篇首语:本文由编程笔记#小编为大家整理,主要介绍了java之集合相关的知识,希望对你有一定的参考价值。
a)数组: b)集合
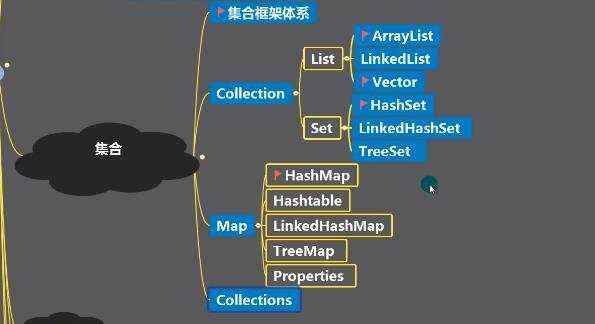
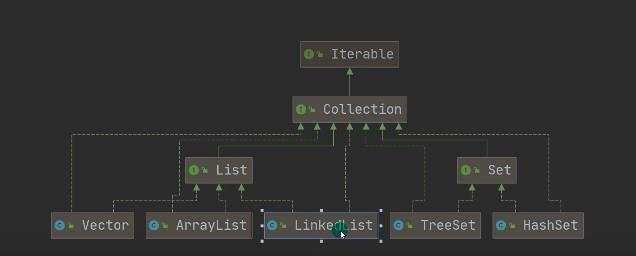
集合主要两种:单列集合(对象)、双列集合(键值对) a)collection b)Map
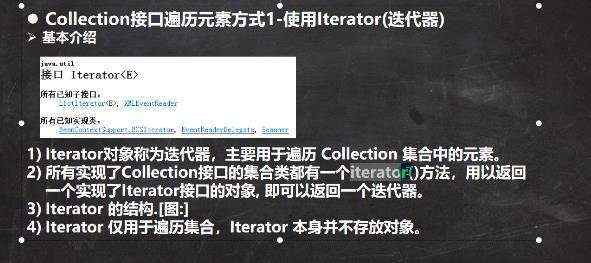
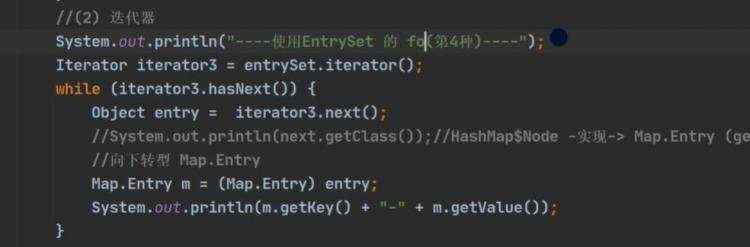
a) b)collection的子类都可以使用Iterator迭代器 ii)迭代器原理: 可重复; ii)增强for循环
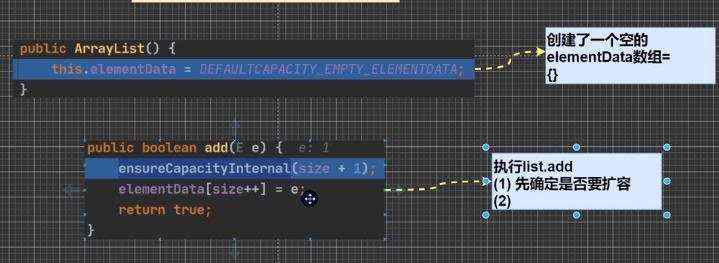
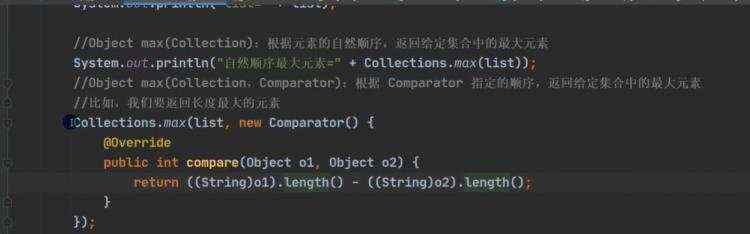
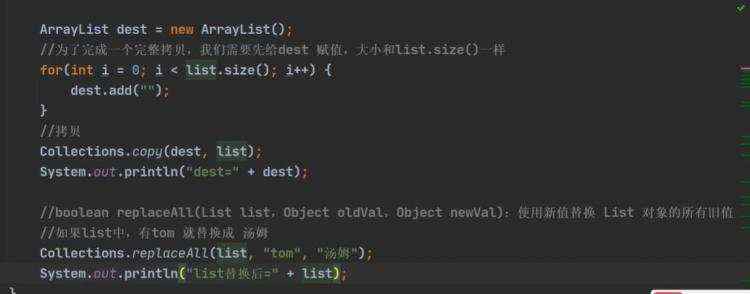
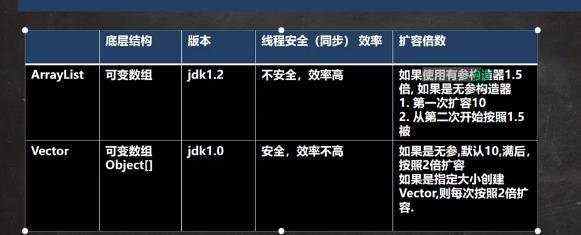
a)可以放任何值,可以加入null,并且多个 b)底层是由数组实现 c)arrayList等同vector,效率高于vector,但是线程不安全 d)创建一个对象分析 源码分析 ii)无参数
