雷锋网AI科技评论按:人们已经给神经网络找到了越来越多人的事情做,比如画画和写诗,微软的小冰都已经出版了一本诗集了。而其实训练一个能写诗的神经网络并不难,Automattic公司的
雷锋网 AI 科技评论按:人们已经给神经网络找到了越来越多人的事情做,比如画画和写诗,微软的小冰都已经出版了一本诗集了。而其实训练一个能写诗的神经网络并不难,Automattic 公司的数据科学家 Carly Stambaugh 就写了一篇文章介绍如何简单快捷地建立一个会写诗的人工智能。雷锋网(公众号:雷锋网) AI 科技评论全文翻译如下。

「代码即诗篇」,这是 WordPress 社区的哲学。
作为一个 coder 同时也是一个诗人,我一直都十分喜爱这句话。然而,如果将这句话翻转过来,我不禁要问:「我能否通过代码写诗呢?我能否创造一个能够写出原创性诗词的机器?」于是,我做了一系列实验去探究这个问题的答案。
首先,我们都知道如果想让机器学会写诗,那么它必须先学会读诗。在整个 2017 年中,使用 WordPress 系统发布的、标注为诗歌的帖子有超过 50 万篇(https://wordpress.com/tag/poetry)。我联系了一些通过 WordPress 分享作品的高产诗人,询问他们是否愿意与我合作完成一个有趣的实验:能否让我的机器阅读他们的作品,让我的机器能够学到诗歌的形式和结构,最终让机器能够自己完成诗歌创作?
-
O at the Edges – Robert Okaji(https://robertokaji.com )
-
Wolff Poetry – Linda J. Wolff(http://wolffpoetry.com )
-
Poetry, Short Prose and Walking – Frank Hubeny(https://frankhubeny.blog )
-
Perspectives on Life, the Universe and Everything – Aurangzeb Bozdar(https://abozdar.wordpress.com )
何为LSTM 以及它如何生成文本?
我使用了一种名为 LSTM (Long Short Term Memory network, 即长短时期记忆网络) 的神经网络来构建我的诗歌机器人。
神经网络通过层次结构将一个问题分解为多个小问题。举例而言,假如你想训练一个用于识别正方形的神经网络,其中一层可能会负责识别直角,另一层可能负责识别平行线。为了将图片认定为正方形,所有这些特征都会被机器呈现出来。神经网络会通过将数以百万计的正方形图片作为输入训练模型,从而学习到这些必要的特征的参数。这个机器还会学到图片的哪些特征对于识别正方形是重要的,哪些是不重要的。
现在,假设你想要使用神经网路去预测这两个字母的下一个字母:
Th_
对于一个人来说,这个任务是十分简单的。很有可能,你猜下一个字母应该是 e。但是,我敢打赌,如果你是一个说英语的人,你不会猜下一个字母是 q。这是因为你已经通过学习知道:在英语中,q 不会跟在 th 的后面。一个单词中,前面的字母对于预测后面会出现什么字母是及其相关的。一个 LSTM 可以「记住」它之前的状态并将其告诉它当前的决策过程。关于 LSTM 如何工作的更深入的解释,可以参考谷歌大脑的 Chris Olah 所写的这篇精彩的文章。
与许多基于 LSTM 的文本生成案例一样,我的诗歌机器人通过一次生成一个字符来生成文本。因此,要想把单词组合成任何有意义的样式,诗歌机器人首先必须学会如何造词。为了实现这一点,它需要数百万个有效的单词的例句。值得庆幸的是,WordPress.com 上有海量的诗歌。
数据集的准备
首先,我从 Elasticsearch 索引中抓取了上面列出的所有网站中的诗歌。我使用一种非常简单的规则(根据每遇到一次「/n」的字符和上一个「/n」之间的词数)把除了诗歌的文本之外的所有东西清洗掉了。如果一块文本包含许多单词但是包含很少的「/n」字符,它可能是一个或多个段落的集合。然而,一块跨越多行的文本更有可能是一首诗。这是一个简单的方法,当然,我可以想到很多优秀的诗歌都无法满足这个规则!但是,就本实验的目的而言,我对于 LSTM 是否能学习到诸如换行、诗的章节等诗歌的结构,以及其他的例如押韵、类韵、辅韵、头韵修辞手法十分感兴趣。因此,将训练数据限制为相当结构化的诗歌是合理的。
一旦一块文本被认定为一首诗,我就将它输出到一个文本文件,并且在他前面加上「++++/n」的前缀以表示一首新诗的开始。这样做可以产生大约 500KB 的训练数据。通常,我试着使用至少 1MB 的文本去训练一个 LSTM 网络,因此,我需要寻找更多的诗歌!为了补充更多有特色的诗人的作品,我使用了去年发表的被标记为诗歌的公开的帖子中产生的随机样本。这就好像你在 WordPress.com 阅读器里用诗歌标签浏览之后(https://en.wordpress.com/tag/poetry/)得到的结果。我将随机抓取的诗歌的规模限制在每个诗人一个帖子。
训练 LSTM 网络
当我有了超过 1MB 的诗歌之后,我开始构建一个 LSTM 网络。我使用 Python 深度学习库 keras 以满足我所有对神经网络的需求。keras(https://github.com/keras-team/keras)在 Github 上的 repo 代码仓库有许多示例文件,可以帮助学习一系列不同的神经网络,其中就包括使用 LSTM 生成文本(https://github.com/keras-team/keras/blob/master/examples/lstm_text_generation.py )。我根据这个示例编写了我的模型的代码,并且开始进行不同模型配置之下的实验。这个模型的目标是要产生原创的诗歌。在这种情况下,过拟合,换而言之,太过于详细地学习训练数据以致于模型不能很好地泛化,会导致生成的文本与输入地文本太相似。(这就好像剽窃,没有诗人会喜欢这样做!)一个防止过拟合的方法是在网络中使用 dropout 。这就迫使在每一个批次的训练中,随机地使一个子集的节点权重降为 0。这有点像迫使网络「忘记」一些它刚刚学到的知识。(我还添加了额外的后期处理去检查,防止诗人的作品被诗歌机器人复制)
