作者:逝水无痕-- | 来源:互联网 | 2023-05-27 15:07
篇首语:本文由编程笔记#小编为大家整理,主要介绍了Solr文本分析剖析文本分析分词器详解自定义文本分析字段及分词器相关的知识,希望对你有一定的参考价值。 一.概述 Solr文本分析消除了索引词项与用
篇首语:本文由编程笔记#小编为大家整理,主要介绍了Solr文本分析剖析文本分析分词器详解自定义文本分析字段及分词器相关的知识,希望对你有一定的参考价值。
一.概述
Solr文本分析消除了索引词项与用户搜索词项之间的语言差异,让用户在搜索buying a new house时能找到类似的内容,例如:purchasing a new home这样的文档。如果搭配恰当,文本分析就能允许用户使用自然语言进行搜索,而无需考虑搜索词项的所有可能形式。毕竟谁也不想看到为了相似搜索而构造这样的查询表达式:buying house OR purchase home OR buying a home OR purchasing a house ...。
用户可以使用自然语言来搜索他们需要的重要的信息,这是提供良好搜索体验的基础。鉴于Google或百度等搜索引擎的广泛使用,用户往往会期望搜索引擎非常智能,而搜索引擎的智能化就是从优秀的文本分析开始的。文本分析不仅用于消除词项之间的表面差异,还用来解决更复杂的问题,例如:特定语种解析、部分词性标注与词性还原等。
Solr包含一个文本分析可扩展框架,可以移除常见词汇【也就是停用词】,以及执行其他更复杂的文本分析任务。Solr文本分析框架提供了强大的功能与灵活的扩展性,但对于初学者来说,这个框架过于复杂,使人望而却步。这就是我们说的事物具有两面性,Solr有可能解决非常复杂的文本分析问题,但也可能使原来非常简单的分析任务变的很麻烦。Solr在schema.xml文件中预置了许多字段类型,用于确保初学者在接触开箱即用的Solr时,能较容易地开始使用文本分析。
二.微博案例分析
当我们要设计与实现一个大众社交媒体网站【类似微博、Twitter】的微博内容搜索解决方案。因为要聚焦到微博的内容,这将重点聚焦到文本分析,所以先了解微博文档的文本字段。一下是打算分析的文本。
elasticsearch and Solr is highly reliable, scalable and fault tolerant, providing distributed indexing, replication and load-balanced querying, automated failover and recovery, centralized configuration and more. Solr powers the search and navigation features of many of the world‘s largest internet sites.
正如上面所述,文本分析的主要目标是让用户使用自然语言进行搜索,无须考虑词项的所有可能的表达形式。当用户想搜索solr index时,这是一个自然语言查询,用户期望找到包含solr和index的数据,这只会精确匹配,上面的indexing就匹配不上。下面是分词器的分词结果:
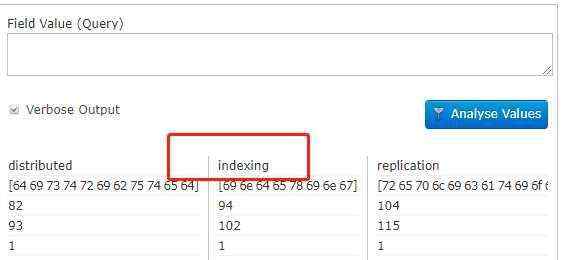
