作者:霸气胡志刚_你活埋了木有 | 来源:互联网 | 2023-06-11 11:37
本地LEO和RemoteLEOKafka分区的follower副本的LEO属性保存了两份:本地LEO:在follower副本所在broker的缓存中保存一份RemoteLEO:在l
本地LEO和Remote LEO
Kafka分区的follower副本的LEO属性保存了两份:
- 本地LEO:在follower副本所在broker的缓存中保存一份
- Remote LEO:在leader副本所在的broker的缓存中保存一份(Remote LEO)
本地LEO很简单,就是follower本地日志文件的LEO,即它向leader发送FETCH请求得到结果后写入log文件时,该LEO增加。
Remote LEO在leader接收到follower的FETCH请求后,读取自己的log文件,返回给follower之前更新。
保存两份LEO是为分区HW在主从间的更新服务
HW更新机制
follower HW更新机制
follower在更新LEO之后更新HW。
leader在FETCH响应中会提供自己的HW,也就是分区HW,分区HW受分区ISR中所有主从节点的写入情况限制,follower要保证自己的HW不超过分区HW,所以,follower会选择当前自己的LEO和leader的HW值中最小的那个。
当follower同步的比其它从节点快时,其它从节点的LEO可能比它小,这时它不能简单的将自己的LEO设置为高水位
leader HW更新机制
leader在下面四种情况下更新HW
- 自己刚刚成为leader副本时
- 有broker发生崩溃导致某副本被踢出ISR