ii)指定大小的参数 构造器的差别
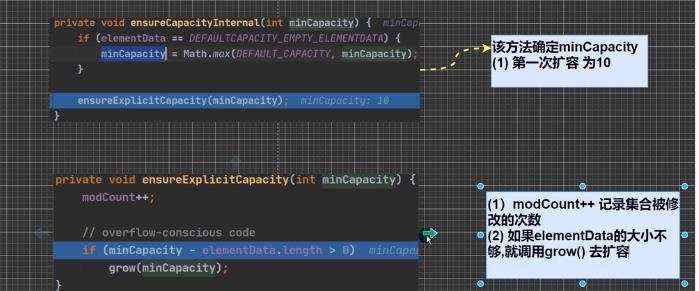
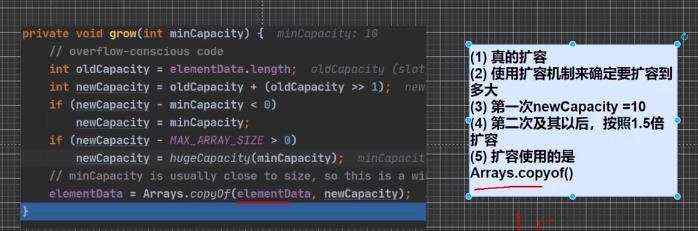
扩容机制:
a)添加的源码分析:
import java.util.LinkedList;public class LinkList { public static void main(String[] args) { LinkedList linkedList = new LinkedList(); linkedList.add(1); System.out.println("linkedList:"+linkedList); }}
b)删除的源码分析: linkedList.remove();
注解:核心方法是unlinkFirst() 个人一开始比较疑惑的是: if (next == null) last = null; else next.prev = null; 当next为空的时候,证明没有下一个元素了,所以最后一个肯定也为null; else:不为空的话,作为第一元素的prev也应该指向为空,(至于为啥这里last不用在重新指向呢?是因为add()的时候,last代表最后一个元素,只要元素存在,last值就一定还为发生改变)
