在python中使用 KNN算法实现鸢尾花数据集分类
- 作者介绍
- 数据集介绍
- KNN算法介绍
- 用KNN实现鸢尾花分类
作者介绍
乔冠华,女,西安工程大学电子信息学院,2020级硕士研究生,张宏伟人工智能课题组。
研究方向:机器视觉与人工智能。
电子邮件:1078914066@qq.com
数据集介绍

Iris鸢尾花数据集: 包含 3 类分别为山鸢尾(Iris-setosa)、变色鸢尾(Iris-versicolor)和维吉尼亚鸢尾(Iris-virginica),共 150 条数据,每类各 50 个数据,每条记录都有 4 项特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度,通常可以通过这4个特征预测鸢尾花卉属于哪一品种。
数据集获取:
首先要在自己的Python环境中下载sklearn(进入个人虚拟环境并输入):
pip install sklearn
接着就可以输入下面代码,下载数据集
from sklearn.datasets import load_iris
iris_dataset = load_iris()
Iris数据集包含在sklearn库当中,具体在sklearn\\datasets\\data文件夹下,文件名为iris.csv。其数据格式如下:
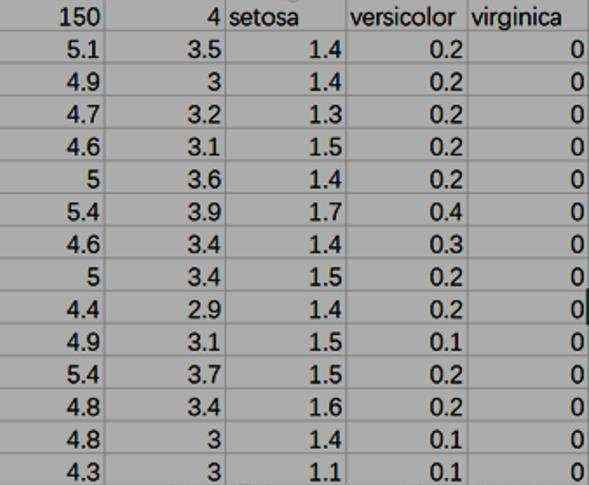
图中第一行数据的意义是:150(数据集中数据的总条数);4(特征值的类别数),即花萼长度、花萼宽度、花瓣长度、花瓣宽度;setosa、versicolor、virginica:三种鸢尾花名。
从第二行开始各列数据的意义:第一列为花萼长度值;第二列为花萼宽度值;第三列为花瓣长度值;第四列为花瓣宽度值;第五列对应是种类(三类鸢尾花分别用0,1,2表示)。
KNN算法介绍
算法介绍:
KNN算法也称K最近邻算法,是有监督学习中最常用的分类算法之一。其算法原理是:给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例, 这K个实例的多数属于某个类,就把该输入实例分类到这个类中。
一句话形容 KNN 算法的思想:物以类聚,人以群分
在 KNN 算法中新样本到邻近样本的距离一般采用的是欧式距离(常用)或者曼哈顿距离

根据KNN算法的原理,该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待测样本所属的类别,因此,选取合适的邻近样本数K就十分重要了。
K值的影响:
当我们要确定图中绿色待测样本属于红色类别还是蓝色类别时,我们可以通过不同的K值大小得出不同的预测结果。
K=1时,距离绿色样本最近的一个类型是红色,因此判定绿色样本属于红色类。

K=3时,距离绿色样本最近的3个实例中(圆圈内),有两个是蓝色、一个是红色。则绿色样本属于蓝色类。

K=5时,距离绿色样本最近的5个实例中(圆圈内),有三个是红色、两个是蓝色。则绿色样本属于红色类。

K值的选取:
K 值一般是通过交叉验证来确定的(经验规则来说,一般 k 是低于训练样本数的平方根)
交叉验证:本例中通过将原始数据按照一定的比例,如 4:1 ,拆分成训练数据集和测试数据集,K 值从一个较小的值开始选取,逐渐增大,然后计算整个集合的方差,从而确定一个合适的 K 值。
代码参考:链接: https://zhuanlan.zhihu.com/p/61996479.
用KNN实现鸢尾花分类
实现过程:
1)利用slearn库中的load_iris()导入iris数据集 ;
2)使用train_test_split()对数据集进行划分,并进行数据集的随机分割;
3)KNeighborsClassifier()设置邻居数;
4)利用fit()构建基于训练集的模型;
5)使用predict()进行预测;
6)使用score()进行模型评估。
代码实现:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split#用于模型划分
from sklearn.neighbors import KNeighborsClassifier##KNN算法包
import numpy as np
# 载入数据集
iris_dataset = load_iris()
X = iris_dataset['data']#特征
Y = iris_dataset['target']#类别
# 数据划分
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=0)
#训练阶段
knn = KNeighborsClassifier(n_neighbors=5)#设置邻居数K
knn.fit(X_train, Y_train)#构建基于训练集的模型
#测试评估模型
Y_pred=knn.predict(X_test)
print("Test set score:{:.2f}".format(knn.score(X_test, Y_test)))
# 做出预测,预测花萼长5cm宽2.9cm,花瓣长1cm宽0.2cm的花型
X_new = np.array([[5, 2.9, 1, 0.2]])
prediction = knn.predict(X_new)
print("Prediction:{}".format(prediction))
print("Predicted target name:{}".format(iris_dataset['target_names'][prediction]))
运行结果:

此外,KNN算法适合对稀有事件进行分类,特别适合于对象具有多个类别标签的多分类问题。但是,当样本不平衡时,如一个类的样本容量很大,而其他样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数,少数类容易分错;需要存储全部训练样本,计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。
参考链接:
深入浅出KNN算法:https://zhuanlan.zhihu.com/p/61341071.
用鸢尾花数据集实现knn分类算法: https://blog.csdn.net/qq_43407321/article/details/102531080.
原生Python实现KNN分类算法: https://www.huaweicloud.com/articles/f162bc2162a6052a787bf912f64d01fb.html.









 京公网安备 11010802041100号
京公网安备 11010802041100号