- producer向leader副本写入消息时
- leader处理follower FETCH请求时
leader更新HW是在所有满足要求的副本中取最小的LEO作为它的HW,因为leader保存了所有副本的Remote LEO,所以它可以做到。
上面所说的满足要求,就是要最少满足下面两个条件的其中一个:
- 副本处于ISR中
- 副本落后于leader LEO的时间不大于
replica.lag.time.max.ms参数
第二点是为了那些已经追上leader进度但尚未进入ISR(比如刚从故障中恢复的节点)考虑的,它们稍后就会进入ISR,如果不考虑它们,并且在下次leader更新HW之前,它们进入ISR,那它们的LEO值就不在此次HW的考虑范围内,万一它是ISR中最小的LEO,那就出现HW超过ISR分区最小LEO的情况了。
假设1:Producer发送消息到topic
当前,所有leader和follower的LEO=0
- leader收到消息,写入底层日志,更新自己的LEO属性=1
- leader尝试更新HW,所有follower的LEO为0,HW为0
- follower发送FETCH请求
- leader读取底层日志,更新Remote LEO为
0,因为follower尚未收到该日志。
- leader尝试更新HW,LEO=1,Remote LEO=0,分区HW值=0
- leader将消息返回给follower,携带分区HW为0
- follower接收到响应,写入日志,更新自己的LEO为1,
HW=Math.min(self.LEO, partition.HW)=0