两者比较: 两者都是线程不安全
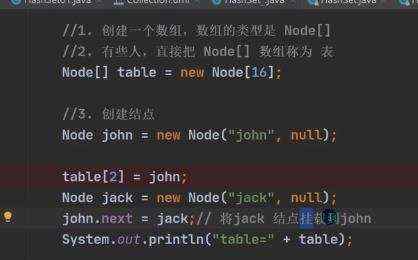
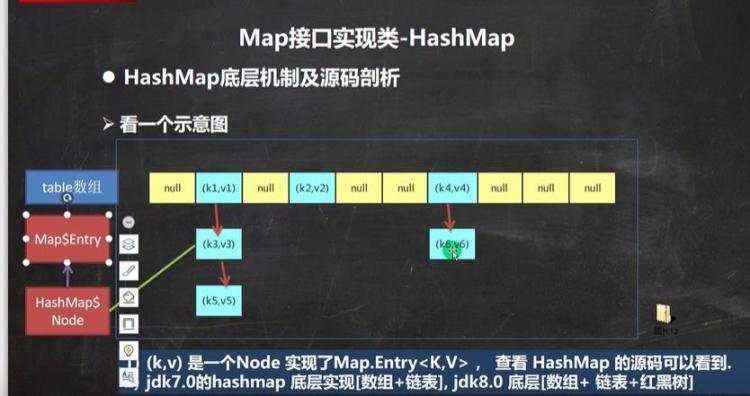
单向链表 a)遍历的二种方式(没有普通for循环,因为没有通过索引获取的方法) ii)迭代器 ii)增强for循环 b)hashset底层机制(底层是hashMap) hashMap底层是:数组+链表+红黑树
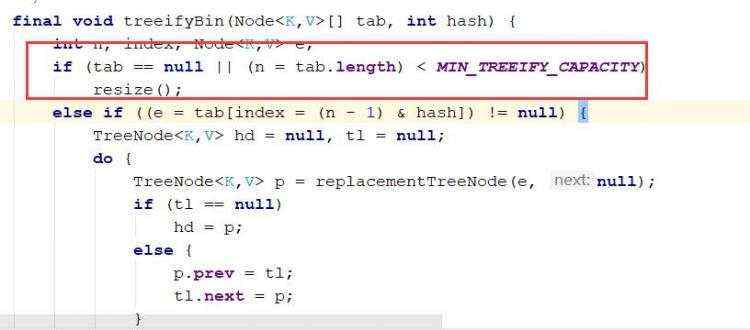
分析: ii)hashSet底层是hashMap,第一次进来的时候先进行扩容到16,默认加载因为是0.75,即没每次达到当前数组长度的0.75倍时候,扩容到当前数组长度2;
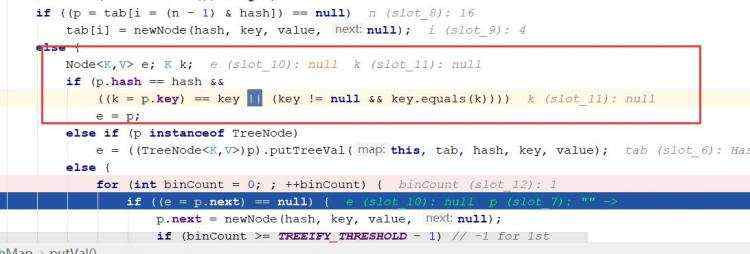
ii)当根据计算得到新进来的元素在tab的索引的已经存在元素的时候,比较他们之间的hashcode+equal(),倘若符合条件,将对元素进行覆盖;
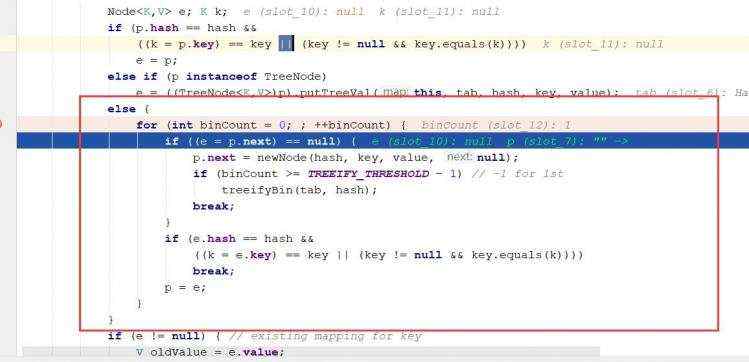
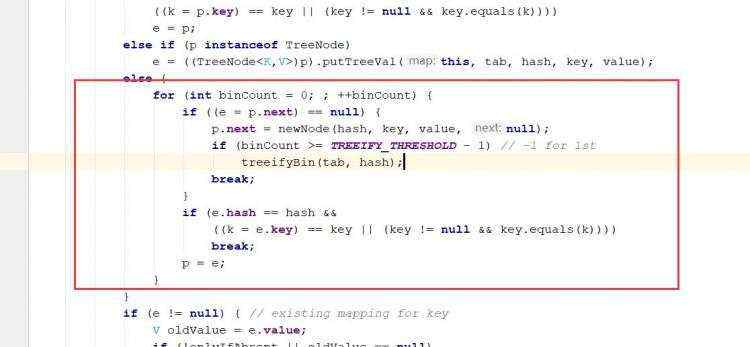
