本文主要是关于卷积编码的介绍,并分析探讨了采用卷积编码的原因和优势。
卷积编码
在卷积码的编码过程中,对输入信息比特进行分组编码,每个码组的编码输出比特不仅与该分组的信息比特有关,还与前面时刻的其他分组的信息比特有关。同样,在卷积码的译码过程中,不仅从当前时刻收到的分组中获取译码信息,还要从前后关联的分组中提取相关信息。正是由于在卷积码的编码过程中充分利用了各组的相关性,使得卷积码具有相当好的性能增益。
移动通信系统中,数字信号在无线信道中传输时,由于信道自身条件特性的不理想,会受到诸多噪声干扰的影响,因而产生误码。为了在已知信噪比的情况下达到一定的误码率指标,除在合理设计基带信号,选择调制解调方式,并采用信道均衡,分集等措施的基础上,还应使用信道编码与交织,使误码率进一步的降低。差错控制编码已经十分成熟的应用于信道编码技术之中。卷积码和分组码是差错控制编码的2种主要形式,在编码器复杂度相同的情况下,卷积码的性能优于分组码,因此卷积码几乎被应用在所有无线通信的标准之中,如GSM,CDMA-IS95和WCDMA的标准中。
采用卷积编码的原因和优势
在信道编码研究的初期,人们探索、研究出各种各样的编码构造方法,其中包括卷积码。早在1955年,P.Elias首先提出了卷积码。但是它又经历了十几年的研究以后,才开始具备应用价值。在这十几年期间,J.M.Wozencraft提出了适合大编码约束度的卷积码的序列译码,J.L.Massey提出了实现简单的门限译码,A.J.Viterbi提出了适合小编码约束度的卷积码Viterbi算法。20年后,即1974年,L.R.Bahl等人又提出一种支持软输入软输出(SISO,Soft-Input Soft-Output)的最大后验概率(MAP,Maximum A Posteriori)译码——BCJR算法。其中,Viterbi算法有力地推动了卷积码的广泛应用,BCJR算法为后续Turbo码的发现奠定了基础。
为了支持高效、灵活的传输方式,信道编码技术需要考虑到各种不同的传输码率和调制方式,兼顾HARQ重传技术以及链路自适应技术。为此,信道编码技术常常使用打孔或者重复的方法,从编码比特流中提取预定长度比特序列,这个过程称为速率匹配。研究表明,均匀并且对称的打孔或者重复模式能够获得最优的速率匹配性能。均匀的打孔或者重复模式是指打孔或者重复的比特位置的分布是均匀的,以避免连续的比特位置上的比特被打孔或者重复。
