作者:灵动的音乐xl | 来源:互联网 | 2023-08-25 16:54
Keras是开发的高级神经网络API,其重点是实现快速实验。能够以最小的延迟将想法付诸实践是进行良好研究的关键。Keras具有以下主要功能:允许相同的代码无缝地在CPU或GPU上运
Keras是一种先进的神经网络API开发,其重点是实现快速实验。能够以最小的延迟将想法付诸实践是好的研究的关键。Keras具有以下主要功能:
允许相同的代码在CPU或GPU上无缝运行。用户友好的API可以方便快捷地实现深度学习模型的原型。支持内置卷积网络(用于计算机视觉)、循环网络(用于序列处理)以及两者的任意组合。支持任意网络架构:多输入多输出模型、层共享、模型共享等。这意味着Keras基本适合构建从记忆网络到神经图灵机的任何深度学习模型。它可以运行在多个后端(包括TensorFlow、CNTK或antano)。关于这个项目的更多信息,请参考Keras主网站。这个网站提供了关于Keras的R接口的文档。网站是https://keras.io
00-1010安装
首先,从GitHub安装keras R包,如下图:
tools : install _ github(" rstudio/Keras ")默认情况下,Keras R接口使用TensorFlow后端引擎。要安装核心Keras库和TensorFlow后端,请使用install_keras()函数:
图书馆
Install_Keras()这将为您提供默认的基于CPU的Keras和TensorFlow安装。如果您想做更多的定制安装,例如,如果您想使用NVIDIA GPU,请参考install_keras()的文档。
学习Keras
接下来,我们通过一个简单的例子,使用Keras从MNIST数据集识别手写数字。熟悉基础知识后,请查看本网站上提供的教程和其他学习资源。
由franscholet(Keras创始人)所著的《R深度学习》一书对Keras以及深度学习的概念和实践进行了较为全面的介绍。
你可能还会发现用Keras下载深度学习小抄很方便,它是Keras所有功能的快速高级参考。
入门我们可以通过简单的例子学习Keras的基本知识:从MNIST数据集识别手写数字。MNIST由28*28个手写数字的灰度图像组成,如下所示:
数据集还包括每个图像的标签,它告诉我们它是哪个数字。例如,上述图像的标签是5、0、4和1。
准备数据
MNIST数据集包含在Keras中,可以使用dataset_mnist()函数进行访问。在这里,我们加载数据集,然后为测试和训练数据创建变量:
图书馆
mnist - dataset_mnist()
x_train - mnist$train$x
y_train - mnist$train$y
x_test - mnist$test$x
Y_test-mnist$test$yx数据是灰度值(图像、宽度、高度)的三维数组。为了准备训练数据,我们通过将宽度和高度整形为一维(28x28图像的fzdsg长度为784个向量)将三维数组转换为矩阵。然后,我们将灰度值从0到255之间的整数转换为0到1之间的浮点值:
#重塑
x _ train-array _ resform(x _ train,c(nrow(x_train),784))
x _ test-array _ resform(x _ test,c(nrow(x_test),784))
#重新缩放
x _火车-x _火车/255
X_test-x_test/255请注意,我们使用array _ refresh()函数而不是dim-()函数来重塑数组。这样,可以使用行优先语义(而不是默认的R的列优先语义)重新解释数据,这与Keras调用数字库来解释数组维度的方式是兼容的。
y数据是一个整数值向量,取值范围从0到9。为了准备训练数据,我们使用Keras to _ classic()函数将这些向量一元编码成二进制类矩阵:
y _ train-to _ classic(y _ train,10)
y _ test-to _ classic(y _ test,10)定义了模型。