因此,摆在我们面前的任务是,使用solr文本分析框架将微博文本转换为一种易于寻找的形式。
三.基础文本分析
schema.xml的部分使用元素定义了文档中所有可能的字段,每个定义了字段的格式,以及在索引与查询中该字段如何进行分析。上面使用的分词器就是solr自带的text_general字段类型进行的分词,这是一种较为简单的字段类型,如下:
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.LowerCaseFilterFactory"/>
analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymGraphFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
analyzer>
fieldType>
1.分析器
在元素中至少定义一个,以确定如何分析文本。常见的做法是定义两个单独的元素,一个用于分析索引时的文本,一个用于分析用户搜索时输入的文本【如上面的text_general】。对于为什么使用两个而不是共用一个,很明显,对于索引文档和查询处理进行文本分析,后者往往需要进行更多的分析。例如,查询的文本分析中通常会添加同义词,而索引的文本分析不会这样做,因为同义词会增大索引体积。因此,这样处理一般放在查询处理中。
虽然定义两个单独的分析器,但查询词项的分析器必须兼容索引时的文本分析方法【例如,必须使用相同的分词器,不同分词器分相同的文本,分出的词可能不同,这会导致无法查询】。
2.分词器
在Solr中,每个将文本分析过程分为两个阶段:词语切分和词语过滤。严格来说,还有第三个阶段,即词语切分之前的预处理阶段,这个阶段可以使用字符过滤器。在词语切分阶段,文本会以各种解析形式被拆分为词元流。WhitespaceTokenizer是最基本的分词器,仅使用空格拆分文本。StandardTokenizer则更常见,它使用空格和标点符号拆分出词项,而且可用于处理网址、电子邮件和缩写词。分词器的定义需要指定Java实现的工厂类。要使用常见的StandardTokenizer,需要指定分词器的类为solr.StandardTokenizerFactory,参考上面的text_general字段。
在Solr中,因为大多数分词器需要提供参数构造器,所以必须指定为工厂类,而不是底层的分词器实现类。通过使用工厂方法,Solr提供了在XML中定义分词器的标准做法。在后台,每个工厂类知道如何将XML配置属性翻译为构造特定分词器实现类的一个实例。所有分词器会生成词元流,可以使用过滤器进行处理,执行词元的某种转换。
3.分词过滤器
分词过滤器对词元执行以下三种操作中的一种:
1.词元转换
改变词元的形式,例如,所有字母小写或词干提取。
2.词元注入
向词元流中添加一个词元,例如,同义词过滤器的做法。
3.词元移除
删除不需要的词元,例如,停用词过滤器的做法。
过滤器可以同时使用,对词元进行一系列的转换处理。过滤器的顺序很重要,排在前面的过滤器会先起作用。
4.StandardTokenizer
文本分析的第一步是确定如何使用分词器将文本解析为词元流。从StandardTokenizer的使用开始,这个分词器是许多Solr和Lucene项目的首选解决方案,这个分词器使用空格和标点符号来拆分文本。下面我们通过案例来看看这个分词器的作用:

备注:ST代表StandardTokenizer标准分词器,SF代表StopFilterFactory停止词过滤器,LCF代表LowerCaseFilterFactory转换小写过滤器。
5.StopFilterFactory
Solr进行文本分析时会使用停止词过滤器移除词元流中的停用词,这些停用词对用户查找相关文档几乎没有价值。在索引时移除停用词会有效减少索引大小,提供搜索性能。这样做减少了Solr将要处理的文档数据数量,也减少了对包含停用词的查询进行相关度计算时的词项数量。
停用词过滤器默认指定了一个英语停用词列表【words="stopwords.txt"】。Solr开箱即用,它提供了基础的停用词列表,在此基础上可以根据需求 自定义停用词。一般而言,停止词移除具有语言专属性。不同的语言,停止词一般不同,如果分析德语,就需要一个包含die、ein这样词项的停用词列表。Solr提供多种语言的停用词列表定制文件,它们位于Solr各个内核的conf/lang/目录下。

注意:在新版本的solr中,没有使用lang/目录下的停止词配置文件,而是直接使用的当前目录下的stopwords.txt,且其中默认没有配置任何停止词!
6.LowerCaseFilterFactory
LCF将词元的所有字母转换为小写,这样一来,词元的大小写就不会对索引和搜索产生干扰。
与停用词的情况类似,是否需要对所有词项使用小写转换过滤器有时并不好判断。举例来说,一句话中间的单词首字母大写通常表示一个专有名词。如果用户按照专有名词格式进行搜索,搜索结果的准确性就会有所提升。但对于习惯都是小写搜索的用户来说,这样就不太友好。因此,是否使用停止词要看是看中准确性还是适应性。
四.自定义文本分析字段
由于Solr预定义的字段类型无法满足我们的所有需求,因此通过综合使用其它Solr内置文本分析工具来解决这些问题。因此,我们在schema.xml中定义一个新字段类型。在managed-schema.xml的元素下增加text_microblog字段,代码如下:
<fieldType name="text_microblog" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<charFilter class="solr.PatternReplaceCharFilterFactory" pattern="([a-zA-Z])1+" replacement="$1$1"/>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" splitOnCaseChange="0"
splitOnNumerics="0"
stemEnglishPossessive="1"
preserveOriginal="0"
catenateWords="1"
generateNumberParts="1"
catenateNumbers="0"
catenateAll="0"
types="wdfftypes.txt"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.ASCIIFoldingFilterFactory"/>
<filter class="solr.KStemFilterFactory"/>
analyzer>
<analyzer type="query">
<charFilter class="solr.PatternReplaceCharFilterFactory" pattern="([a-zA-Z])1+" replacement="$1$1"/>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" splitOnCaseChange="0"
splitOnNumerics="0"
stemEnglishPossessive="1"
preserveOriginal="0"
catenateWords="1"
generateNumberParts="1"
catenateNumbers="0"
catenateAll="0"
types="wdfftypes.txt"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.ASCIIFoldingFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.KStemFilterFactory"/>
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
analyzer>
fieldType>
备注:

1.PatternReplaceCharFilterFactory
在Solr中,传入的字符流在分词处理之前,字符过滤器对其进行预处理。与分词过滤器类似,CharFilters作为过滤链的一环,可以对文本字符进行添加、修改和移除。Solr三个常用的CharFilters如下:
1.1 solr.MappingCharFilterFactory:使用外部配置文件进行字符替换。
1.2 solr.PatternReplaceCharFilterFactory:使用正则表达式进行字符替换。
1.3 solr.htmlStripCharFilterFactory:从文本中去除HTML标记。
2.WordDelimiterFilterFactory
该过滤器在更高层面上使用各种解析规则,将分词单元变为子词【subwords】。在上面定义的自定义文本分析字段中可知,该过滤器需配置wdfftypes.txt配置文件,这个文件需要自己创建,里面的内容需要根据实际情况进行填写,此处内容为:

这些设置将-映射到ALPHA类,这意味着WordDelimiterFilter实例就不会把它们作为分隔符。效果如下:

WordDelimiterFilterFactory的配置选项及解释如下:

3.ASCIIFoldingFilterFactory移除变音符号
,最好在小写过滤器之后使用此过滤器,这样只需处理小写字符。ASCIIFoldingFilter仅适用于拉丁字符,其它语种请使用solr.analusis.ICUFoldingFilterFactory,这个工厂方法在Solr3.1之后的版本可用。
4.KStemFilterFactory提取词干
词干提取根据特定语言规则,将词转换为基础词形。Solr提供了许多词干提取过滤器,每种各有优缺点。KStemFilterFactory与PorterStemmer等其它流行的词干提取器相比,这个词干提取器的转换并不是那么激进。这里使用是为了对indexing和querying等这样的词项移除ing。
5.SynonymFilterFactory同义词
在大多数情况下,同义词的添加只用于查询阶段的分析。这样做有助于减少索引的大小,同义词列表的变更维护也更容易一点。另外,还要考虑其在过滤器链中所处的位置,通常最有用的做法是,将这个过滤器作为查询分析器的最后一个,以便使同义词列表可以认为分词单元上的所有其他转换都已经做完。
五.高级文本分析【自定义分词器】
1.高级字段属性


2.使用Solr插件扩展文本分析
2.1自定义TokenFilter类

2.2自定义TokenFilterFactory类


备注:要想使用自定义分词器,必须把对应的程序打包上传到solr中,并在对应core的solrconfig.xml中指定配置!









 京公网安备 11010802041100号
京公网安备 11010802041100号