文章目录
- 1.前言
- 2.位图
- 2.1什么是位图
- 2.2实例分析
- 2.3位图的应用
- 2.4位图的实现
- 3.布隆过滤器
- 3.1布隆过滤器的提出
- 3.2布隆过滤器的概念
- 3.3布隆过滤器的应用
- 3.4布隆过滤器的设计
- 3.5布隆过滤器的优点
- 3.6布隆过滤器的缺陷
- 3.7代码实现
- 4.海量数据常见处理方式
1.前言
哈希是一种映射的思想,哈希表是基于这种思想的最常用的数据结构,除此之外,还有一些经常用到哈希思想的地方,下面进行介绍
2.位图
2.1什么是位图
所谓位图就是用每一位来存放某种状态,适用于海量的数据,数据无重复的场景。通常用来判断某个数据在或者不在的情况
2.2实例分析
给40亿个不重复的无符号整数,没有拍过序。给一个无符号整数,如何快速判断这一个整数是否在这40个亿之中?
这题给人直观的感觉就是,直接遍历全部数据,进行查找,对应的数字是否在这个集合之中。
但是40亿个数据,即40*4亿字节 = 16G,在一般的电脑上面,是行不通的,因此我们可以用到位图的思想
位图解决:
用40亿个比特位来标记所有的数字,1表示存在,0表示不存在。
40亿个比特位 = 2^32位 = 4G/8= 500M ,相比之下大大的节省了空间的消耗
2.3位图的应用
1.快速查找一个数据是否在一个集合之中
2.排序
3.求两个集合的交集、并集等等
4.操作系统中磁盘块的标记
优点:速度快,并且节省空间
缺点:只可以映射整形(如果有负数则开两个图,取反,映射到另外一个图)
2.4位图的实现
#pragma once
#include <iostream>
using namespace std;
#include
#include
namespace YCH_BITSET
{
template//非类型模板参数
class BitSet
{
public:
BitSet()
{
_bit.resize((N >> 3)&#43;1, 0);//一个字节&#xff0c;8个比特位,多开一个&#xff0c;有余数
}
//将比特位置为1
void set(size_t pos)
{
assert(pos <&#61; N);
size_t index &#61; pos >> 3;
size_t num &#61; pos % 8;
_bit[index] |&#61; (1 < }
//将比特位置为0
void reset(size_t pos)
{
assert(pos <&#61; N);
size_t index &#61; pos >> 3;
size_t num &#61; pos % 8;
_bit[index] &&#61; ~(1 < }
//查找在不在
bool test(size_t pos)
{
assert(pos <&#61; N);
size_t index &#61; pos >> 3;
size_t num &#61; pos % 8;
return _bit[index] & (1 < }
private:
vector_bit;
};
};
#include "bitset.h"
void test()
{
YCH_BITSET::BitSet<100> bt;
bt.set(1);
bt.set(2);
bt.set(3);
bt.set(99);
bt.set(100);
cout < cout < bt.reset(99);
cout < cout <}
int main()
{
test();
system("pause");
return 0;
}

3.布隆过滤器
3.1布隆过滤器的提出
比如我们在看新闻的时候&#xff0c;服务器会自动筛选剔除出已经被用户看过的新闻&#xff0c;服务器是如何快速查找&#xff0c;过滤掉已经存在的记录呢&#xff1f;
1.用哈希表存储用户记录(浪费空间)