Keras的核心数据结构是一种组织层次的模型和方式。最简单的模型类型是序列模型,即线性层叠模型。
我们首先创建一个顺序模型,然后使用pipeline (%)运算符添加图层:
模型- keras_model_sequential()
型号%%
layer _密集(单位=256,激活='relu ',input_shape=c(784)) %%
layer _ dropout(速率=0.4)
%>%
layer_dense(units = 128, activation = 'relu') %>%
layer_dropout(rate = 0.3) %>%
layer_dense(units = 10, activation = 'softmax')
第一层的input_shape参数指定输入数据的形状(代表灰度图像的长度784的数字矢量)。 最后一层使用softmax激活函数输出长度为10的数字矢量(每个数字的概率)。
使用summary()函数可打印模型的详细信息:
summary(model)

接下来,使用适当的损失函数,优化器和指标来编译模型:
model %>% compile(
loss = 'categorical_crossentropy',
optimizer = optimizer_rmsprop(),
metrics = c('accuracy')
)
训练与评估
使用fit()函数可以使用每批128个图像30个epochs的规模来训练模型:
history <- model %>% fit(
x_train, y_train,
epochs = 30, batch_size = 128,
validation_split = 0.2
)
fit()返回的历史记录对象包括损失和准确性指标,我们可以绘制它们:
plot(history)
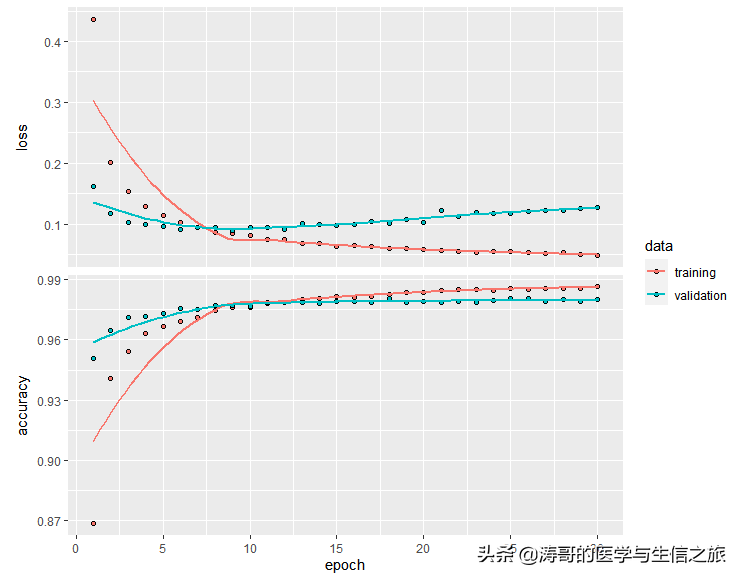
根据测试数据评估模型的性能:
model %>% evaluate(x_test, y_test)
$loss
[1] 0.1149
$acc
[1]0.9807
生成关于新数据的预测:
model %>% predict_classes(x_test)
Keras为构建深度学习模型提供了简单,优雅和直观的词汇。 建立问题回答系统,图像分类模型,神经图灵机或任何其他模型同样简单。
书籍Deep Learning with R
如果您想对Keras以及深度学习的概念和实践进行更全面的介绍,我们建议您从Manning那里获得Deep Learning with R这本书。 这本书是Keras的创作者FrançoisChollet与J.J. Allaire,他为Keras编写了R接口。需要的同志可以私信我,留下邮箱。
该书假定没有任何有关机器学习和深度学习的知识,并且从基础理论一直到高级实际应用,并且都使用了与Keras的R接口。
为什么叫Keras?
Keras(κέρας)在希腊语中是指号角。它是对古希腊和拉丁文学作品中的文学意象的参考,最早出现在奥德赛,梦中的精神(狂野的板栗,奇异的狂野的板栗斯)被划分为那些用虚假的眼神欺骗人,通过象牙门到达地球的人,以及那些宣布将要过去的未来的人们,他们是通过号角之门到达的。这是关于κέρας(角)/κραίνω(充填)和ἐλέφας(象牙)/ἐλεφαίρομαι(欺骗)的戏剧。
Keras最初是作为ONEIROS(开放式神经电子智能机器人操作系统)项目研究工作的一部分而开发的。
“ Oneiroi超出了我们的解释范围,谁能确定他们讲的是什么故事?并非所有男人想要的东西都成为现实。那里有两个大门可以通向转瞬即逝的hcdmb;一种是由牛角制成,一种是象牙制成。穿过锯齿象牙的狂野的板栗人是骗人的,带有无法实现的信息。那些从打磨的角出来的人背后有真理,要为看见它们的人成就。”荷马·奥德赛19.562 ff(Shewring翻译)。









 京公网安备 11010802041100号
京公网安备 11010802041100号