作者:纠结大王烨要人陪往_763 | 来源:互联网 | 2023-08-14 15:53
本文由编程笔记#小编为大家整理,主要介绍了聊聊分布式链路追踪相关的知识,希望对你有一定的参考价值。原文链接:http://lidawn.github.io/2018/12/26
本文由编程笔记#小编为大家整理,主要介绍了聊聊分布式链路追踪相关的知识,希望对你有一定的参考价值。
原文链接:http://lidawn.github.io/2018/12/26/distribute-tracing/
起因
最近一直在做分布式链路追踪的调研和实践,整理一下其中的知识点。
什么是链路追踪
分布式系统变得日趋复杂,越来越多的组件开始走向分布式化,如微服务、分布式数据库、分布式缓存等,使得后台服务构成了一种复杂的分布式网络。在服务能力提升的同时,复杂的网络结构也使问题定位更加困难。在一个请求在经过诸多服务过程中,出现了某一个调用失败的情况,查询具体的异常由哪一个服务引起的就变得十分抓狂,问题定位和处理效率是也会非常低。
分布式链路追踪就是将一次分布式请求还原成调用链路,将一次分布式请求的调用情况集中展示,比如各个服务节点上的耗时、请求具体到达哪台机器上、每个服务节点的请求状态等等。
Dapper
目前业界的链路追踪系统,如Twitter的Zipkin,Uber的Jaeger,阿里的鹰眼,美团的Mtrace等都基本被启发于google发表的Dapper。 Dapper阐述了分布式系统,特别是微服务架构中链路追踪的概念、数据表示、埋点、传递、收集、存储与展示等技术细节。
Trace、Span、Annotations
为了实现链路追踪,dapper提出了trace,span,annotation的概念。
Trace的含义比较直观,就是链路,指一个请求经过后端所有服务的路径,可以用下面树状的图形表示。每一条链路都用一个全局唯一的traceid来标识。
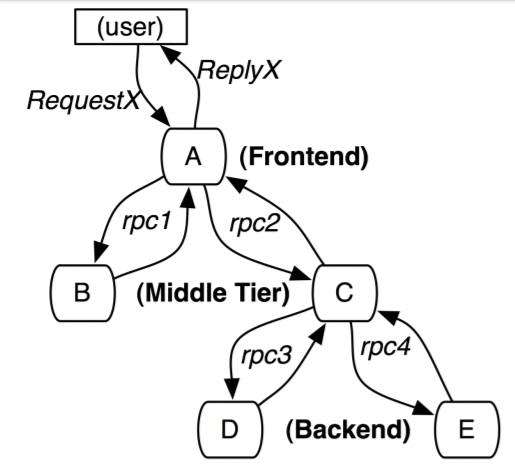
Span之间存在着父子关系,上游的span是下游的父span,例如图中"frontend.request"会调用"backend.dosomething","backend.dosomething"便成为"frontend.request"的子span。

链路中的rpc调用由span来表示,对应着树状图中的边,每个span由spanid和parentid来标识,spanid在一条链路中唯一。
下图是dapper论文中给出的一个"hepler.call"调用的span详解。
一个span一般由client和server两个部分的信息组成。按照时间顺序来解释,client节点(或者是调用方)首先发出请求,产生"client send"(cs)事件,紧接着server节点(或者是提供方)收到请求,产生"server receive"(sr)事件,server处理完成之后回复给client,产生"server send"事件,最后client收到回复,产生"client receive"事件。
Client与server两个节点的span信息合并成一次完整的调用,即一个完整的span。