ii)如果p可能是树,最后一种情况就是链表; 当进行链表的遍历时候,没有相等的话,就加载链表的末端,如果加进来的数量大于等于8-1的时候,将调用树化的方法; ii)链表循环有两处跳出的判断:一处是成功往链表加入节点;一处是判断元素的hash()+equal()符合条件
c)源码分析: d) hashset地扩容和转换为红黑树机制
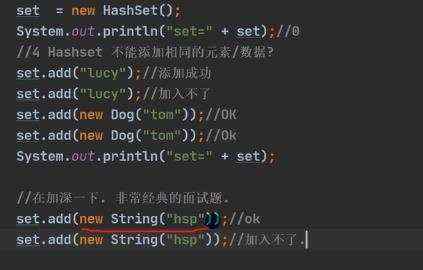
e)hashSet比较原理 (hashcode()+equals())
注释:例如一个对象Dog 输出(new Dog(“name”) 其实是new Dog(“name”).toString())
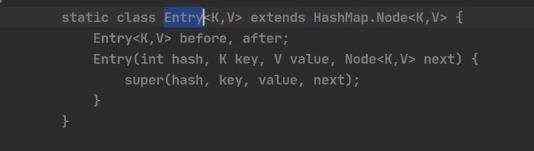
9)linkedHashSet (可以看成是在HashSet的基础上加上before和after保证元素的插入顺序) 双向链表:确保遍历顺序和插入顺序一样
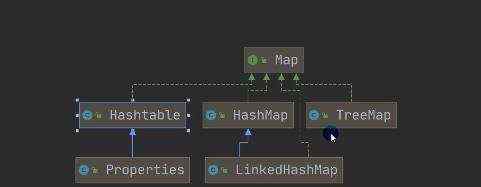
重点: 为什么hashMap N o d e [ ] 能 存 放 L i n k e d H a s h M a p Node[]能存放LinkedHashMap Node[]能存放LinkedHashMapEntry呢,由源码可以看出,他们是继承关系:
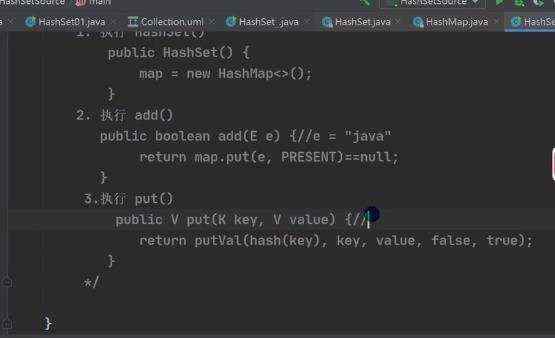
