
前两天发了一篇《SQL的3列4种对比方法》,近500 阅读。一个月没更文了,没想到朋友们都还关注着,我很激动,非常感谢。
这题是工作中的一个实战题,求维度建模中数据的完整性。因为投行的数据敏感性,我就用阿里的天池竞赛数据,改造了下。
所以有几处地方,被我们微信群里的 xuhui 大佬看出来有瑕疵。在这要声明下,大家对题目中的前置条件,有迷糊的地方,一定找我问清楚。我的微信是 dbLenis.
再次感谢 xuhui 大佬,itpub 的金牌坛主,万忙中,依然愿意在群里为我们解答数据库相关的问题。
有的朋友问我,为什么要写这么一篇没有多少干货的文章呢,难道对比下字段,还有谁不会的么?
就如我在文章中提过的那样,写这篇文章,并不想证明技术实现上有多么的难,或者我的技术水平有多么牛。
只是文中遇到的这个场景,和我在处理时想到的解法及其产生缘由,一定适合每个 SQL 君参考。在为读者们珍惜秀发的方向上,我一直不遗余力,不用谢。
接下来,3个提升编程水平的技巧,送给你。
一,发挥想象,刨根问底
碰到问题,多想解决思路,不必急于解答完。
我留意很多朋友,吃东西时,进食速度特别快。哐哐哐一顿猛吃。印象最深的是,公司有天下午发苹果,有位朋友就是这样,别人一半还没吃完,他就已经洗好嘴巴,跟我们来唠嗑了。
结果有位女士惊奇的一叫,“这苹果里居然有条虫”。“我这里也有,还不止一条”。我就看着这位已经吃完的小伙伴,脸色慢慢由红变黑。
编程我认为也一样。看到一个问题,解决的速度太快,反而失去原本你应该细想,从而找到更优解的机会。
把想当然认为只有一个解的问题,用尽所有方法去寻找一个最优解,并把它记录下来,形成自己的知识库。这是学的最快,也最扎实的路径。
我原本没有这个习惯,认为笔记是学生时代的技巧,对付考试用的。但后来被无数次证明,我是错的。
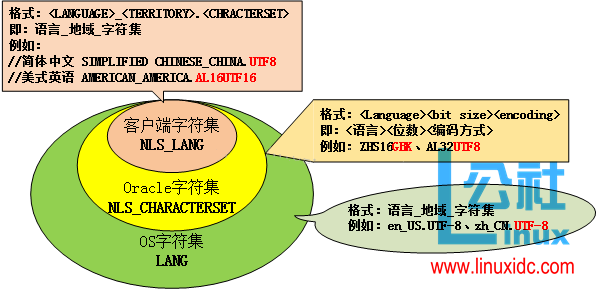
在电子厂,我们开始用 Oracle 时,我总是记不住那些函数,因为文档特别复杂:

从这里可以看到,你要灵活使用存储过程,就不能靠背,而且文档也做到了,让你背不下来。
文档上的例子,看的时候总觉得会了,会了。但真正用的时候,我是 100% 想不到,原来还可以这么用。
比如 SQL 里面的递归。第一眼看到源码,喜的直呼“惊为天人”,就像张无忌得了乾坤大挪移。有了这“屠龙技”,以后对付树状结构,简直秒杀。
但是,一个月过后,完全就不记得,这“屠龙技”的一招半式,更别说去识别隐藏很深的递归模式。理解模式识别,是晋级必经之路。以后会再提。
后来我碰到一个同事,乙方来的。我问他,有什么好的学 Oracle 的方法。你猜他怎么教我的。
他没给我讲项目,也没给我讲看什么书。他把自己整理的一份 Oracle 编程手册,MSN 上传给了我。
当我看到那份手册,看到他整理的函数大纲,原理图解,还有每种问题的不同解法,我瞬间就明白了,“纸上得来终觉浅”。
于是,我花半个月,整理出来一个 Oracle 知识体系,慢慢往里面填内容。就连安装步骤,我也做了 Red Hat, CentOS, Solaris, AIX 版本。
我在即刻上,看到有朋友说,他按照网上博客,搭建了 5 遍也没搞定安装。于是我就这么回了他:

太急于把一件事情做好,反而会乱了心态。不如好好安下心来,碰到问题,解决问题,想明白背后解决的本质,或许会比单纯做成一件事,收获更多。
二,善用搜索,巧搭框架
整理知识框架,工作量大,但非常有意义。在看 SQL Server/Oracle 那段时间,我刚开始,就是记函数,记技巧。常常为递归,动态 SQL ,开窗函数这些小伎俩而沾沾自喜。
直到海量数据统计,数据库崩溃,大量用户堵塞,这些把我打得毫无招架时,我才发现,原来这些 SQL 编程,都不是太难的问题,真正有难度的是维护一个库的高效、稳定、安全。
这开启了我对数据库体系的探索,于是有了以下这些思维导图:
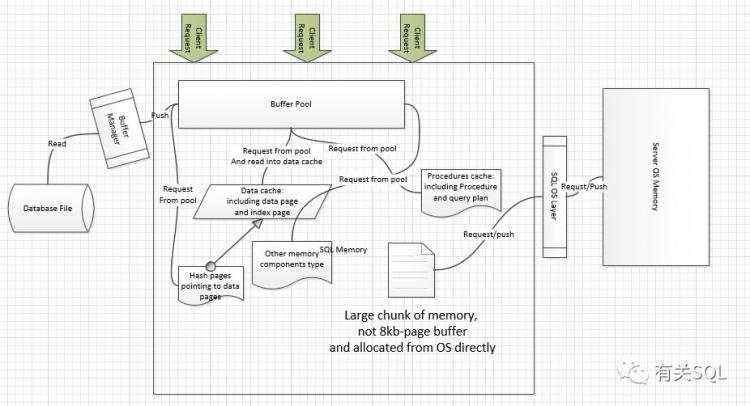
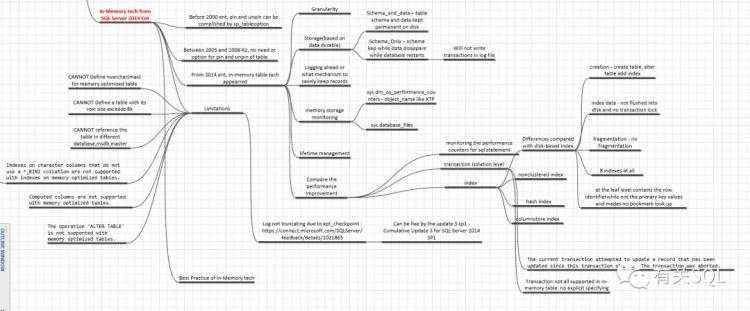
