失的单词不仅需要根据前文来判断,还需要考虑它后面的内容,真正做到基于上下文判断。
如:我的手机坏了,我打算__一部新手机。

Bi-RNN公式

在双向循环神经网络的隐藏层需要保存两个值,一个A参与正向计算,另一个A’参与反向计算。
正向计算和反向计算不共享权值,U和U’、W和 W’、V和V’是不同的权重矩阵。
四. RNN预测
4.1目的
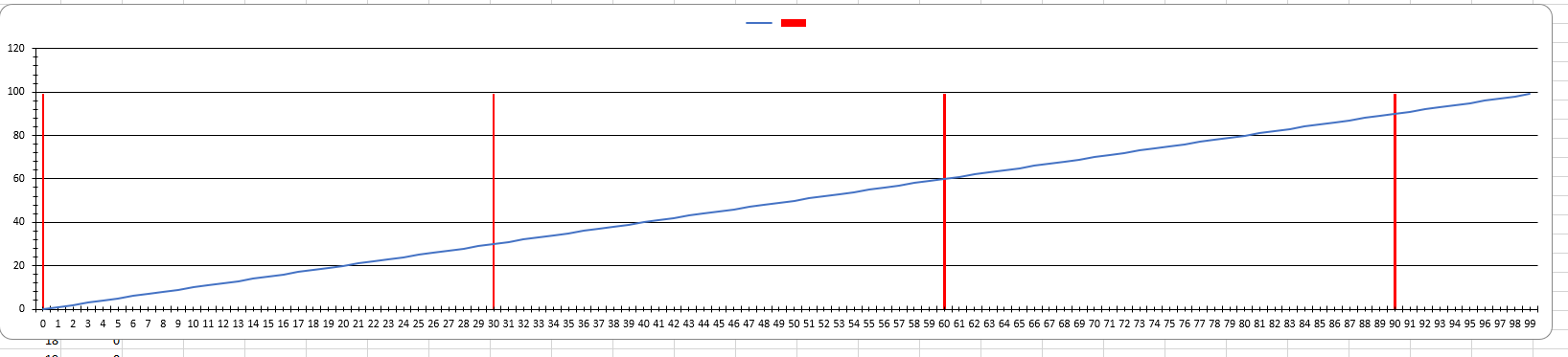
用sin曲线来预测cos曲线。

4.2模型
input:x=sin(steps) 、hidden_state (每个step是一个数值)
Label: y=cos(steps)
model:单向RNN,32个隐藏层神经元,隐藏层深度为1,输出是一个向量(包含不同step的预测值)
"""version pytorch 0.3.1"""
class RNN(nn.Module):
def __init__(self):
super(RNN, self).__init__()
self.rnn = nn.RNN(
input_size=INPUT_SIZE,
hidden_size=32, # rnn hidden unit
num_layers=1, # number of rnn layer
batch_first=True, # input & output will has batch size as 1s dimension. e.g. (batch, time_step, input_size)
)
self.out = nn.Linear(32, 1)
def forward(self, x, h_state):
# x (batch, time_step, input_size)
# h_state (n_layers, batch, hidden_size)
# r_out (batch, time_step, hidden_size)
# print(x.size())#torch.Size([1, 10, 1])
r_out, h_state = self.rnn(x, h_state) # print(r_out.size())#torch.Size([1, 10, 32])
# print(h_state.size())#torch.Size([1, 1, 32])
outs = [] # save all predictions
for time_step in range(r_out.size(1)): # calculate output for each time step
outs.append(self.out(r_out[:, time_step, :]))
return torch.stack(outs, dim=1), h_state # instead, for simplicity, you can replace above codes by follows
# r_out = r_out.view(-1, 32)
# outs = self.out(r_out)
# return outs, h_staternn = RNN() # 实例化
实现效果如下

五. RNN词性判断
5.1目的
判断单词的词性
对于一个单词,会有这不同的词性,首先能够根据一个单词的后缀来初步判断,比如 -ly 这种后缀,很大概率是一个副词,除此之外,一个相同的单词可以表示两种不同的词性,比如 book 既可以表示名词,也可以表示动词,所以到底这个词是什么词性需要结合前后文来具体判断。
根据这个问题,我们可以使用 rnn 模型来进行预测,首先对于一个单词,可以将其看作一个序列,比如 apple 是由 a p p l e 这 5 个字符构成,这就形成了 5 的序列,我们可以对这些字符构建词嵌入,然后输入rnn,只取最后一个输出作为预测结果,整个单词的字符串能够形成一种记忆的特性,帮助我们更好的预测词性。