Dapper中还定义了annotation的概念,用于用户自定义事件,如图二中的"foo",用来辅助定位问题。
值得一提的是,zipkin中把cs,cr,ss,sr这几个事件称之为annotation,而对应dapper中的annotation在zipkin v1的数据模型中被称之为binaryAnnotation。
带内数据与带外数据
链路信息的还原依赖于两种数据,一种是各个节点产生的事件,如cs,ss,称之为带外数据,这些数据可以由节点独立生成,并且需要集中上报到存储端。
另一种数据是traceid,spanid,parentid,用来标识trace,span,以及span在一个trace中的位置。这些数据需要从链路的起点一直传递到终点,称之为带内数据。 通过带内数据的传递,可以将一个链路的所有过程串起来;通过带外数据,可以在存储端分析更多链路的细节。
采样
由于每一个请求就会生成一个链路,为了减少性能消耗,避免存储资源的浪费,dapper并不会上报所有的span数据,而是使用采样的方式。通过采集端自适应地调整采样率,控制span上报的数量,可以在发现性能瓶颈的同时,有效减少性能损耗。采样率的概念在其他的追踪系统中也被广泛使用。在zipkin小节中将更具体阐述zipkin的采样机制。
存储
链路中的span数据经过收集和上报后会集中存储在一个地方,Dapper使用了BigTable数据仓库,如下图所示,由于每种trace的span个数不尽相同,使得BigTable稀疏表格布局很适合这种场景,并且分散的span进行存储时按照traceid和spanid便可以插入到对应的行列中,使得收集程序可以无需做任何计算且无状态。同时链路的查询也十分方便,即取表中的一行。

Zipkin
Zipkin是dapper的一种开源实现,也是业界做链路追踪系统的一个重要参考,其系统也可以即插即用。
架构
Zipkin的架构中包含Reporter,Transport,Colletor,Storage,API,UI几个部分。

其中Reporter集成在每个服务的代码中,负责Span的生成,带内数据(traceid等)的传递,带外数据(span)的上报,采样控制。
Transport部分为带外数据上报的通道,zipkin支持http和kafka两种方式。
Colletor负责接收带外数据,并插入到集中存储中。
Storage为存储组件,适配底层的存储系统,zipkin提供默认的in-memory存储,并支持mysql,Cassandra,ElasticSearch存储系统。
API提供查询、分析和上报链路的接口。接口的定义见zipkin-api。
UI用于展示页面展示。

Zipkin将Colletor/Storage/API/UI打包为jar包,可以直接下载运行。
数据模型
这里的数据模型为zipkin v2版本的数据模型。
Span
trace_id为16位或32位的hex字符串,id、parent_id为16位hex字符串, 如果没有父span,parent_id为空。
kind标识服务节点的类型,有通信模型,cs和生产者消费者模型。
name为span的名字,如rpc调用的名字。
timestamp为span生成的时间戳,微秒。
duration为span的持续时间,client端,即为cr-ss的时间。
local_endpoint为本地节点信息,包含节点名称,ip与端口。
remote_endpoint为远端节点信息。
annotations为事件列表,每个事件用事件时间戳和名字表示。
tags为用户自定义的kv信息,如{"user-id":"lidawn"}。
debug表示是否为调试,该选项会无视采样概率,使所有span上报。
shared这个字段暂时没有太理解==。
message Span {
bytes trace_id = 1;
bytes parent_id = 2;
bytes id = 3;
enum Kind {
SPAN_KIND_UNSPECIFIED = 0;
CLIENT = 1;
SERVER = 2;
PRODUCER = 3;
COnSUMER= 4;
}
Kind kind = 4;
string name = 5;
fixed64 timestamp = 6;
uint64 duration = 7;
Endpoint local_endpoint = 8;
Endpoint remote_endpoint = 9;
repeated Annotation annotatiOns= 10;
map tags = 11;
bool debug = 12;
bool shared = 13;
}
message Endpoint {
string service_name = 1;
bytes ipv4 = 2;
bytes ipv6 = 3;
int32 port = 4;
}
message Annotation {
fixed64 timestamp = 1;
string value = 2;
}
带内数据与采样机制
Zipkin中对带内数据的传递有更加详细的描述。带内数据被称为b3-propagation,包含TraceId,SpanId,ParentSpanId,Sampled四个字段,每个server在生成span之后会得到TraceId,SpanId,ParentSpanId,穿递到下游server之后,下游server可以知道自己接下来要生成的span属于哪一条trace,并处在trace的哪一个位置。
由于带内数据涉及到进程之间通信,所以一般是由框架来做带内数据传递,这样可以减少代码的侵入性。如果服务之间使用http通信,则可以使用X-开头的自定义http head来传递带内数据。或者如grpc框架,使用clientContext机制在调用之间传递自定义的字段。目前开源的zipkin客户端一般只支持http和grpc两种方式。
Zipkin的采样字段Sampled有四种状态Defer/Deny/Accept/Debug,采样的一个重要前提是下游要尊重上游的采样决定,不能随意更改sampled字段。
Defer代表该span的采样状态还未决定,下游收到该状态时则可以对sampled字段重新赋值。
Deny代表该span不上报。
Accept代表span需要上报。
Debug一般用于开发环境,强制上报。
Root_span的sampled字段由系统的采样率来决定。如采样率为50%,则一半的带内数据中sampled字段为accept,其他为deny。
数据埋点及上报过程
根据zipkin的span定义,模拟一个简单的调用过程,分析数据埋点和上报过程。