2.用位图存储用户记录(只可映射整形&#xff0c;就算将类型转换成整形&#xff0c;也无法处理哈希冲突)
3.将哈希与位图结合就是布隆过滤器
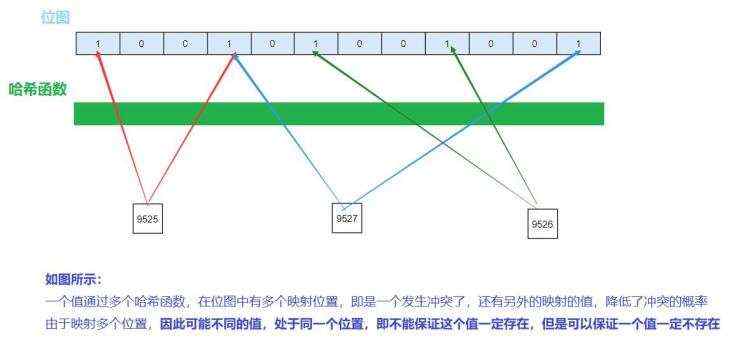
3.2布隆过滤器的概念
布隆过滤器是由布隆在1970年提出来的&#xff0c;它的特点是比较高效的告诉你&#xff0c;某样东西一定不存在或者可能存在&#xff0c;它采用的方法是&#xff0c;用多个哈希函数&#xff0c;将一个数据映射到位图之中&#xff0c;这种方式不仅可以提高查询效率&#xff0c;还可以节省大量的空间
3.3布隆过滤器的应用
布隆过滤器通常应用在允许误判的场景之中
1.垃圾邮件的过滤&#xff1a;
邮箱内经常有垃圾邮件&#xff0c;这时可以运用布隆过滤器将其进行几率&#xff0c;下次再收到邮件进行O(1)的查找即可&#xff0c;即是误判了&#xff0c;影响也不是很大
2.身份验证&#xff1a;
大门口的身份验证&#xff0c;如果不是小区里面的人&#xff0c;直接就拒绝进入(不在是确定的)&#xff0c;如果通过了布隆过滤器的判断&#xff0c;再去数据库中对比一次&#xff0c;这样通过一层布隆过滤器可以提高这个查找系统的效率
3.4布隆过滤器的设计
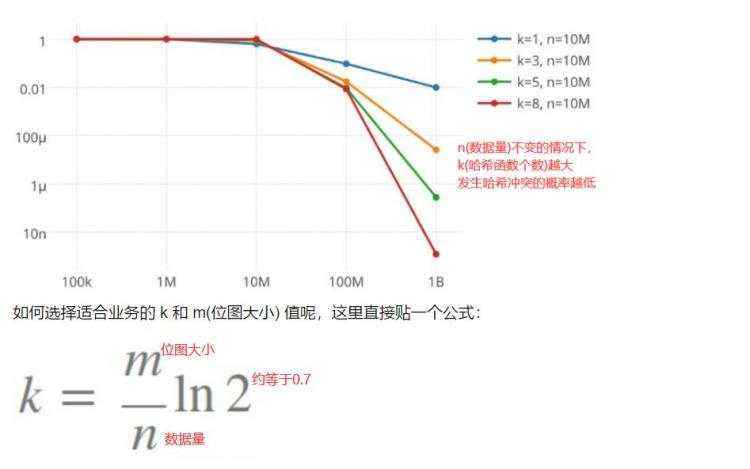
1.选择合适的位图大小
2.插入
将每个哈希函数映射的位置都置为1
3.查找
所有的哈希函数映射的位置之中&#xff0c;只要有一个映射的位置为0&#xff0c;即当前值不存在&#xff0c;因为在插入的时候&#xff0c;所有的位置都设置为了1(所以不存在是准确的)&#xff0c;否则表示存在(不准确&#xff0c;可能发生哈希冲突&#xff0c;是其它值映射的)
4.删除
**布隆过滤器不支持删除工作&#xff0c;**因为不确定当前位置&#xff0c;是自己的&#xff0c;还是发生了哈希冲突其它的值映射过来的
一种"略微"支持删除的方法:
给定一个计数器(多给比特位&#xff0c;即多给几张图)&#xff0c;插入元素的时候&#xff0c;计数器&#43;1&#xff0c;删除元素计数器-1&#xff1b;
但是这种方法也不好&#xff0c;因为计数器的大小不易确定&#xff0c;如果给小了&#xff0c;发生冲突会导致溢出(计数回绕&#xff0c;最大值-> 最小值)
如果给大了&#xff0c;浪费空间&#xff0c;脱离了布隆过滤器的本质思想。 所以一般的布隆过滤器是不支持删除操作的
3.5布隆过滤器的优点
1.增加和查询元素的时间复杂度为O(K),(K为哈希元素的个数&#xff0c;一般比较小)&#xff0c;与数据量无关
2.哈希哈函数相互之间没有关系&#xff0c;方便硬件进行计算
3.布隆过滤器不需要存储元素本身&#xff0c;在某些对保密要求比较严格的场合有较大优势
4.在能够承受一定误判的情况之下&#xff0c;布隆过滤器比其他的数据结构有着很大的空间优势
5.在数据量很大时&#xff0c;布隆过滤器可以表示全集&#xff0c;其他数据结构不行(位图只能表示整形)
6.使用同一组散列函数的布隆过滤器可以进行交、并、差运算
3.6布隆过滤器的缺陷
1.有误判&#xff0c;不能准确的判断元素是否在集合之中(补救方法&#xff1a;再建立一个白名单&#xff0c;存储可能会出现误判的数据)
2.不能获取元素本身
3.一般情况之下&#xff0c;不能从布隆过滤器删除元素
4.如果采用计数方式删除&#xff0c;可能会出现计数回绕问题
3.7代码实现
#pragma once
#include
using namespace std;
#include
#include
namespace YCH_BITSET
{
class BitSet
{
public:
BitSet(size_t N)
{
_bit.resize((N >> 3)&#43;1, 0);