第一轮结束,leader.LEO = 1, leader.HW=0, remote.leo = 0, follower.leo = 1, follower.HW = 0
注意,在第一轮中,leader尚不能确定follower已经成功写入消息,它不知道follower的leo已经为1,所以HW还是0。
开始第二轮
- follower再次FETCH消息,携带自己的offset,也就是自己的LEO=1
- leader读取log文件,根据FETCH携带的offset更新它的remote LEO=1
- leader更新分区HW为1
- leader将消息返回给follower(如果这期间没有新消息,就是空),并携带分区HW=1
- follower接收到响应,更新自己的LEO,并且设置自己的HW为1
这展示了HW的一个弊端,就是leader得在follower成功写入后的下一次请求时才能知道它成功写入了,而follower要在成功写入的下一次请求的响应中才能更新自己的HW,这引发了两个问题。
Kafka的分区宕机重启后,会将HW作为新的LEO,然后做日志截断,即将HW后面的全扔掉,问题就出在这里,分区自己的HW时不可靠的,时任leader的状态才可靠。
消息丢失
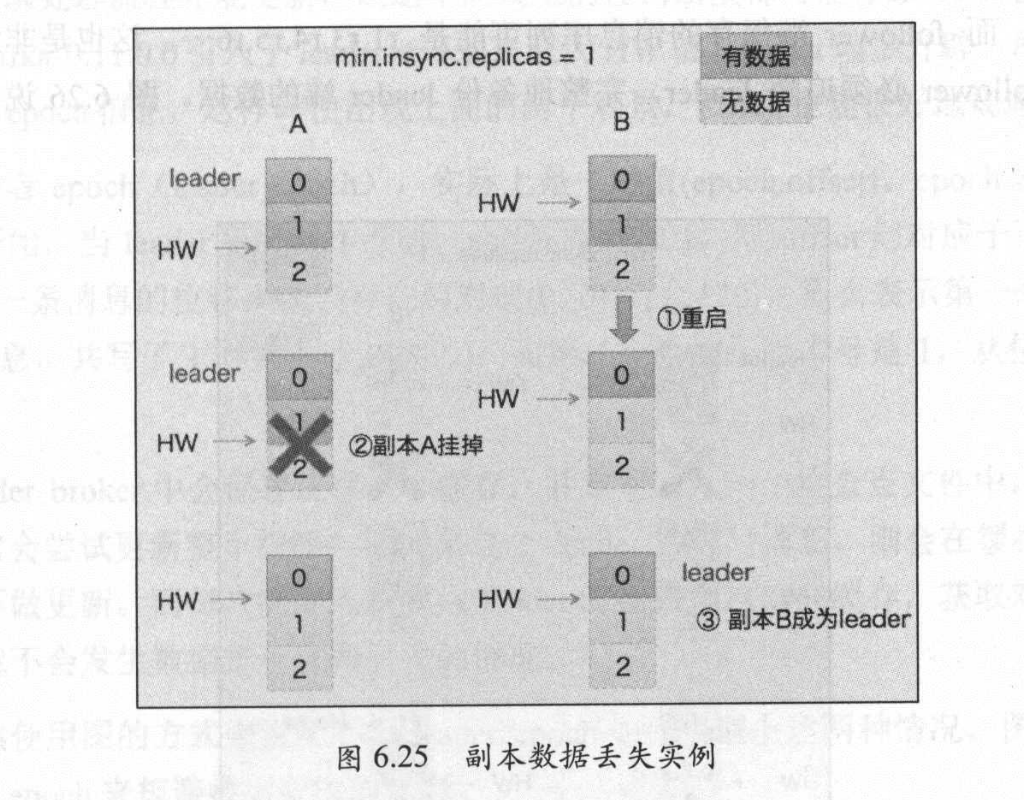
如上图,假设A接到了两条消息,A和B虽然都已经写入,LEO=2(注意LEO是下一条消息的写入位置),但B的HW还是0,因为它要等到A做完消息1的FETCH响应后才能更新HW。
假设这时,B宕机重启,它的LEO会被设置成1,消息1被丢弃,而此时,副本A又挂了,B成为了新的Leader,消息1就永远丢失了。
