原文:Untangling Apache Hadoop YARN, Part 2: Global Configuration Basics
http://blog.cloudera.com/blog/2015/10/untangling-apache-hadoop-yarn-part-2/
在本系列的第1部分,我们详情了YARN集群的基本原理。在第2部分中,您将理解在集群上运行的其余组件以及它们如何影响YARN集群配置。
理想的YARN资源分配上一篇文章所说,YARN集群可以配置为使用集群上的所有资源。
实际的YARN资源分配在实际情况中,有两个起因不能让YARN使用一律资源:
1.非Apache Hadoop服务也需要在节点上运行(日常开销)。
2.其余与Hadoop相关的组件需要专用资源,不能与YARN共享(如运行CDH时)。
操作系统(日常开销)
任何节点需要一个操作系统才能工作。运行任何操作系统都需要预留少量资源。最常见的Hadoop操作系统是Linux。
Cloudera Manager Agents (管理)
Cloudera Manager是Cloudera的CDH集群管理工具。 Cloudera Manager Agent是在每个工作节点上运行的程序,用于跟踪其运行状况并解决其余管理任务(如配置部署)。
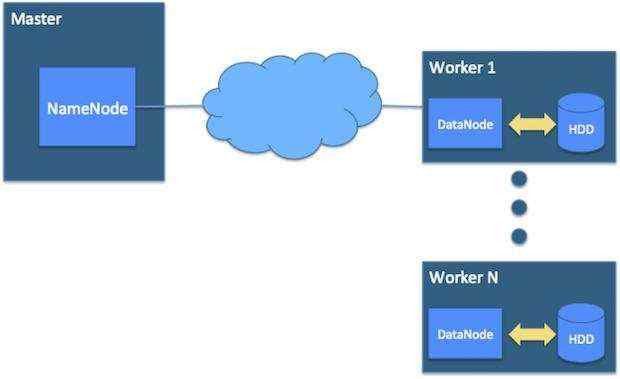
HDFS 集群 (必需) (Master/NameNode, Worker/DataNode)
这篇文章有意地省略了HDFS的任何探讨,HDFS是一个必须的Hadoop组件。对于我们讲述的内容而言,记住以下两点:
- Master节点守护程序称为NameNode
- Worker节点守护程序称为DataNode
对于Hadoop安装,Cloudera建议HDFS DataNode和YARN NodeManager在集群中的同一组Worker节点上运行。 DataNode需要预留少量基本资源用于正确的操作。这可以在下面的Figure 1中看到。
HBase 集群需求 (CDH)
假如集群配置为使用Apache HBase,则应为RegionServer预留每个工作节点上的资源。预留的内存量尽可能大。
Impala 集群需求 (CDH)
假如集群配置为使用Impala,则应为Impala后端守护进程留出每个工作节点上的资源。预留的内存量尽可能大。
YARN NodeManagers (必需)
NodeManager还需要预留少量资源以便正常操作。
分配剩余的资源给YARN
一旦将资源分配给上述各种组件,剩余的可以分配给YARN。 (注意:本文没有具体的建议,由于一个节点的硬件规格随着时间的推移而持续改进,具体数字的例子请参考这个调优指南 http://tiny.cloudera.com/yarn-tuning-guide;还可以参考Tuning the Cluster for MapReduce v2 (YARN) http://www.cloudera.com/content/cloudera/en/documentation/core/latest/topics/cdh_ig_yarn_tuning.html
应用配置计算最终配置后,可以在yarn-site.xml或者Cloudera Manager的YARN Configuration部分中输入。一旦这些属性配置到集群中,您可以验证它们。
在RM UI中验证YARN配置
如前所述,在ResourceManager有YARN集群上可用资源的快照。
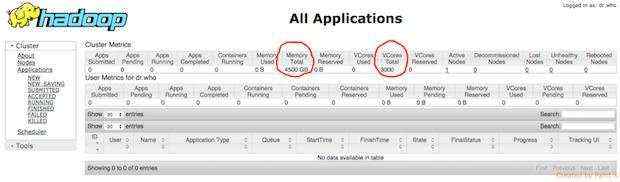
示例:假设您在50个Worker节点上具备以下配置:
1.yarn.nodemanager.resource.memory-mb = 90000
2.yarn.nodemanager.resource.vcores = 60
计算下来你群集的总资源是:
1.memory: 5090GB=4500GB=4.5TB
2.vcores: 5060 vcores= 3000 vcores
在ResourceManager Web UI页面上,集群指标表显示集群的总内存和总vcores,如下图所示:
容器配置
此时,YARN集群根据资源正确设置。 YARN使用这些资源进行分配,并对集群实施限制。
最小: yarn.scheduler.minimum-allocation-mb
最大: yarn.scheduler.maximum-allocation-mb
最小: yarn.scheduler.minimum-allocation-vcores
最大: yarn.scheduler.maximum-allocation-vcores
内存提升: yarn.scheduler.increment-allocation-mb
VCore 提升: yarn.scheduler.increment-allocation-vcores
Container限制及建议值:
yarn.scheduler.minimum-allocation-mb最低值为0
任何内存大小调整属性必需小于或者等于yarn.nodemanager.resource.memory-mb
最大值必需大于或者等于最小值。
yarn.scheduler.minimum-allocation-vcores最低值为0
任何vcore大小调整属性必需小于或者等于yarn.nodemanager.resource.vcores
最大值必需大于或者等于最小值
对yarn.scheduler.increment-allocation-vcores的建议值为1。较高的值可能比较白费。
注意,在YARN配置中有少量非常易犯的错误。假如容器内存请求最小值(yarn.scheduler.minimum-allocation-mb)大于每个节点(yarn.nodemanager.resource.memory-mb)可用的内存,那么YARN将不可能满足该请求。相似参数有yarn.scheduler.minimum-allocation-vcores。
MapReduce 配置
Map任务内存属性为mapreduce.map.memory.mb。 Reduce任务的内存属性是mapreduce.reduce.memory.mb。因为这两种类型的任务必需适合容器,所以该值应小于容器最大大小。 (我们不会详细详情Java和影响启动Java虚拟机的YARN属性,它们可能会在以后的文章中探讨)。
ApplicationMaster内存配置
属性yarn.app.mapreduce.am.resource.mb用于设置ApplicationMaster的内存大小。因为ApplicationMaster必需适合容器,该属性应小于容器最大值
总结本文主要内容:
1.理解YARN专用群集情况下的基本群集配置。
2.实际在开始配置YARN群集时,要考虑到其它服务,防止将所有资源分配给YARN,考虑以下配置:
操作系统开销(Linux,Windows)
管理服务,例如Cloudera Manager Agent
必要的服务,如HDFS
Master/Worker服务(HBase,Impala)
剩余资源给YARN。
3.知道在哪里查看集群的配置。
4.理解需要进一步调整基于在群集上运行的应用程序的分析。还有请注意可能有其余配置开销没有列在此帖中。
下一步
第三部分我们将详情YARN的基本调度。











 京公网安备 11010802041100号
京公网安备 11010802041100号