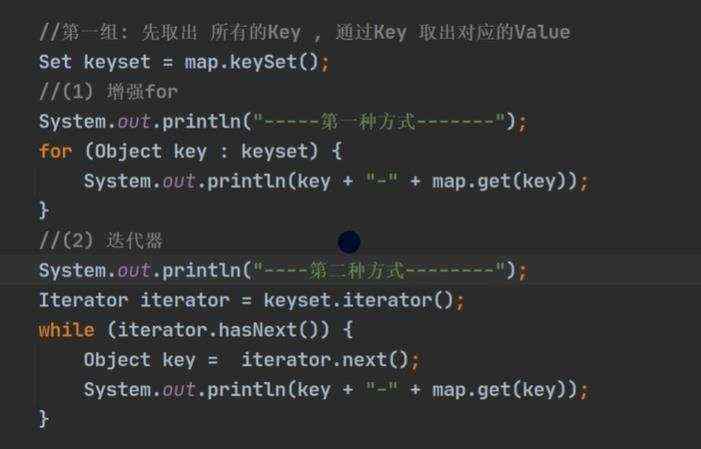
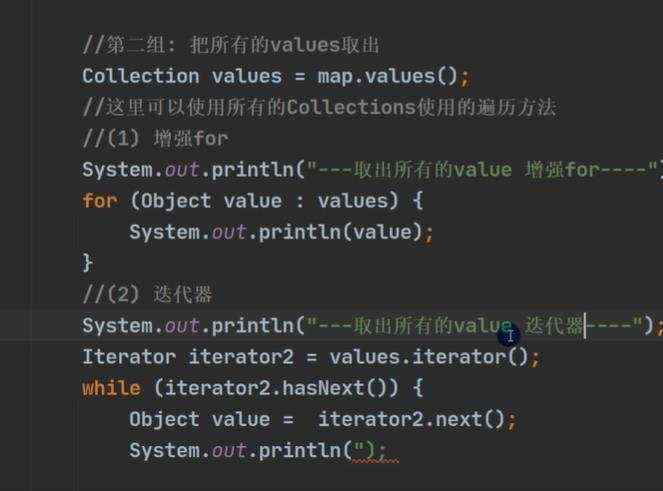
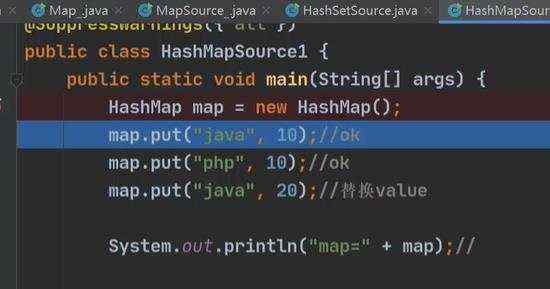
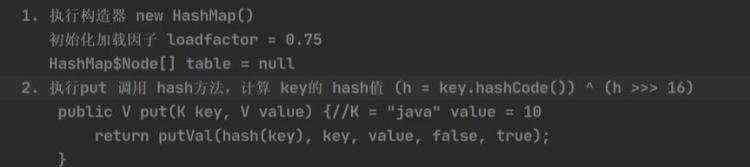
a)jdk8 map 接口特点 b)map.put存的和取的顺序是不一样的, 得到key的时候,先根据hashcode()计算位置,在根据equals()来判断,这也是key为啥不能重复的原因,倘若放重复的key,将会把之前的k-v替换掉
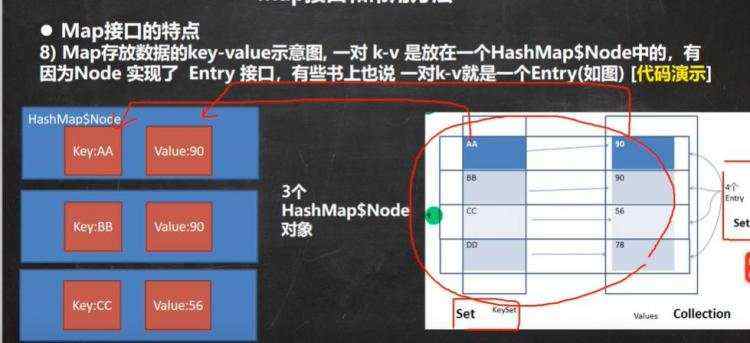
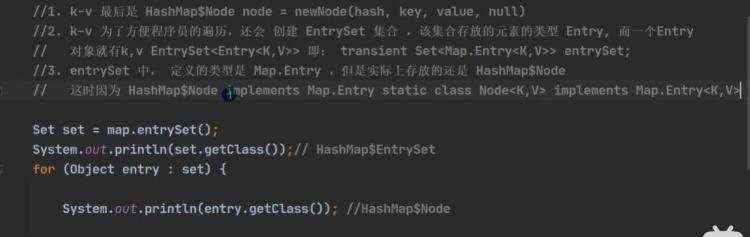
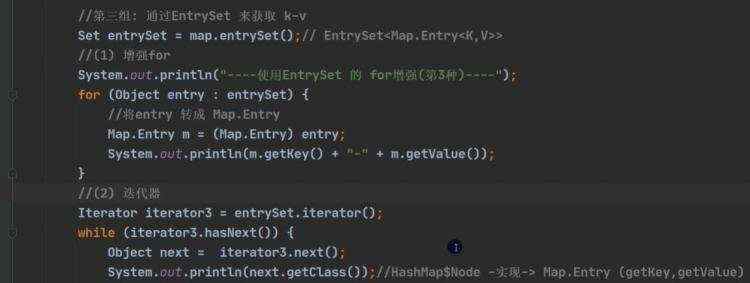
c)一个k-v是放在hashMap N o d e 里 面 h a s h M a p Node里面 hashMap Node里面hashMapNode node = newNode(hash,key,value,null),而node是实现entry; 然后再把一个个newNode放在set里面,方便遍历,事实上set里面的(keySet《set》,values《Collection》)只是简单的指向,并非真正的重新存入一份数据。
