[TOC]
web scraper
简介:
Web Scraper分为chrome插件和云服务两种,云服务是收费的,chrome插件是免费的,这里说的就是chrome插件这种。 Web Scraper插件,可以让你以“所见即所得”的方式挑选要提取的网页数据,形成模版,以后可以随时执行该模版,并且执行结果可以导出成Csv格式。 web scraper 比较类似selenium和火车头浏览器,不过web scraper功能要少的多,不过更加小巧,学习成本更低
优点
- 抓取需要登录的数据较方便,因为这个插件是运行在浏览器上的。
- 只要抓取频率慢一点,被网站屏蔽的概率较小,也因为是浏览器的原因,这就像是真实的用户访问一样。
- 学习成本低
缺点
- 好像并不能做验证码识别
- 抓取效率较低,相对于爬虫程序来说,Web scraper没法大并发,快速切换IP等,所以大量级的数据抓取用Web Scrpaer不适合,慢慢抓大几千网页还是可以。
- 插件本身是不支持配置定时任务的,云服务提供了这种功能,不过是收费的,到是可以尝试使用Python驱动谷歌来进而来操作web scraper的定时
下载地址:
https://www.webscraper.io/
crx文件:jnhgnonknehpejjnehehllkliplmbmhn_0_2_0_18.crx
操作
安装
谷歌浏览器
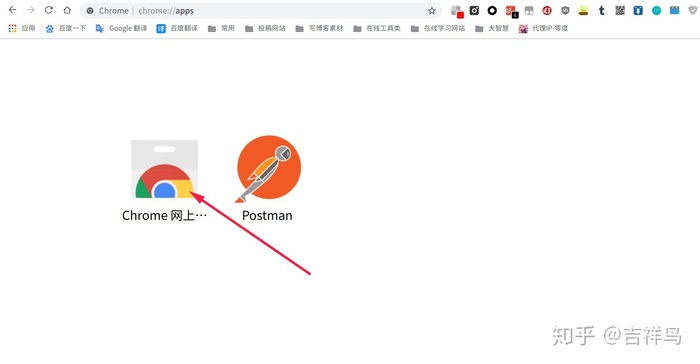
- 打开google浏览器,进入应用
- 点击网上应用商店
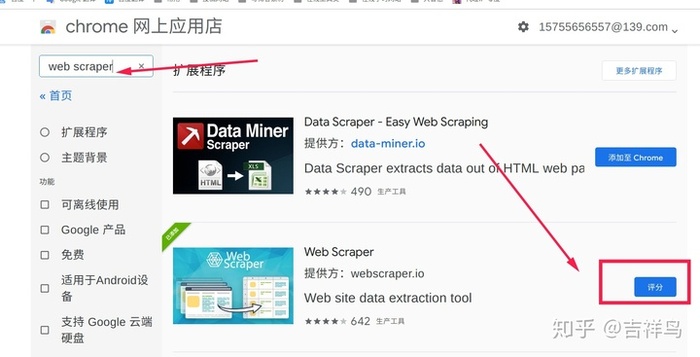
- 输入框搜索
web scraper,点击添加到chrome
- 安装完成
火狐浏览器