TD-LTE中卷积码速率匹配的原理如图3-31所示。卷积编码器输出的第一、二和三校验比特流分别独立地交织后,被比特收集单元依次收集,也就是交织后的第一、二和三校验比特流依次输入到缓冲器中。每次传输时,比特选择单元从缓冲器头部的比特开始逐位读取,直至达到预定的比特数。当读取到缓冲器的尾部,仍然没有达到预定的比特数时,比特选择单元自动跳至缓冲器的头部继续读取。卷积码的这种基于缓冲器的速率匹配的过程,被称为循环缓冲器速率匹配(CBRM)。
TD-LTE采用的卷积编码器是码率为1/3的最优距离谱编码器,内嵌码率为1/2的最优距离谱编码器,这种编码编码方法能够保证获得优异的纠错性能。如图3-31所示,卷积码速率匹配时,比特收集单元在收集3个比特流时,3个比特流是依次被收集,这样能够保证卷积码通过速率匹配得到码率为1/2码字时,其距离谱仍然是最优的。
TD-LTE卷积码速率匹配采用的交织器是一个简单的行列交织器,如图3-32所示,交织器执行按行写入、内部列交织、按列读出的简单操作。行列交织器的列数固定为32,交织前,需要根据每个比特流的长度,计算得到行列交织器的行数,并根据需要在行列交织器的第一行的头部进行补零操作。在基于循环缓冲器进行速率匹配时,交织器的使用能够保证卷积码的打孔或者重复模式是均匀的,从而获得优异的卷积码速率匹配性能。另外,由于卷积码和Turbo码采用了一致的速率匹配方法,因此基站和终端能够采用一致的算法实现卷积码和Turbo码的速率匹配。
卷积码的特性
生成多项式
生成多项式使用K-1阶的多项式描述编码器的移位寄存器和模二加法器的连接状态。每个模二加法器的连接可表示成一个多项式。多项式的次数输入的阶次为0,其余按寄存器数的移位次数依次递增。如上图
输出1: g1(x) = 1 + x + x^2
输出2: g2(x) = 1 + x^2
以下是IEEE 802.11标准中的卷积码编码器,生成多项式分别为:
输出1: g1(x) = 1 + x^2 + x^3+ x^5 + x^6
输出2: g2(x) = 1 + x + x^2 +x^3 + x^6
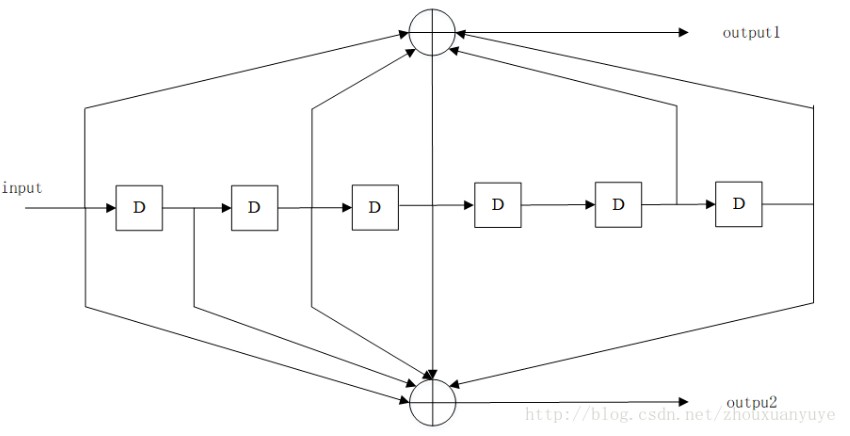
状态图
状态图是关于系统状态变化的描述,它将由系统的输入,根据当前的系统状态,影响系统的输出。卷积码编码器存储的L-1段消息,既要因新的消息输入而改变,又要影响当前的编码输出,把卷积码编码器的移位寄存器中任一时刻所存储的信息称为卷积码编码器的一个状态。
(n,k,L)卷积码共有2^(k*(L-1))个状态,每次输入k比特只有2^k种状态变化,所以,每个状态只能转移到全部状态的某个子集(2^k个状态)中去,每个状态也只能由全部状态的某个子集(2^k个状态)转移而来。
(2,1,2)卷积码编码器包含2级移位寄存器和2个模2加法器。2级移位寄存器共有2^2=4种不同状态,定义为S0(00)、S1(01)、S2(10)和S3(11)四种状态。在每个时刻,输入的1个比特信息,当前状态将转为4种状态中的任何一种。