}
void set(size_t pos)
{
size_t index &#61; pos >> 3;
size_t num &#61; pos % 8;
_bit[index] |&#61; (1 << num);
}
void reset(size_t pos)
{
size_t index &#61; pos >> 3;
size_t num &#61; pos % 8;
_bit[index] &&#61; ~(1 << num);
}
bool test(size_t pos)
{
size_t index &#61; pos >> 3;
size_t num &#61; pos % 8;
return _bit[index] & (1 << num);
}
private:
vector<char>_bit;
};
template<class T, class hash1,class hash2,class hash3 >
class BloomFilter
{
public:
BloomFilter(size_t range)
:_count(5*range)
,_bitset(_count)
{}
void set(const T&t)
{
hash1 hs1;
hash2 hs2;
hash3 hs3;
size_t pos1 &#61; hs1(t);
size_t pos2 &#61; hs2(t);
size_t pos3 &#61; hs3(t);
_bitset.set(pos1%_count);
_bitset.set(pos2%_count);
_bitset.set(pos3%_count);
}
bool test(const T&t)
{
hash1 hs1;
size_t pos1 &#61; hs1(t);
if (!_bitset.test(pos1%_count))
return false;
hash1 hs2;
size_t pos2 &#61; hs2(t);
if (!_bitset.test(pos2%_count))
return false;
hash1 hs3;
size_t pos3 &#61; hs3(t);
if (!_bitset.test(pos3%_count))
return false;
return true;
}
private:
size_t _count;
BitSet _bitset;
};
};
测试&#xff1a;
#include "bitset.h"
struct hash1
{
size_t operator()(const string &s)
{
size_t num &#61; 0;
for (auto&e:s)
{
num &#61; num*131 &#43; e;
}
return num;
}
};
struct hash2
{
size_t operator()(const string &s)
{
size_t num &#61; 0;
for (auto&e : s)
{
num &#61; num * 65699 &#43; e;
}
return num;
}
};
struct hash3
{
size_t operator()(const string &s)
{
size_t num &#61; 0;
for (auto&e : s)
{
num &#61; num * 7642 &#43; e;
}
return num;
}
};
void test()
{
YCH_BITSET::BloomFilter<string, hash1, hash2, hash3> bf(100);
bf.set("https://editor.csdn.net/md?not_checkout&#61;1&articleId&#61;117885817");