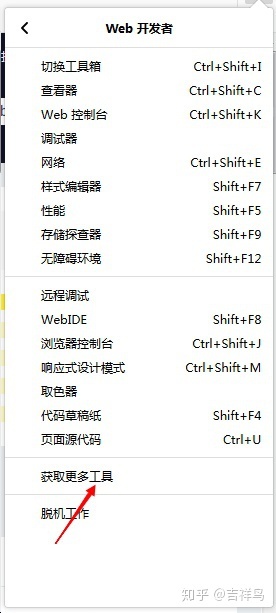
- 点击右上角的菜单按钮,然后点击进入web开发者
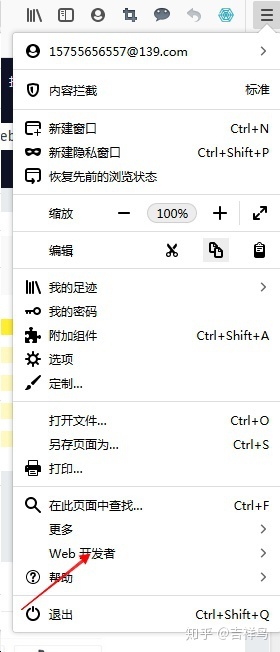
- 点击获取更多工具
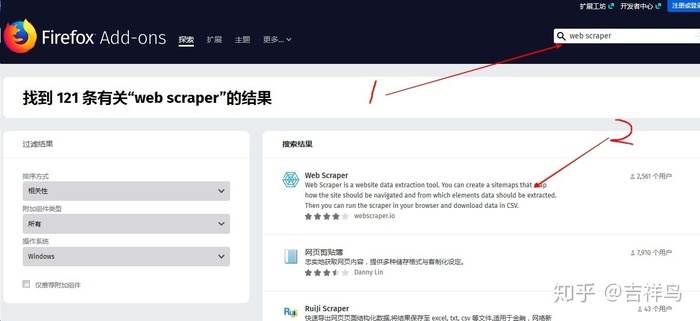
- 在搜索框里输入
web scraper进行搜索
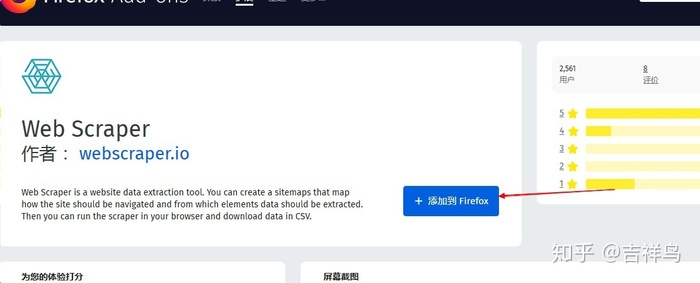
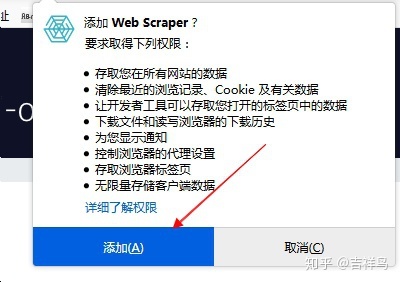
- 点击添加到
Firefox
使用说明
- 进入谷歌浏览器,按F12进入开发者模式
- 安装好
web scraper插件之后呢,会在最后出现web scraper标示
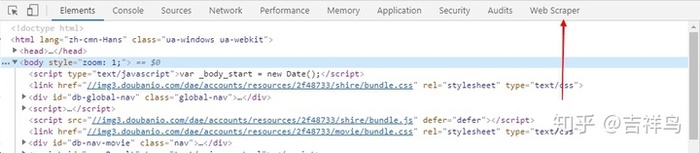
- 点击进入
web scraper
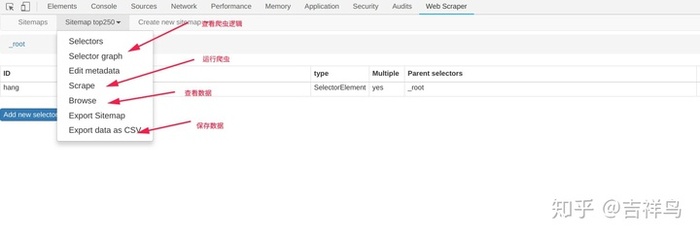
- 首先,我们点击
create new sitemaps-->create sitemaps,来创建一个爬虫项目 - 输入爬虫名称和需要采集的url,点击创建项目
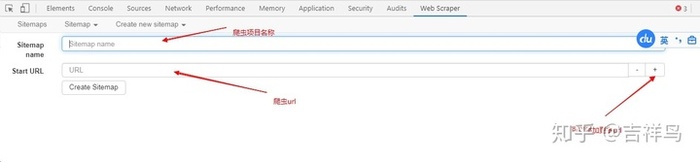
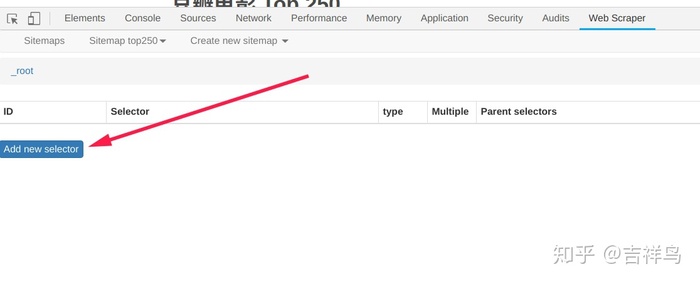
- 点击
Add new selector创建一个选择器
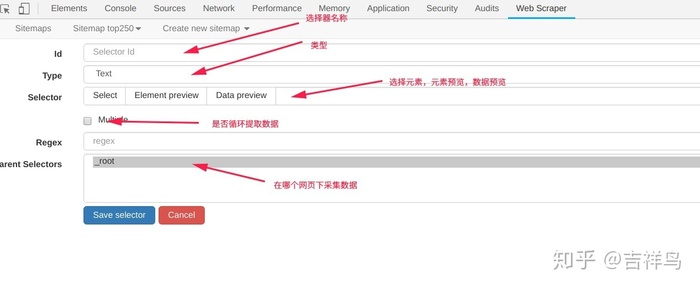
- 配置相关参数
- 运行爬虫,查看数据










 京公网安备 11010802041100号
京公网安备 11010802041100号