表1、卷积码的状态转移表
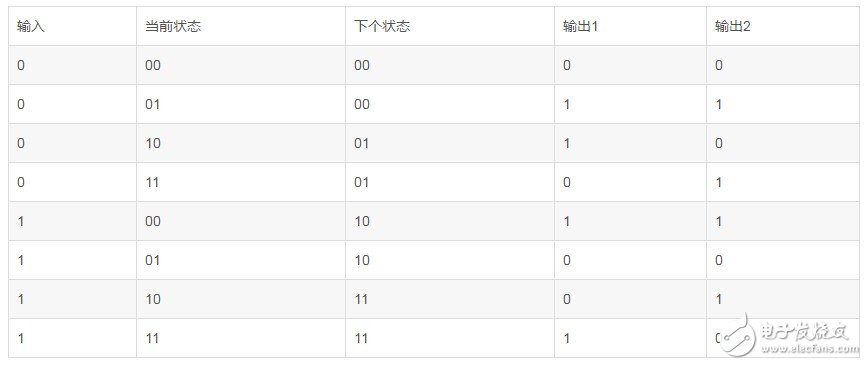
状态表类似查找表,原理即根据当前的输入和当前的状态,可以从表中查得输出信息。图4为卷积码的状态转移图,图中的状态转移表示“输入/输出1输出2”。
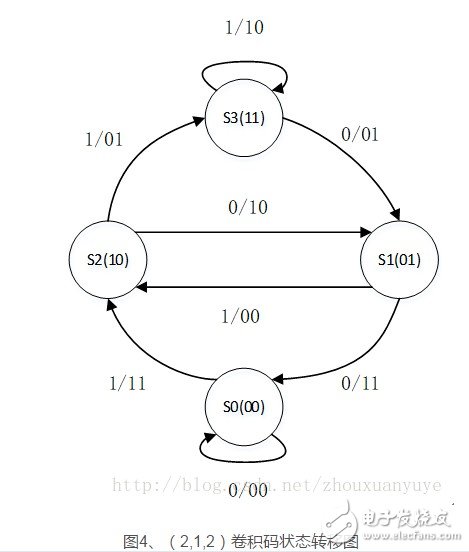
网格图
卷积编码器的状态图只能描述某个时刻的状态转移和编码过程,但整个编码的过程是随时间不断变化的过程。为了建立时间与状态转移的关系,将状态图按时间顺序连接,于是形成了卷积码的网格图。
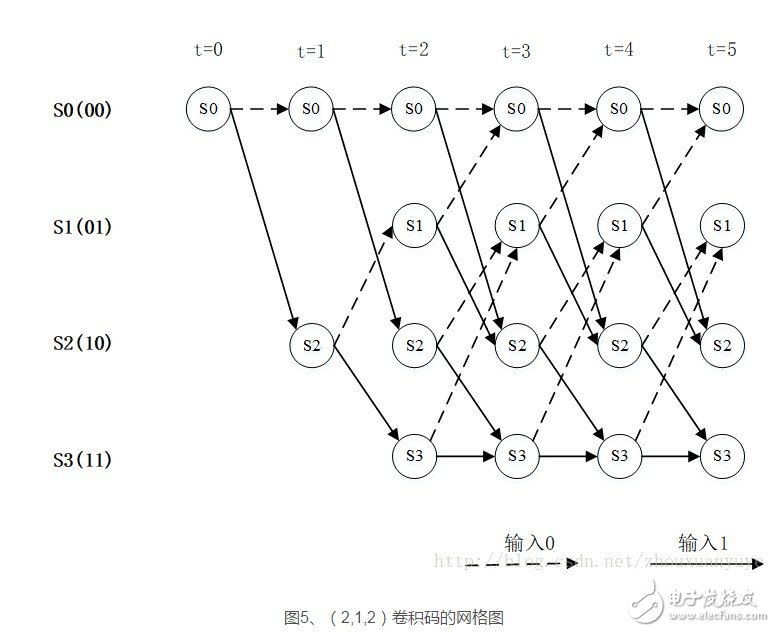
每一个动态编码的过程都可以用网格图中的一条路径表示,根据以下例子理解网格图,网格图不仅是表示卷积码的一种有效方法,更是理解卷积码译码的关键之处。
如编码序列“0 1 1 0 0”在图中的序列如下:
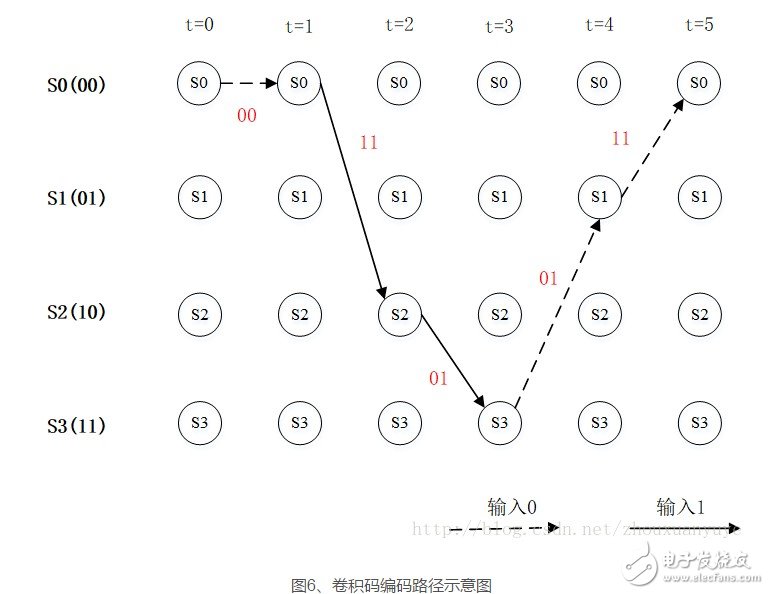
每次转移的输出依次为00 11 01 01 11,该输出已于图中标记。
卷积码的译码优势
卷积码的Viterbi 译码是根据接收码字序列寻找编码时通过网格图最佳路径的过程,找到最佳路径即完成了译码过程,并可以纠正接收码字中的错误比特。Viterbi 译码算法步骤如下描述:
①根据接收码符号R ,计算出相应的分支量度值BM( R/ Cj) , j = 1 、2 ;
②进入某一状态的2 条分支量度BM ( R/ Cj)与其前状态路径量度PM累加求和;
③比较到达当前状态的2 条新的路径量度PM的大小,选择最大者作为新的状态路径量度存储起来,并保存与此路径对应的码字;
④对所有的256 个状态都实施上述加、比、选(ACS) 运算;
⑤在每一译码时刻,满足延时就从256 条留存路径中,选择路径量度最大的一条路径作为译码数据输出;
⑥进入下一译码时刻,重复以上步骤,直至译码结束。
由于卷积码译码的复杂度随着约束长度的增加以非线性方式迅速增加,在实际应用中,卷积码的实际应用性能往往受限于存储器容量和系统运算速度,尤其是对约束长度比较大的卷积码。为了在有限的硬件或软件资源条件下保证系统较高的译码性能,下面对算法进行优化。
1. 留存路径更新算法优化
传统的实现留存路径存储器(SMU) 更新的算法,有寄存器交换法RE 和回溯法TB ,其详细内容请参考有关文献。寄存器交换法利用数据在寄存器中不断交换,来更新留存路径,实现信息的译码,相对于TB 法不断读写存储数据和需要延时回溯判决,其优点是存储单元少、译码延时短。RE 方法的缺点是内联关系过于复杂,不适合约束长度比较大的卷积码译码器的FPGA 实现。基于RE 提出了对留存路径存储及输出优化的实现方法,具体描述如下:。