消息顺序错乱
由于原书的黑白印刷导致图片展示不清晰,这里选了网上的其它图片
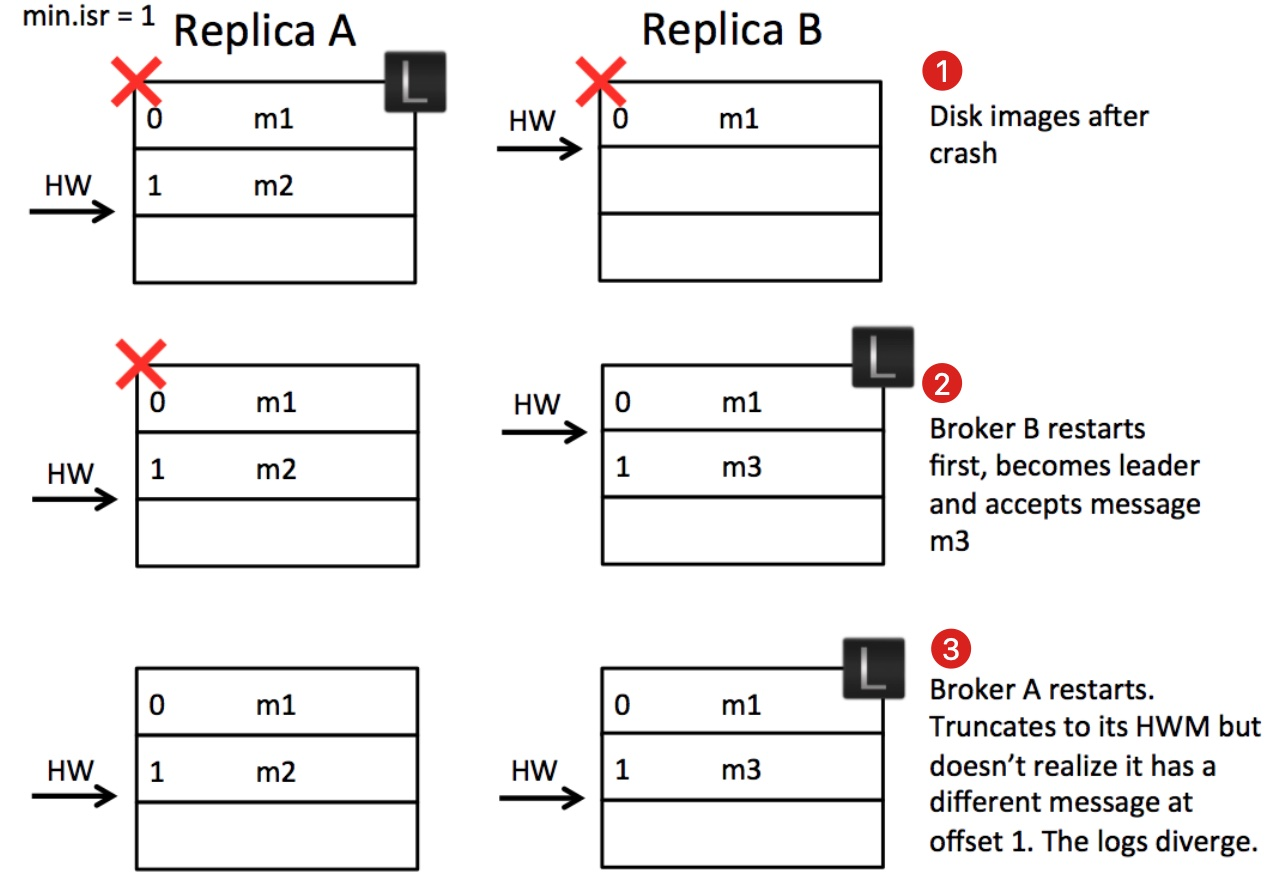
假设A和B一同宕机(已经没有可用的副本了,Kafka无需保证消息可靠性),A作为原leader,它的HW是1,B作为原follower,它的HW是0。
若此时重启后,B做了leader,并且它接收新消息m3,并更新自己的HW为1,此时A重启做了follower,A根据自己的HW对消息进行截断,显然它不用截断,此时,B和A的HW都为2,看似一切正常,但实际上offset为1的消息已经不是同一条了。
上图的第一个状态好像不可能发生,因为只有当B实际写入了m2后A才会更新自己的HW。但存在B写入到pagecache但未刷盘的情况。
Leader Epoch
Leader Epoch用于解决上面的问题。
Epoch,可以被翻译为纪元、时期...一次leader更换,就看作一个Leader Epoch。
Leader Epoch是一个(epoch, offset)的二元组,epoch是一个整数,代表自己的代,比如第一个leader的epoch是0,下一个选举出来的leader的epoch是1,offset代表该版本Leader写入第一条消息的位移。
第一个leader的Epoch肯定是(0, 0),假设现在有第二个leader,它的Epoch是(1, 120),则代表它是从offset 120位置开始写的消息,这也就证明第一个leader写入了[0, 199]这些消息。Kafka Broker会在内存中为每个分区缓存Leader Epoch数据,同时还会定期的将它们持久化到checkpoint文件中。