bf.set("https://editor.csdn.net/md?not_checkout&#61;1&articleId&#61;117885818");
bf.set("https://editor.csdn.net/md?not_checkout&#61;1&articleId&#61;117885819");
cout << bf.test("https://editor.csdn.net/md?not_checkout&#61;1&articleId&#61;117885817") << endl;
cout << bf.test("https://editor.csdn.net/md?not_checkout&#61;1&articleId&#61;117885818") << endl;
cout << bf.test("https://editor.csdn.net/md?not_checkout&#61;1&articleId&#61;117885819") << endl;
cout << bf.test("https://editor.csdn.net/md?not_checkout&#61;1&articleId&#61;117885820") << endl;
cout << bf.test("https://editor.csdn.net/md?not_checkout&#61;1&articleId&#61;117885821") << endl;
}
int main()
{
test();
system("pause");
return 0;
}

4.海量数据常见处理方式
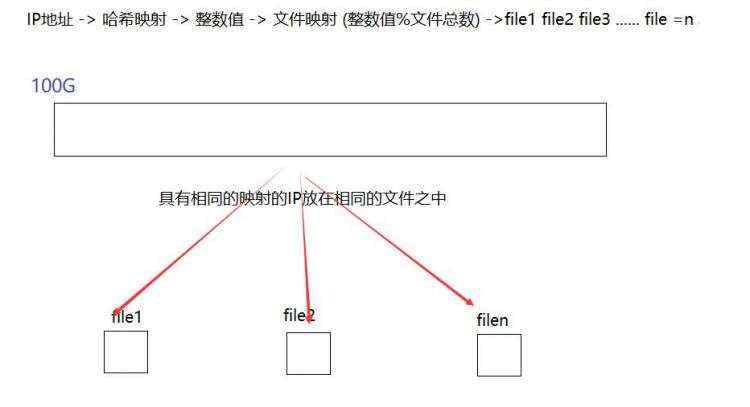
1.给一个超过100G大小的log file, log中存着IP地址, 设计算法找到出现次数最多的IP地址&#xff1f; 与上题条件相同&#xff0c;如何找到top K的IP&#xff1f;
可以采用哈希切割的办法&#xff0c;将这个大文件&#xff0c;分成多个小文件。通过哈希函数&#xff0c;映射成一个个的整数&#xff0c;整数%小文件的总数 &#61; 小文件的编号
切割好后&#xff0c;直接对小文件进行操作即可。由于相同的IP地址&#xff0c;映射出来的值都是一样的&#xff0c;因此最终都会在同一个小文件之中
2. 给定100亿个整数&#xff0c;设计算法找到只出现一次的整数&#xff1f;
只出现一次&#xff0c;通过位图表示即可&#xff0c;当设置位图的时候&#xff0c;如果为0&#xff0c;就是只出现一次&#xff0c;如果为1&#xff0c;就代表出现了多次
3.给两个文件&#xff0c;分别有100亿个整数&#xff0c;我们只有1G内存&#xff0c;如何找到两个文件交集&#xff1f;
用两个位图分别存储两个文件之中的整形&#xff0c;然后取它们的交集
4.位图应用变形&#xff1a;1个文件有100亿个int&#xff0c;1G内存&#xff0c;设计算法找到出现次数不超过2次的所有整数
用两个位图进行存储&#xff0c;(0,0)表示出现0次&#xff0c;(1,0)表示出现1次&#xff0c;(0,1)表示出现两次&#xff0c;(1,1)表示出现多次
5.给两个文件&#xff0c;分别有100亿个query&#xff0c;我们只有1G内存&#xff0c;如何找到两个文件交集&#xff1f;分别给出精确算法和近似算法
近似算法&#xff1a;每个请求都保存在布隆过滤器之中&#xff0c;然后进行交集处理
精确算法&#xff1a;哈希切割
6.如何扩展BloomFilter使得它支持删除元素的操作
给定一个计数器&#xff0c;但是会也有缺陷&#xff0c;比如计数回绕&#xff0c;空间浪费等等










 京公网安备 11010802041100号
京公网安备 11010802041100号