这期内容当中小编将会给大家带来有关什么是Python中的模块,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
一、python中的模块
有过C语言编程经验的朋友都知道在C语言中如果要引用sqrt函数,必须用语句#include 引入math.h这个头文件,否则是无法正常进行调用的。
那么在Python中,如果要引用一些其他的函数,该怎么处理呢?
在Python中有一个概念叫做模块(module),这个和C语言中的头文件以及Java中的包很类似,比如在Python中要调用sqrt函数,必须用import关键字引入math这个模块,下面就来了解一下Python中的模块。
说的通俗点:模块就好比是工具包,要想使用这个工具包中的工具(就好比函数),就需要导入这个模块。
模块的概念:
1.每一个以扩展名py结尾的python源代码文件都是一个模块。
2.模块名同样也是一个标识符,需要符合标识符的命名规范。
3.在模块中定义的全局变量、函数、类都是提供给外界直接使用的工具。
4.模块就好比工具包,要想使用这个工具包中的工具,就需要先导入这个模块。
二、import
在Python中用关键字import来引入某个模块,比如要引用模块math,就可以在文件最开始的地方用import math来引入。
import导入
import 模块名1,模块名2 #不推荐
说明:在导入模块时,每个导入应该独占一行(推荐)
import 模块1
import 模块2
导入之
通过模块名使用模块提供的工具---全局变量、函数、类。
只用as指定模块的别名。
如果模块的名字太长,可以使用as指定模块的别名,以方便在代码中的使用。
import 模块名1 as 模块别名
注意:模块别名应该符合托峰值命名规范
为什么要加上模块名呢?
因为可能存在这样一种情况:在多个模块中含有相同名称的函数,此时如果只是通过函数名来调用,解释器无法知道到底要调用哪个函数。所以如果像上述这样引入模块的时候,调用函数必须加上模块名。
三、from … import
from...import导入
1.如果想从某一模块中导入部分工具,就可以使用from...import的方式。
2.import模块名是一次性把模块中所有的工具全部导入,并且通过模块名/别名访问。
#从模块中导入某一个工具
from 模块名 import 工具名#可以通过as为工具指定别名
导入之后
1.不需要通过模块名. 的方式使用模块提供的工具
2.可以直接使用模块提供的工具 --- 全局变量、函数、类
注意:
1.如果两个模块,存在同名的函数,name后导入模块的函数会覆盖先导入的函数
2.开发时import代码应该统一写在代码的顶部,更容易及时发现冲突
3.如果发生冲突,可以使用as关键字,给其中一个工具起一个别名
from...import *
#从模块中导入所有工具
from 模块名 import *
注意:
这种法师不推荐使用,因为函数重名并没有任何的提示,出现问题不好排查
案例:
demo.py(自定义的模块)
#全局变量
title = "模块1"
#函数
def say_hello():
print("我是%s"%title)
#类
class Dog(object):
pass
#类
class Cat(object):
passtest.py中使用demo.py模块
#导入模块中的所有工具,同时为模块指定别名为myTest
import demo as myTest
#导入模块中所有工具,不推荐,工具同名不好排查
#from...import *
#from...import导入模块中的部分工具(Dog类)
from demo import Dog
#为导入工具Cat类指定别名Test_Cat,防止与其他模块中工具重名
from demo import Cat as Test_Cat
myTest.say_hello()
dog=Dog()
cat=Test_Cat()
四、python模块导入的搜索路
程序的主目录
PTYHONPATH目录(如果已经进行了设置)
标准连接库目录(一般在/usr/local/lib/python2.X/)
任何的.pth文件的内容(如果存在的话).新功能,允许用户把有效果的目录添加到模块搜索路径中去 .pth后缀的文本文件中一行一行的地列出目录。
这四个组建组合起来就变成了sys.path了,
当python import模块的时候,就通过sys.path里面的目录列表下面去查找。
sys.path是python的搜索模块的路径集,是一个list。
查看sys.path方法:
import sys
print(sys.path)
['C:\\Users\\Se7eN_HOU\\Desktop\\Tools\\sublimetext3\\Sublime Text Build 3176 x86',
'C:\\Program Files\\Python37\\python37.zip',
'C:\\Program Files\\Python37\\DLLs',
'C:\\Program Files\\Python37\\lib',
'C:\\Program Files\\Python37',
'C:\\Users\\Se7eN_HOU\\AppData\\Roaming\\Python\\Python37\\site-packages',
'C:\\Program Files\\Python37\\lib\\site-packages']
程序执行时导入模块路径
import sys
#因为sys.path是一个列表,所以可以在后面追加一个自定的模块路径
sys.path.append("/home/Se7eN_HOU")
#通过insert可以将路径插到前面
sys.path.insert(0,"Home/Se7eN")
print(sys.path)运行结果为:
['Home/Se7eN',
'C:\\Users\\Se7eN_HOU\\Desktop\\Tools\\sublimetext3\\Sublime Text Build 3176 x86',
'C:\\Program Files\\Python37\\python37.zip', 'C:\\Program Files\\Python37\\DLLs',
'C:\\Program Files\\Python37\\lib', 'C:\\Program Files\\Python37',
'C:\\Users\\Se7eN_HOU\\AppData\\Roaming\\Python\\Python37\\site-packages',
'C:\\Program Files\\Python37\\lib\\site-packages',
'/home/Se7eN_HOU']
五、模块制作
1、定义自己的模块
在Python中,每个Python文件都可以作为一个模块,模块的名字就是文件的名字。
比如有这样一个文件test.py,在test.py中定义了函数add
def add(a,b):
return a+b
2、调用自己的模块
那么在demo.py文件中就可以先import test,然后通过test.add(a,b)来调用了,当然也可以通过from test import add来引入
import test
result = test.add(1,2)
print(result)
运行结果为:3
3、测试模块
在实际开中,当一个开发人员编写完一个模块后,为了让模块能够在项目中达到想要的效果,这个开发人员会自行在py文件中添加一些测试信息,例如:test.py文件
def add(a,b):
return a+b
#用来测试
ret = add(11,22)
print("in test.py 测试11+22 = %d"%ret)如果此时,在demo.py文件中引入了此文件的话,想想看,测试的那段代码是否也会执行呢!