5.2数据
训练集
training_data = [("The dog ate the apple".split(),
["DET", "NN", "V", "DET", "NN"]),
("Everybody read that book".split(),
["NN", "V", "DET", "NN"])]
对数据进行处理
"""对单词和标签进行编码"""
word_to_idx = {}
tag_to_idx = {}for context, tag in training_data: for word in context: if word.lower() not in word_to_idx:
word_to_idx[word.lower()] = len(word_to_idx) for label in tag: if label.lower() not in tag_to_idx:
tag_to_idx[label.lower()] = len(tag_to_idx)
"""对字母进行编码"""
alphabet = 'abcdefghijklmnopqrstuvwxyz'
char_to_idx = {}for i in range(len(alphabet)):
char_to_idx[alphabet[i]] = i
把输入数据构建成序列
def make_sequence(x, dic): # 字符编码
idx = [dic[i.lower()] for i in x]
idx = torch.LongTensor(idx) return idx
对每个单词的字符过RNN,在对每个单词过RNN,并把结果拼接起来。
"""构建单个字符的RNN模型"""
class char_rnn(nn.Module):
def __init__(self, n_char, char_dim, char_hidden):
super(char_rnn, self).__init__()
self.char_embed = nn.Embedding(n_char, char_dim)
self.rnn = nn.RNN(char_dim, char_hidden)
def forward(self, x):
x = self.char_embed(x)
out, _ = self.rnn(x)
return out[-1] # (batch, hidden)
"""构建词性分类的RNN模型"""
class rnn_tagger(nn.Module):
def __init__(self, n_word, n_char, char_dim, word_dim,
char_hidden, word_hidden, n_tag):
super(rnn_tagger, self).__init__()
self.word_embed = nn.Embedding(n_word, word_dim)
self.char_rnn = char_rnn(n_char, char_dim, char_hidden)
self.word_rnn = nn.RNN(word_dim + char_hidden, word_hidden)
self.classify = nn.Linear(word_hidden, n_tag)
def forward(self, x, word):
char = []
for w in word: # 对于每个单词做字符的 rnn
char_list = make_sequence(w, char_to_idx)
char_list = char_list.unsqueeze(1) # (seq, batch, feature) 满足 rnn 输入条件
char_infor = self.char_rnn(Variable(char_list)) # (batch, char_hidden)
char.append(char_infor)
char = torch.stack(char, dim=0) # (seq, batch, feature)
x = self.word_embed(x) # (batch, seq, word_dim)
# print(x.size())
x = x.permute(1, 0, 2) # 改变顺序
x = torch.cat((x, char), dim=2) # 沿着特征通道将每个词的词嵌入和字符 rnn 输出的结果拼接在一起
x, _ = self.word_rnn(x)
s, b, h = x.shape
x = x.view(-1, h) # 重新 reshape 进行分类线性层
out = self.classify(x)
return out
5.4训练
"""初始化网络、采用交叉熵损失函数、构建优化器"""
net = rnn_tagger(len(word_to_idx), len(char_to_idx), 10, 100, 50, 128, len(tag_to_idx))
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(), lr=1e-2)
# 开始训练
for e in range(10):
train_loss = 0
for word, tag in training_data:
word_list = make_sequence(word, word_to_idx).unsqueeze(0) # 添加第一维 batch
tag = make_sequence(tag, tag_to_idx)
word_list = Variable(word_list)
tag = Variable(tag) # 前向传播
out = net(word_list, word)
loss = criterion(out, tag)
train_loss += loss.data[0] # 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step() if (e + 1) % 50 == 0:
print('Epoch: {}, Loss: {:.5f}'.format(e + 1, train_loss / len(training_data)))
5.5测试
"""打印预测的词性"""
def get_predict_name(mydict,out):
pred = ''
for pred_out in out:
for key, val in mydict.items():
if val == pred_out:
pred = pred + key+','+'\t'
print(pred)
"""测试"""
net = net.eval()
test_sent = 'Everybody ate the apple'
test_label = 'nn, v, det, nn'
test = make_sequence(test_sent.split(), word_to_idx).unsqueeze(0)
out = net(Variable(test), test_sent.split())
pred_out = torch.max(out, 1)[1].data.squeeze().int().numpy()
get_predict_name(tag_to_idx,pred_out)
print(test_label)
结果如下

后记:
很多事不用问值不值得,只用问,它对你来说,是不是有如珍宝。








 京公网安备 11010802041100号
京公网安备 11010802041100号