- server-1发起对server-2的调用,生成一个root_span, 生成trace_id,id,parent_id为空,并记录kind为CLIENT,name,timestamp,local_endpoint(server-1)信息,并将trace_id,id,parent_id,sampled信息传递给server-2。
- server-2收到server-1的请求,并收到trace_id,id,parent_id,sampled信息,生成一个相同的span,并记录kind为SERVER,name,timestamp,local_endpoint(server-2)信息。
- server-2发起对server-3的调用,生成一个新的span,该span为root_span的子span。 并记录kind为CLIENT,name,timestamp,local_endpoint(server-2)信息,并将trace_id,id,parent_id,sampled信息传递给server-3。
- server-3收到server-2的请求,并收到trace_id,id,parent_id,sampled信息,生成一个相同的span,并记录kind为SERVER,name,timestamp,local_endpoint(server-3)信息。
- server-3回复server-2的调用,记录duration,并上报span。
- server-2收到server-3的回复,记录duration,并上报span。
- server-2回复server-1的调用,记录duration,并上报span。
- server-1收到server-2的回复,记录duration,并上报span。
整个过程中上报4个临时的span,最终在zipkin中被合并和存储为两个span。
Open-Tracing
由于各种分布式追踪系统层出不穷,且有着相似的API语法,但各种语言的开发人员依然很难将他们各自的系统和特定的分布式追踪系统进行整合。在这种情况下,OpenTracing规范出现了。
OpenTracing通过提供平台无关、厂商无关的API,使得开发人员能够方便的添加(或更换)追踪系统的实现。OpenTracing通过定义的API,可实现将监控数据记录到一个可插拔的tracer上。
Opentracing api的定义可以查看中文文档, 其并没有具体的实现。对于现有的系统,如zipkin适配opentracing,则需要额外基于现有的client编写适配代码。
以上。
参考
- Zipkin - https://zipkin.io
- Dapper - https://storage.googleapis.com/pub-tools-public-publication-data/pdf/36356.pdf
- Jaeger - https://www.jaegertracing.io/
- 鹰眼 - https://cn.aliyun.com/aliware/news/monitoringsolution
- Mtrace - https://tech.meituan.com/mt_mtrace.html
- Zipkin-b3-propagation - https://github.com/openzipkin/b3-propagation
- Zipkin-api - https://zipkin.io/zipkin-api/#/default/post_spans
- Zipkin-proto - https://github.com/openzipkin/zipkin-api/blob/master/zipkin.proto
- OpenTracing - https://opentracing.io
- OpenTracing中文 - https://wu-sheng.gitbooks.io/opentracing-io/content/
原文链接:http://lidawn.github.io/2018/12/26/distribute-tracing/

![[译]技术公司十年经验的职场生涯回顾](https://img8.php1.cn/3cdc5/24912/711/b6574f3292f9dc00.png)




![[翻译]微服务设计模式5. 服务发现服务端服务发现](https://img7.php1.cn/3cdc5/ca23/525/3af55d7cf19345b9.jpeg)



 京公网安备 11010802041100号
京公网安备 11010802041100号