①逐状态分配256 个存储器单元,单元位数由延时D (译码深度) 决定,每单元存储一个码字;
②每一个状态当前留存路径存储器的值由选定的前一状态存储器值和路径对应的码字决定(见上述Viterbi 译码算法步骤描述③) ;
③每一个译码时刻只向存储单元中存人留存路径的码字,并把选定码字写入存储单元中最低位;
④当译码时刻大于延时D 时,判决出当前时刻的所有状态中具有最大路径量度的状态,并将其对应的留存路径存储单元中的最高位作为译码结果输出;
⑤在实现存储单元的移位时,可采用循环移位的方式,避免重复读写,在软件实现时如果采用指针的方式读写地址,也可以做到只用一套存储器,这样就能继续在节省空间和提高运算速度上更进一步,在Matlab仿真中由于系统本身的特点,只须用简单的命令完成以上操作。
由于留存路径存储器中存入的只是路径信息,因而节省了存储空间;当译码输出时,只读出具有最大路径量度的状态所对应的留存路径存储单元最高位即可,不须向前回溯,减少了读RAM的次数(由D次减少至1 次) 提高了译码速度。
2. 优化判决输出
在输出时需要做延时判断,以确定延时足够再输出正确数据。但每一时刻做延时的后果是增加了运算量,导致系统效率较低,根据仿真实现的特点,可以做以下修改:为了避免重复做延时判断,节省运算量,译码输出时省略这一判断,每一时刻都有判决输出码字,只是在接收译码数据时把开始D时刻的接收码字丢弃, 相当于译码单元从D时刻开始输出,这是一种把部分系统功能从复杂模块转移分离到相对简单模块的思想。相对于在译码过程不断重复做判断,这种做法无论在软件或者硬件实现中,都能一定程度上提高运算速度。
结语
关于卷积编码的相关介绍就到这了,如有不足之处欢迎指正。



![扫描线三巨头 hdu1928hdu 1255 hdu 1542 [POJ 1151]](https://img.php1.cn/3c972/245b5/42f/19446f78530d3747.jpeg)


![[论文笔记] Crowdsourcing Translation: Professional Quality from Non-Professionals (ACL, 2011)](https://img1.php1.cn/3cd4a/24cea/882/e4b637de1cdddf51.jpeg)




 京公网安备 11010802041100号
京公网安备 11010802041100号