import test
result = test.add(1,2)
print(result)
运行结果为:
in test.py 测试11+22 = 33
3
至此,可发现test.py中的测试代码,应该是单独执行test.py文件时才应该执行的,不应该是其他的文件中引用而执行。为了解决这个问题,python在执行一个文件时有个变量__name__
test.py文件中:
def add(a,b):
return a+b
#用来测试
#ret = add(11,22)
#print("in test.py 测试11+22 = %d"%ret)
print("in test.py,__name__ is %s"%__name__)运行结果为:
in test.py,__name__ is __main__
在demo.py文件中导入test.py模块运行为
import test
result = test.add(1,2)
print(result)
运行结果为:
in test.py,__name__ is test
3
可以根据__name__变量的结果能够判断出,是直接执行的python脚本还是被引入执行的,从而能够有选择性的执行测试代码。
test.py模块中代码改为:
def add(a,b):
return a+b
if __name__ == "__main__":
ret = add(11,22)
print("in test.py 测试11+22 = %d"%ret)在test.py中运行结果为:
in test.py 测试11+22 = 33
在demo.py中导入test.py模块
import test
result = test.add(1,2)
print(result)
运行结果为:3
这样我们在开中测试的代码,就不会在其他模块中出现了。
六、模块中的_ _all_ _
1、没有_ _all_ _
test.py模块
class Test(object):
def test(self):
print("---Test类中的test方法---")
def test1():
print("---test1方法---")
def test2():
print("---test2方法---")在demo.py中导入test.py模块
from test import *
a = Test()
a.test()
test1()
test2()
运行结果为:
---Test类中的test方法---
---test1方法---
---test2方法---
2、模块中有_ _all_ _
test.py模块
__all__ = ["Test","test1"]
class Test(object):
def test(self):
print("---Test类中的test方法---")
def test1():
print("---test1方法---")
def test2():
print("---test2方法---")demo.py模块
from test import *
a = Test()
a.test()
test1()
test2()
运行结果为:
---Test类中的test方法---Traceback (most recent call last):
---test1方法---
File "C:\Users\Se7eN_HOU\Desktop\Tools\sublimetext3\Sublime Text Build 3176 x86\demo.py", line 5, in
test2()
NameError: name 'test2' is not defined
如果一个文件中有__all__变量,那么也就意味着只有这个变量中的元素,才会被from xxx import *时导入。
七、系统sys模块介绍
sys是python自带模块,常用的函数有:
sys.argv: 实现从程序外部向程序传递参数。
sys.exit([arg]): 程序中间的退出,arg=0为正常退出。
sys.getdefaultencoding(): 获取系统当前编码,一般默认为ascii。
sys.setdefaultencoding(): 设置系统默认编码,执行dir(sys)时不会看到这个方法,在解释器中执行不通过,可以先执行reload(sys),在执行 setdefaultencoding('utf8'),此时将系统默认编码设置为utf8。(见设置系统默认编码 )
sys.getfilesystemencoding(): 获取文件系统使用编码方式,Windows下返回'mbcs',mac下返回'utf-8'。
sys.path: 获取指定模块搜索路径的字符串集合,可以将写好的模块放在得到的某个路径下,就可以在程序中import时正确找到。
sys.platform: 获取当前系统平台。
1、sys.argv[]
sys.argv[]说白了就是一个从程序外部获取参数的桥梁,这个“外部”很关键。因为我们从外部取得的参数可以是多个,所以获得的是一个列表(list),也就是说sys.argv其实可以看作是一个列表,所以才能用[]提取其中的元素。其第一个元素是程序本身,随后才依次是外部给予的参数。
下面我们通过一个极简单的test.py程序的运行结果来说明它的用法。
#test.py
import sys
a=sys.argv[0]
print(a)
将test.py保存在c盘的根目录下。
在程序中找到 ‘运行’->点击->输入"cmd"->回车键 进入控制台命令窗口(如下图),先输入cd c:\ (作用是将命令路径改到c盘根目录),然后输入test.py运行我们刚刚写的程序:

得到的结果是C:\test.py,这就是0指代码(即此.py程序)本身的意思。
然后我们将代码中0改为1 :
a=sys.argv[1]
保存后,再从控制台窗口运行,这次我们加上一个参数,输入:test.py what