我使用 FloydHub(https://www.floydhub.com/ )的 GPU 来完成我的神经网络繁重的训练工作。这使我能够以将近比我的笔记本快十倍的速度训练我的神经网络。我的第一个神经网络有一个 LSTM 层,后面跟随着一个 dropout 层。这个网络产生了一个看上去十分像诗歌的文本。它有换行和诗的章节,并且几乎所有的字符组合都是真实的单词。偶尔整行都是较为通顺的。实际上,它第一次迭代产生了这样的佳句:
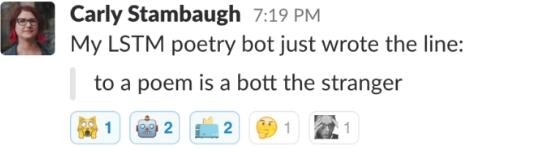
我增加了一些 LSTM 层,尝试着改变每一层中 dropout 的程度,知道最终定下了一个如下面代码所示的最终模型。我最终选择使用三层 LSTM,因为此时训练时间开始变得很长,而训练的结果相当好。(下面是程序代码)
1. model = Sequential()
2. model.add(LSTM(300, input_shape=(maxlen, len(chars)), return_sequences=True, dropout=.20, recurrent_dropout=.20))
3. model.add(LSTM(300, return_sequences=True, dropout=.20, recurrent_dropout=.20))
4. model.add(LSTM(300, dropout=.20, recurrent_dropout=.20))
5. model.add(Dropout(.20))
6. model.add(Dense(len(chars)))
7. model.add(Activation('softmax'))
8. model.compile(loss='categorical_crossentropy', optimizer='adam')
这里有一个图,比较了随着LSTM层数增加而变化的模型的损失函数曲线。
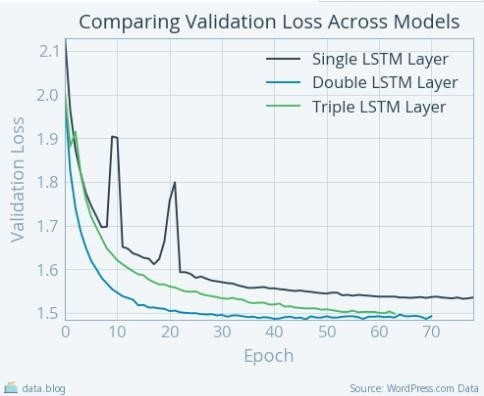
随着模型中LSTM层数增加,验证损失迅速下降
哦!这是怎么回事呢?(https://stats.stackexchange.com/questions/303857/explanation-of-spikes-in-training-loss-vs-iterations-with-adam-optimizer )事实上,当我们使用 adam 优化器训练模型时,这是很常见的。注意,随着我向网络中增加 LSTM 层,模型的验证损失整体上以很快的速率持续下降。这说明在较少的迭代次数内可以得到可行的实验结果,但是额外的 LSTM 层会增加每次迭代的训练时间。训练单层 LSTM 时,每次迭代大概需要 600 秒,一晚上可以完成实验。然而,训练三层 LSTM 时,每次迭代需要 7000 秒,总共需要好几天的时间完成训练。所以,更快的验证损失的下降实际上并不意味着更快地得出结果。完全从我的主观视角来说,尽管需要花费更多时间去训练,使用三层 LSTM 层的网络生成的诗是更好的。
生成诗歌
为了产生完全原创的文本,我还需要改变文本的生成方式。在 keras 库中的示例中,脚本从训练数据中选择一个随机的字符序列作为输入,即训练神经网络的种子。我想要构建一个能写出原创诗歌的诗歌机器人,而不是转写其他诗人的诗句!因此,我在生成文本的步骤中,尝试了不同的种子。由于我已经在训练集合中为每首诗加上了「++++/n」的开头,我想这就已经注意创造完全原创的诗歌了。但是结果是一组没有意义的「/n」、「.」、「_」和「&」的组合。尽管反复的试验和纠错,我发现种子序列需要与训练序列拥有相同数目的字符。在事后看来,这是显而易见的。最终,我使用了一个有 300 个字符的序列,我通过重复「++++/n」来生成刚好 300 个字符的用于文本生成的种子。这个诗歌机器人每轮可以生成几首诗并偶尔用「++++/n」将这几首诗分割开来。
在脚本生成了新一轮诗歌后,我做了最后的剽窃检查。为了达到这一点,我首先在训练集中建立了一个所有 4-gram(包含 4 个单词的短语)的集合,并且对我的诗歌机器人写的诗做了同样的操作。之后,我计算出了这两个集合的交集。为了达到本实验的目的,我手动检查了 4-gram,确保出现在两个 4-gram 集合中的短语是无意义的。多数时候,这个交集里的短语都是这样:
i don't want
i can not be
i want to be
the sound of the
为了得到更好的测试结果,我在 5-gram 和 6-gram 上重复了这个步骤。如果我要将这个过程自动化,我可能会采用一种基于频率的方法,并且排除掉那些被认为是剽窃的、多个作者诗作间的共同的 n-gram。
神奇的诗篇!
在每一轮迭代之后输出模型的权重意味着我们可以在训练时在一些节点上装载模型的快照。当我们观察最终模型的前期迭代时,很显然,诗歌机器人会立刻领悟换行技巧。我预料到了这一点,因为根据设计,训练设计最显著的特征是每行字符数很少。下面是一个经过一轮迭代的训练生成的诗:

