前言
朋友快过生日了,不知道送啥礼物【绝对不是因为我抠】,想着他非常喜欢打篮球,篮球他很多个了,应该也不会缺【不会是因为篮球贵】,那我就用技术白嫖点东西送给他吧,爬虫首当其冲呀,必须安排一波,于是我的灵感来了,爬取一波他喜欢的NBA球星图片送给他,再整点活合作一张大图,那效果不就出来了,这波真不错【辣条送礼物提示:送好朋友或者男女朋友礼物,不要只看价格,要看对方需要什么想要什么,礼轻情意重,主要是省钱…】
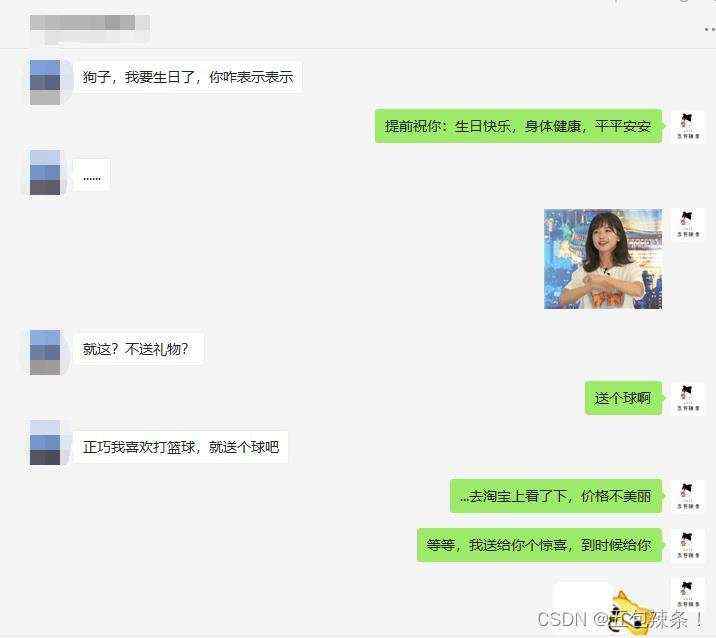
爬取目标
网址:百度一下
很多人学习蟒蛇,不知道从何学起。
很多人学习python,掌握了基本语法之后,不知道在哪里寻找案例上手。
很多已经做了案例的人,却不知道如何去学习更多高深的知识。
那么针对这三类人,我给大家提供一个好的学习平台,免费获取视频教程,电子书,以及课程的源代码!
QQ群:101677771
欢迎加入,一起讨论一起学习!
效果展示
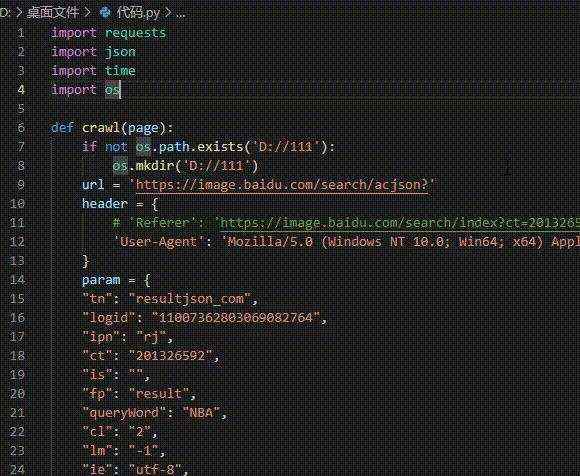
工具准备
开发工具:Visual Studio Code
开发环境:python3.7, Windows10
使用工具包:requests
项目解析思路
获取当当前网页的跳转地址,当前页面为主页面数据,我们需要的数据别有一番天地,获取到网页信息提取出所有的跳转地址,获取到源码里的a标签就行当前网页的加载方式为静态数据,直接请求网页地址;
url = \'https://image.baidu.com/search/acjson?
从源代码里提取到所以的跳转地址