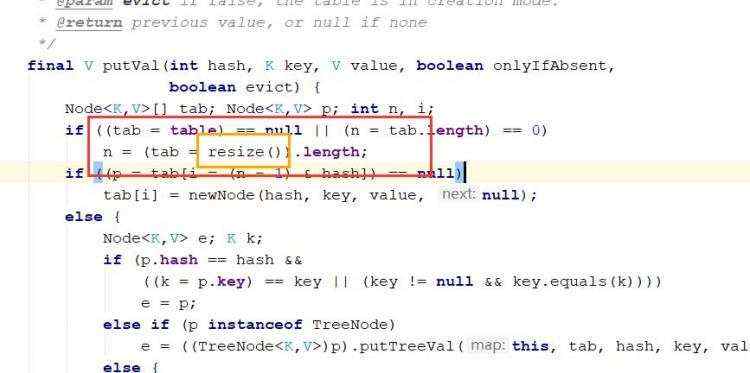
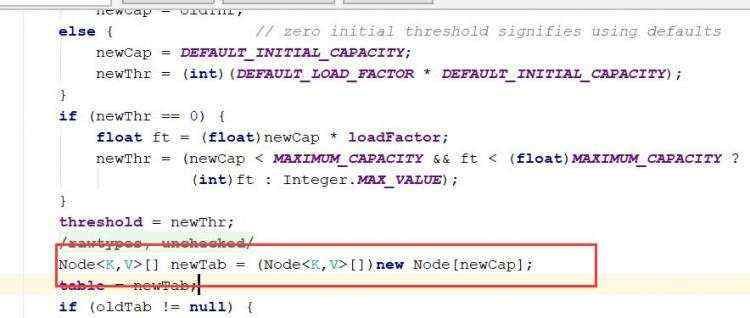
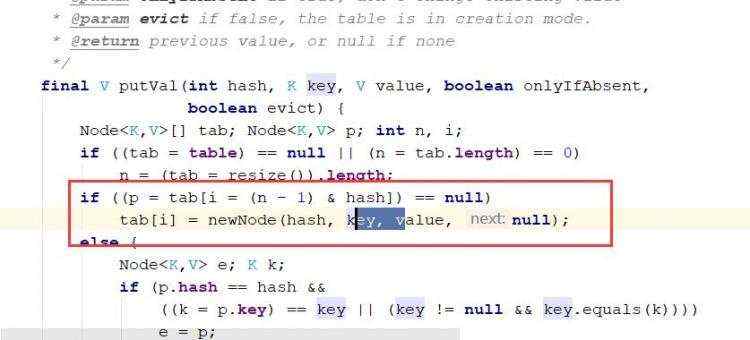
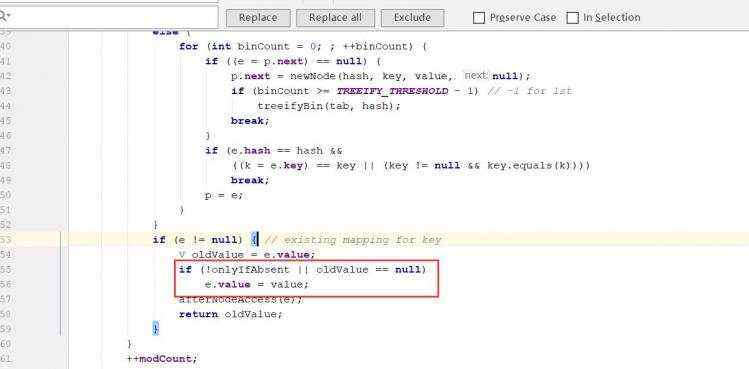
d)map的遍历 e)hashMap底层机制 ii)示意图 ii)程序分析 ii)第一次进去将进行扩容 从resize()方法可以看出是个Node ii)当hash值为null时候,将创建一个newNode加入到Node[] tab 数组 ii)当为重复的时候,将实现覆盖 ii)当判断是链表的时候,有两种情况跳槽循环: 链表长度大于等于8;链表存在元素相等的情况 ii)当长度达到8的时候,并不是马上树化,长度不够64的情况会先进行扩容
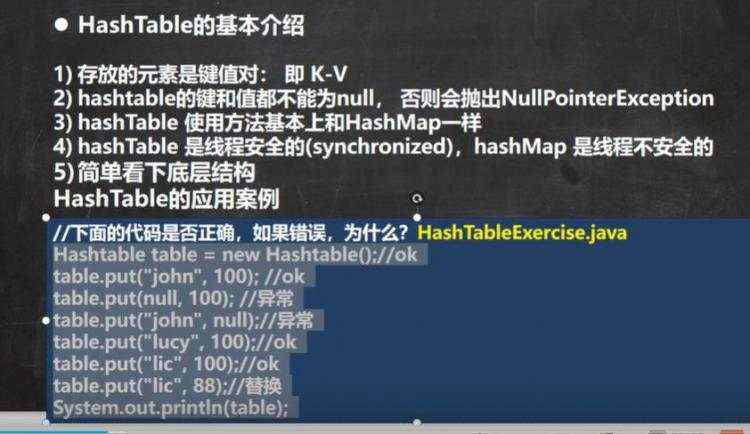
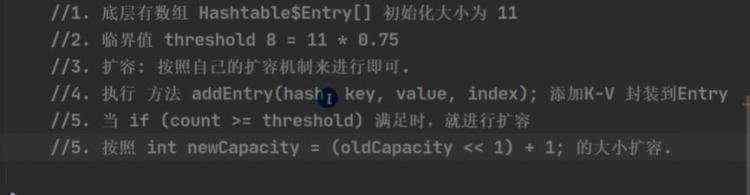
a)基本介绍 b)扩容
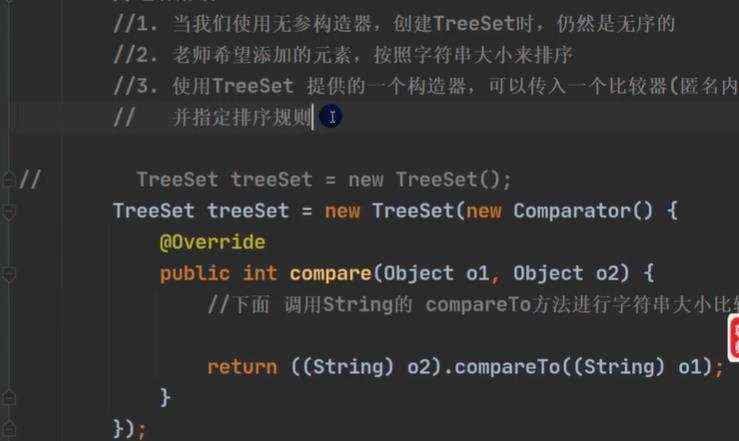