诗歌机器人已经学习到了一些真实的词汇,并且模仿在行与行之间留出空白的常见做法。乍看之下,如果你不仔细探究,这看上去就像一首诗。在单层 LSTM 模型的损失函数收敛之后,除了换行,模型还学会了诗的分节,甚至显示出了一些常见的重复的诗歌修辞手法。

LSTM 的强大之处在单行诗句中非常明显了。除了本文题目的那一行,另一个我最喜欢的诗行是:

在有史以来最有趣的格言机器人 Inspirobot 的辅助下,Demet从她最爱的诗行中学习,创造了这样的佳句:

尽管单一的 LSTM 模型在一首诗中并没有完全掌握主题,但它在整个作品的创作过程中似乎都有一个共同的主线。下面是一个从所有单层 LSTM 模型生成的诗词中产生的词云:

多么令人沉醉啊!这个诗歌机器人着迷于骄阳和星辰
如果太阳是训练数据中最常见的主题,那也就不足为奇了,然而事实并非如此!下面是一个训练数据中产生的词云:

诗人热衷于歌颂爱
Emily Dickinson曾经描写过关于自然和死亡的诗歌。我的诗歌机器人则描写关于天体的诗歌。各有千秋!
在增加了第二层 LSTM 网络之后,我开始看到了其他的类似于头韵和押韵的诗歌修辞手法:

它也开始写出一些十分有诗意的短语。这些短语有些类似于之前的模型偶尔产生的绝佳的诗句,但是他们有些时候跨越了不止一行。例如:

天啊!这就很深刻了!
到了这里,我们已经看到了换行、节律、押韵(包括在中间和结尾)、重复和头韵。这还不错!但是,除了偶得的佳句,这时诗歌机器人写出的诗大多数都是不通顺的单词的集合。在大多数情况下,它没有意义的短语甚至都不符合语法结构规范。
然而,随着第三层 LSTM 的加入,这个情况产生了改观。即使仍然没有意义,模型产生的诗句更加可能合乎语法规范。例如:
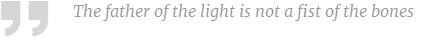
这个句子似乎说不通,但是它恰当地安排了语言的各个组成部分。它也包含头韵的修辞手法,名词性从句也有诗意的感觉。三层 LSTM 的网络模型也产生了三行我认为非常有功力,饱含诗意的诗句:

但是,下面这首完整的诗却可以被称作这个三层LSTM模型取得的最高成就!

这首诗并不是节选自一大段文字的文本。这些诗行被牢牢地分隔在两个「++++/n」之间!

看啊,人性是多么有趣!我们是如此独一无二,我们身上有无限的可能!
特别鸣谢与我合作完成这个有趣的实验的诗人们!请大家一定要去访问他们的网站欣赏他们的佳作哦!
O at the Edges – Robert Okaji
Wolff Poetry – Linda J. Wolff
Poetry, Short Prose and Walking – Frank Hubeny
Perspectives on Life, the Universe and Everything – Aurangzeb Bozdar
via Data for Breakfast,雷锋网 AI 科技评论编译
相关文章:
"LSTM之父"Jürgen Schmidhuber:我一直在努力实现三十年前的目标 “AI奴役人类”很愚蠢
详解如何用 LSTM 自动识别验证码
《安娜卡列尼娜》文本生成——利用 TensorFlow 构建 LSTM 模型
。







 京公网安备 11010802041100号
京公网安备 11010802041100号