#test.py
import sys
a=sys.argv[1]
print(a)
运行结果是:
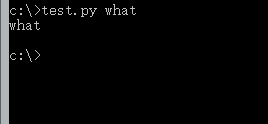
得到的结果就是我们输入的参数what,看到这里你是不是开始明白了呢。
那我们再把代码修改一下:
a=sys.argv[2:]
保存后,再从控制台窗台运行程序,这次多加几个参数,以空格隔开:
test.py a b c d e f
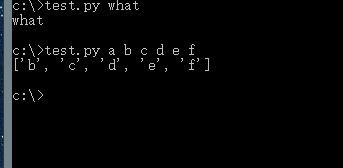
得到的结果为[‘b’, ’c’, ’d’, ’e’, ’f’]
应该大彻大悟了吧。Sys.argv[ ]其实就是一个列表,里边的项为用户输入的参数,关键就是要明白这参数是从程序外部输入的,而非代码本身的什么地方,要想看到它的效果就应该将程序保存了,从外部来运行程序并给出参数。
2、sys.path已经在上面讲过了
3、sys.exit()
程序中间的退出, arg=0为正常退出
一般情况下执行到主程序末尾,解释器自动退出,但是如果需要中途退出程序,可以调用sys.exit函数,带有一个可选的整数参数返回给调用它的程序,表示你可以在主程序中捕获对sys.exit的调用。(0是正常退出,其他为异常)当然也可以用字符串参数,表示错误不成功的报错信息。
import sys
def exitfunc(value):
print (value)
sys.exit(0)
print("hello")
try:
sys.exit(90)
except SystemExit as value:
exitfunc(value)
print("come?")运行结果:
hello
90
程序首先打印hello,在执行exit(90),抛异常把90传给values,values在传进函数中执行,打印90程序退出。后面的”come?”因为已经退出所以不会被打印. 而此时如果把exitfunc函数里面的sys.exit(0)去掉,那么程序会继续执行到输出”come?”。
4、sys.modules
sys.modules是一个全局字典,该字典是python启动后就加载在内存中。每当程序员导入新的模块,sys.modules将自动记录该模块。当第二次再导入该模块时,python会直接到字典中查找,从而加快了程序运行的速度。它拥有字典所拥有的一切方法。
import sys
print(sys.modules.keys())
print("**************************************************************************")
print(sys.modules.values())
print("**************************************************************************")
print(sys.modules["os"])运行结果为:
dict_keys(['sys', 'builtins', '_frozen_importlib', '_imp', '_thread', '_warnings', '_weakref', 'zipimport',
'_frozen_importlib_external', '_io', 'marshal', 'nt', 'winreg', 'encodings', 'codecs', '_codecs',
'encodings.aliases', 'encodings.utf_8', '_signal', '__main__', 'encodings.latin_1', 'io', 'abc', '_abc', 'site',
'os', 'stat', '_stat', 'ntpath', 'genericpath', 'os.path', '_collections_abc', '_sitebuiltins'])
**************************************************************************
dict_values([, , ,
, , , , , , , , , ,
, , , , , , , , , ,
, , , ,
, ,
, , , ])
**************************************************************************
5、sys.stdin, sys.stdout, sys.stderr
stdin,stdout,stderr在Python中都是文件属性对象, 他们在python启动时自动与shell环境中的标准输入, 输出, 出错相关. 而python程序在shell中的I/O重定向是有shell来提供的,与python本身没有关系.python程序内部将stdin, stdout, stderr读写操作重定向到一个内部对象.
#import sys
print("Hi, %s!' %input('Please enter your name: "))
#运行结果:Please enter your name: er
#Hi, er!
#等同于:
import sys
print('Please enter your name:')
name=sys.stdin.readline()[:-1]
print('Hi, %s!' %name)
#标准输出
print('Hello World!\n')
#等同于:
import sys
sys.stdout.write('Hello world!\n')上述就是小编为大家分享的什么是Python中的模块了,如果刚好有类似的疑惑,不妨参照上述分析进行理解。如果想知道更多相关知识,欢迎关注编程笔记行业资讯频道。






 京公网安备 11010802041100号
京公网安备 11010802041100号