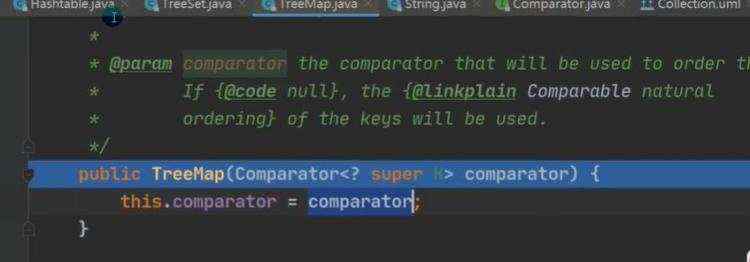
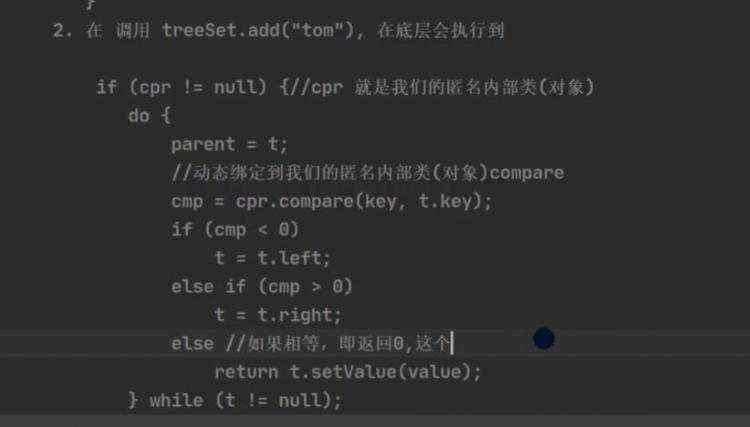
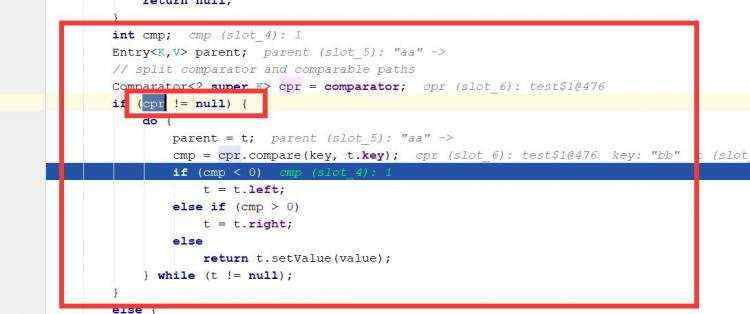
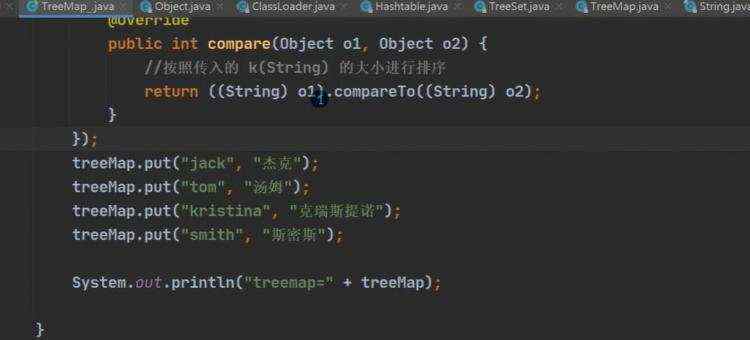
a)treeSet底层是treeMap b)cpr代表传进去的内部类,进行循环比较
(无参构造是没有顺序的,和treeSet类似) 当添加的key相等时候,value是会替换的
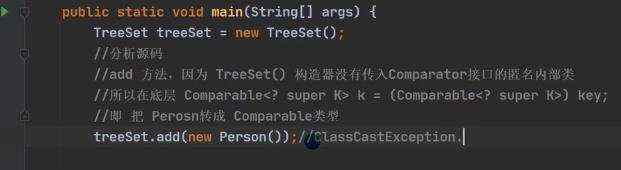
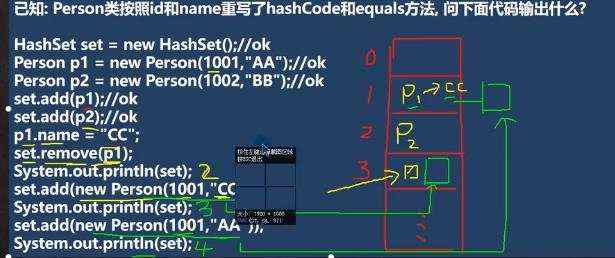
传入无参构造时候,将会把person转为Comparable,而person并未实现Comparable接口,所以会出现类型异常 一开始p1和p2能够加入, 当p1.name改变时候 set.remove(p1);由于hashCode发生了改变,无法移除到原来的对象,所以此时还保持着两个元素; set.add(new Person(1001,“cc”)),计算出来的hashcode不一样,所以会存放进去; 当set.add(new Person(1001,“AA”)),虽然和第一个的hashcode一样,但是此时的内容是不一样的,所以将形成链表挂在第一个的后面