【这是个很简单的代码,不做详细思路解析了,平台对爬虫的文章的审核比以前严格很多了,代码我留着,有啥不懂的评论提出,或者私信我,我看到了都会解答】
简易源码分享
import requests
import json
import time
import os
def crawl(page):
if not os.path.exists(\'D://111\'):
os.mkdir(\'D://111\')
url = \'https://image.baidu.com/search/acjson?\'
header =
# \'Referer\': \'https://image.baidu.com/search/index?ct=201326592&cl=2&st=-1&lm=-1&nc=1&ie=utf-8&tn=baiduimage&ipn=r&rps=1&pv=&fm=rs4&word\',
\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36\'
param =
"tn": "resultjson_com",
"logid": "11007362803069082764",
"ipn": "rj",
"ct": "201326592",
"is": "",
"fp": "result",
"queryWord": "NBA",
"cl": "2",
"lm": "-1",
"ie": "utf-8",
"oe": "utf-8",
"adpicid": "",
"st": "-1",
"z": "",
"ic": "",
"hd": "",
"latest": "",
"copyright": "",
"word": "NBA",
"s": "",
"se": "",
"tab": "",
"width": "",
"height": "",
"face": "0",
"istype": "2",
"qc": "",
"nc": "1",
"fr": "",
"expermode": "",
"force": "",
"pn": page,
"rn": "30",
"gsm": "1e",
"1615565977798": "",
response = requests.get(url, headers=header, params=param)
img = response.text
j = json.loads(img)
# print(j)
img_list = []
for i in j[\'data\']: #获得j字典数据里面的data所对应的值 值是一个列表 通过for循环拿去列表里的每一个元素
if \'thumbURL\' in i:
# print(i[\'thumbURL\'])
img_list.append(i[\'thumbURL\']) #追加到列表中
print(len(img_list)) #打印URL的数量
for count,n in enumerate(img_list):
r = requests.get(n, headers=header)
with open(f\'D://111/count+1.jpg\', \'wb\') as f:
f.write(r.content)
# count += 1
# if __name__ == \'__main__\':
for i in range(30, 61, 10): #起始值 终点值 步长
t1 = time.time()
crawl(i)
t2 = time.time()
t = t2 - t1
print(f\'page i//30 is over!!! 耗时t:.2f秒!\') #.2f两位小数
import requests
import json
import time
import os
def crawl(page):
if not os.path.exists(\'D://111\'):
os.mkdir(\'D://111\')
url = \'https://image.baidu.com/search/acjson?\'
header =
# \'Referer\': \'https://image.baidu.com/search/index?ct=201326592&cl=2&st=-1&lm=-1&nc=1&ie=utf-8&tn=baiduimage&ipn=r&rps=1&pv=&fm=rs4&word\',
\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36\'
param =
"tn": "resultjson_com",
"logid": "11007362803069082764",
"ipn": "rj",
"ct": "201326592",
"is": "",
"fp": "result",
"queryWord": "NBA",
"cl": "2",
"lm": "-1",
"ie": "utf-8",
"oe": "utf-8",
"adpicid": "",
"st": "-1",
"z": "",
"ic": "",
"hd": "",
"latest": "",
"copyright": "",
"word": "NBA",
"s": "",
"se": "",
"tab": "",
"width": "",
"height": "",
"face": "0",
"istype": "2",
"qc": "",
"nc": "1",
"fr": "",
"expermode": "",
"force": "",
"pn": page,
"rn": "30",
"gsm": "1e",
"1615565977798": "",
response = requests.get(url, headers=header, params=param)
img = response.text
j = json.loads(img)
# print(j)
img_list = []
for i in j[\'data\']: #获得j字典数据里面的data所对应的值 值是一个列表 通过for循环拿去列表里的每一个元素
if \'thumbURL\' in i:
# print(i[\'thumbURL\'])
img_list.append(i[\'thumbURL\']) #追加到列表中
print(len(img_list)) #打印URL的数量
for count,n in enumerate(img_list):
r = requests.get(n, headers=header)
with open(f\'D://111/count+1.jpg\', \'wb\') as f:
f.write(r.content)
# count += 1
# if __name__ == \'__main__\':
for i in range(30, 61, 10): #起始值 终点值 步长
t1 = time.time()
crawl(i)
t2 = time.time()
t = t2 - t1
print(f\'page i//30 is over!!! 耗时t:.2f秒!\') #.2f两位小数



![python的交互模式怎么输出名文汉字[python常见问题]](https://img1.php1.cn/3cd4a/24cea/978/9f39a0b333a15215.gif)







 京公网安备 11010802041100号
京公网安备 11010802041100号