当一个follower副本宕机重启时,它会向leader发起一个LeaderEpochRequest,并携带自己所处的纪元,如果请求的纪元就是leader所在的纪元,leader就返回自己的LEO,否则返回follower所在纪元的下一个纪元的start offset(即它所在纪元的leader最后写入的消息位置)
follower使用这个返回值来截断自己的消息,而非自己的HW。此时再看上面两个问题
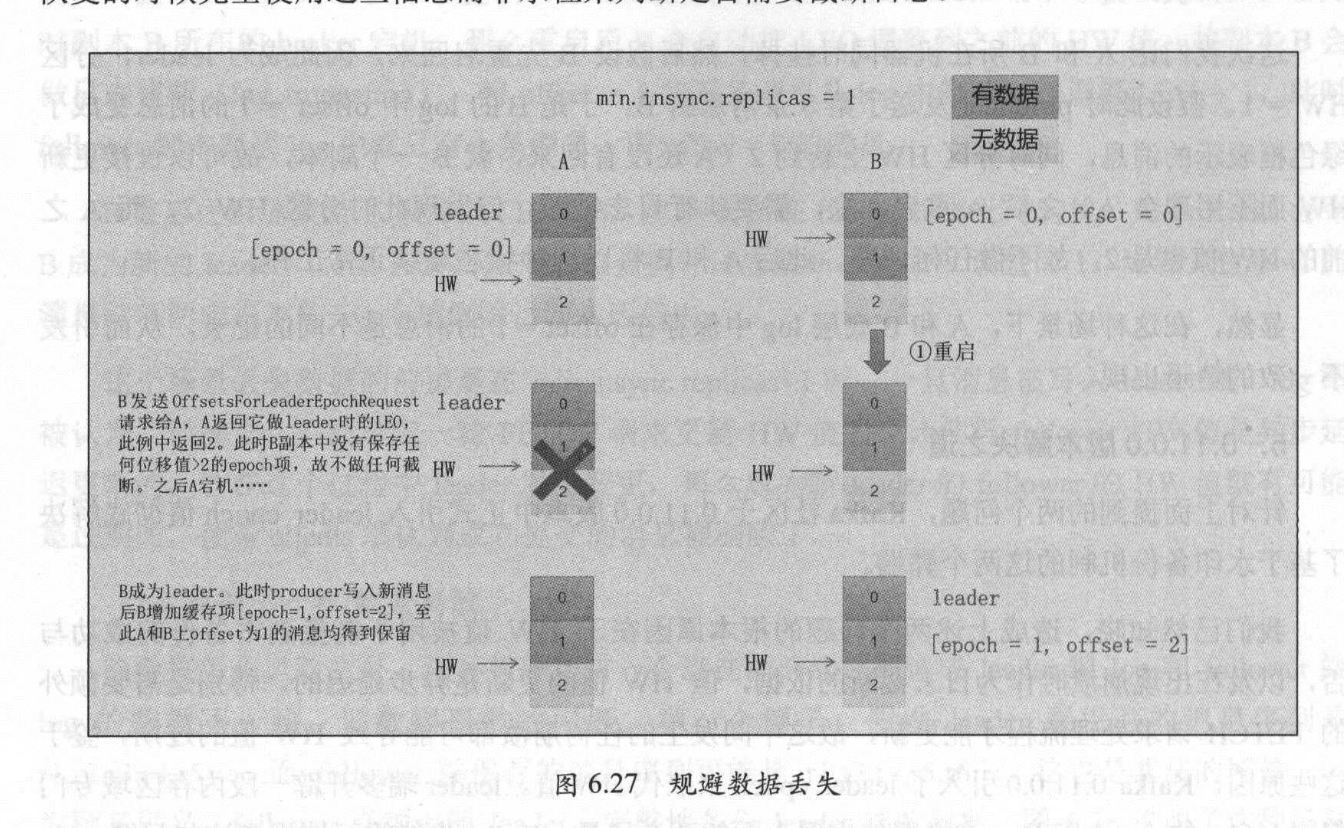
第一个问题,由于B重启后发送请求给leader,leader与它在同一个epoch,所以,直接返回自己的LEO,也就是2,B不用做任何截断,此时A宕机,B成为leader,在Producer首次写入新消息时增加自己的缓存项[epoch=1, offset=2]。
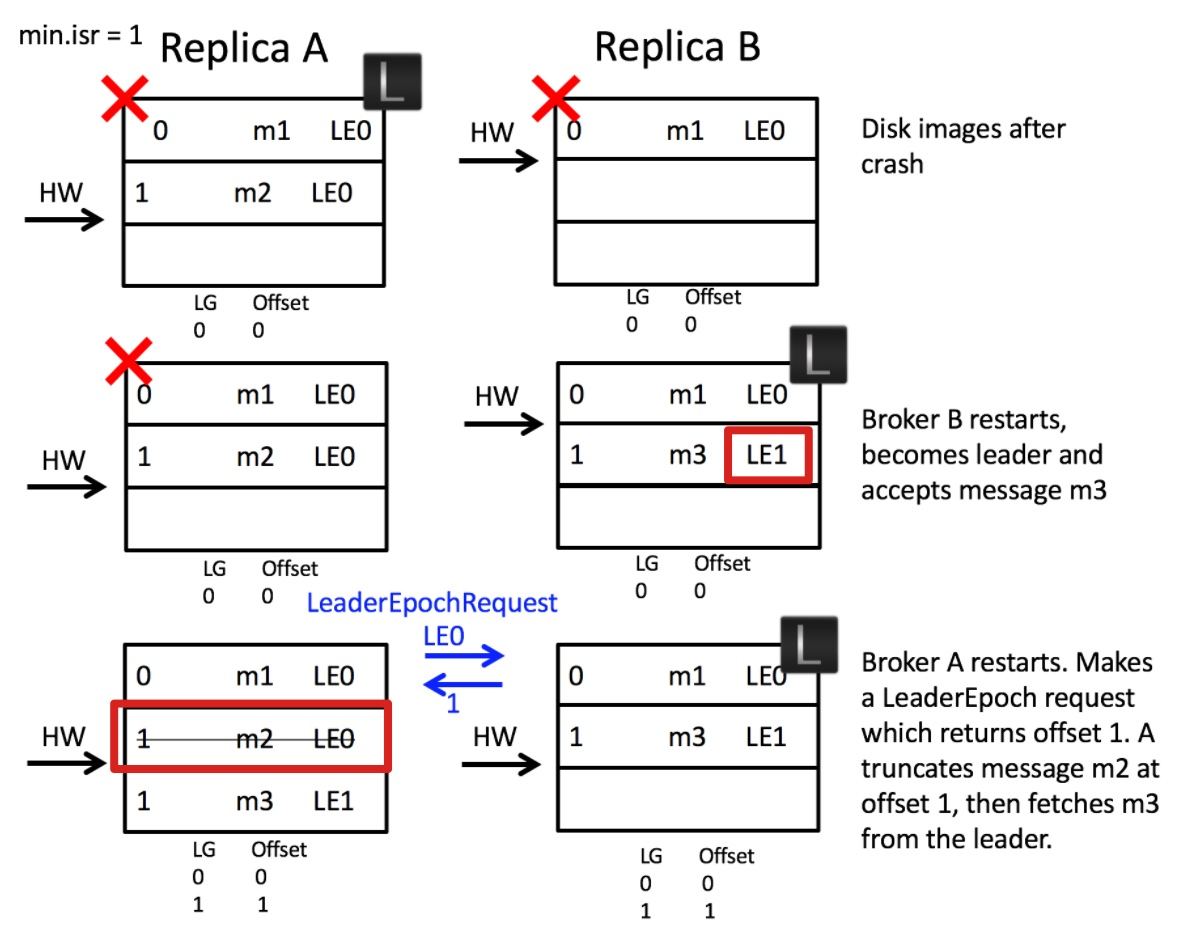
第二个问题,由于B重启后,已经进入了纪元1,它接到m3时,写入[epoch=1, offset=1],A重启后,向B发起LeaderEpochRequest,携带它所在纪元0,B发现不是同一个纪元,就返回A所在纪元的下一个纪元的offset值,也就是自己的写入起始值,也就是1,此时,A需要使用1进行截断,消息m2被丢弃,m3被正常写入offset1的位置。消息错乱解决了。
看完了理解的还是不透彻,只是明白Kafka怎么做了,没消化这个设计思想,吃完饭回来再看看吧。
参考











 京公网安备 11010802041100号
京公网安备 11010802041100号