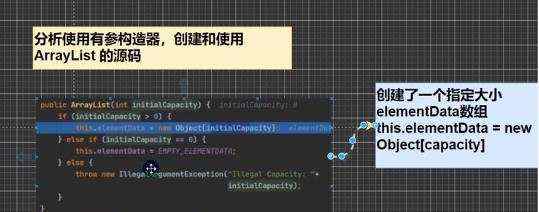


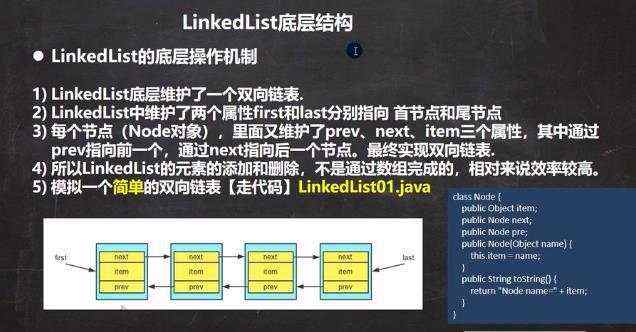 a)添加的源码分析:
a)添加的源码分析: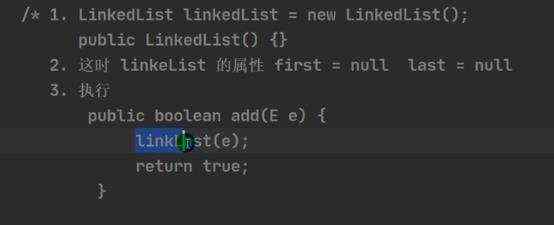 b)删除的源码分析:
b)删除的源码分析: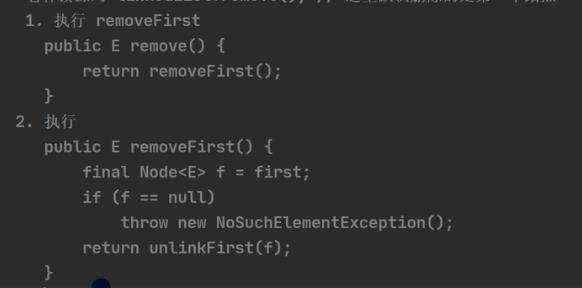
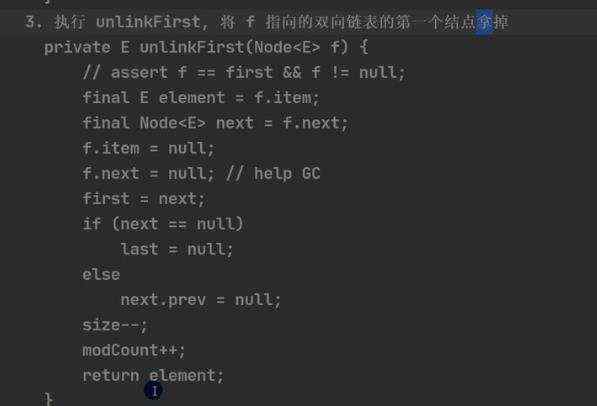 注解:核心方法是unlinkFirst()
注解:核心方法是unlinkFirst()
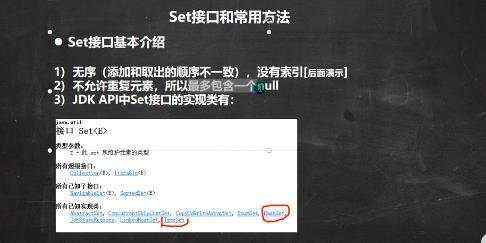


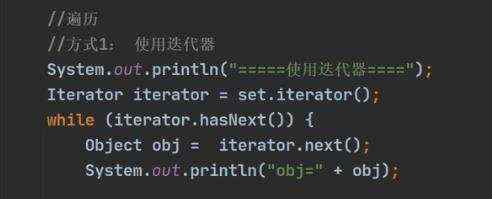
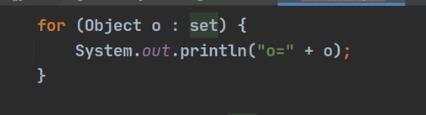













![[大整数乘法] java代码实现](https://img1.php1.cn/3cd4a/24c6f/9f3/0133bb25da242824.jpeg)





 京公网安备 11010802041100号
京公网安备 11010802041100号