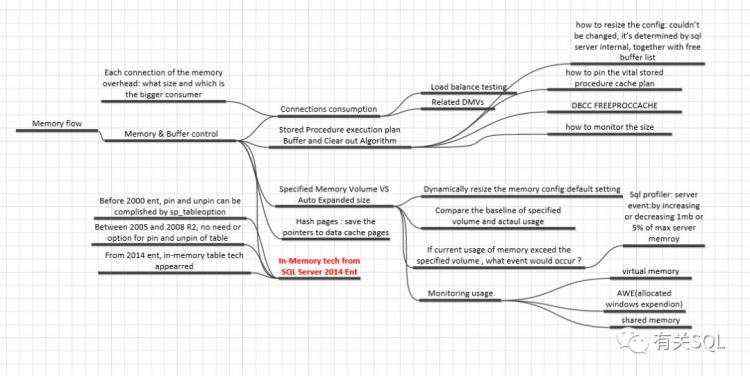
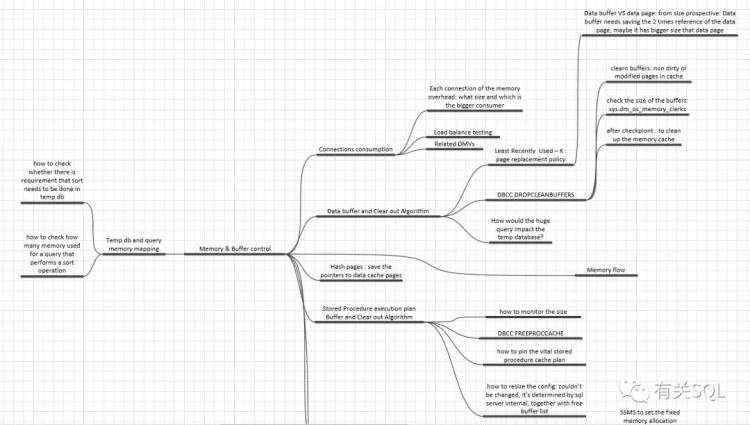
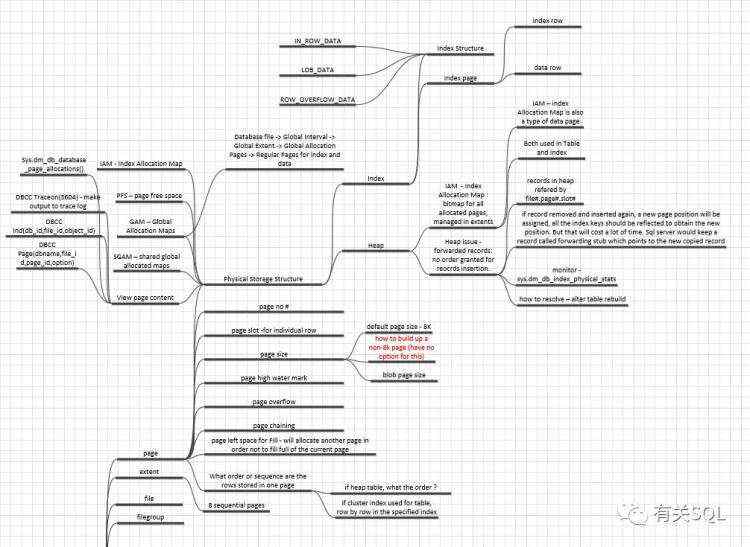
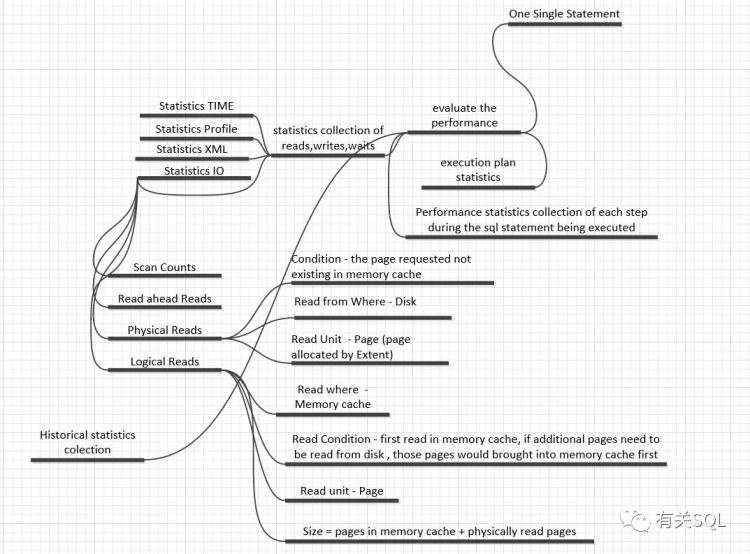
有过这样的整理后,我继续整理了编程语言类的脑图:
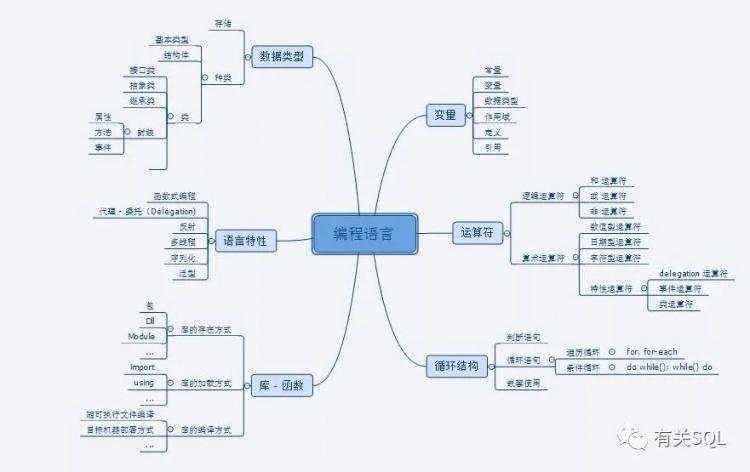
拿着这些脑图,碰到类似的 MySQL, Scala,我就会按图索骥,看看他们是怎么实现已有的 RDBMS/OOP 功能,又有什么新特性需要注意。
于是,当我告诉朋友,Python 上手只要有编程经验,4个小时就可以学会。他表现的十分惊讶。知识框架的迁移,大概率他没有体会过。
那,怎么样才能搭建起自己对行业知识的框架呢。一是阅读;二是搜索
阅读是最基本的技能。在读的过程中,整理出一份属于自己的思维导图,慢慢扩枝散叶,把整个版图无限的扩大。
但仅有读,还不够。得写,写出来是自己懂,而且是真的懂,除非你是在抄书。所以这个写,必须是基于自己实战的写。
说到阅读,并不仅限于读书。书是比较讲全的地方,全方位的讲述知识体系。它的最大弱势,体现在容易落后时代的发展。
比如我在看 Flink 的书,普遍还在讲 Flink 1.1, 1.2, 可官网最新版本,已经是 Flink 1.14 了,如此悬殊的版本差异,做起例子来,自然错误百出。以我这段时间的上手实操,发现最多的问题,都是 ClassNotDefined 相关。
以现在的藏书量,你要看完,才动手做一件事情,几乎很难。读完一本完整体系的书,就要开始往里填东西。切莫说,要等读完所有的书,再去做实验,那就太晚了。等你读完一本,可能又有新书出来了。
除了书,官网,还可以多看些近些年的硕博论文。这些论文,普遍都能嗅到实战的气息。甚至有些论文,就是大厂案例直接写进来的。特别有意义。
前两天我有个读者问我,哪里有银行业的数据维度建模案例可以参考。其实很多时候,去知网搜索下就知道了:
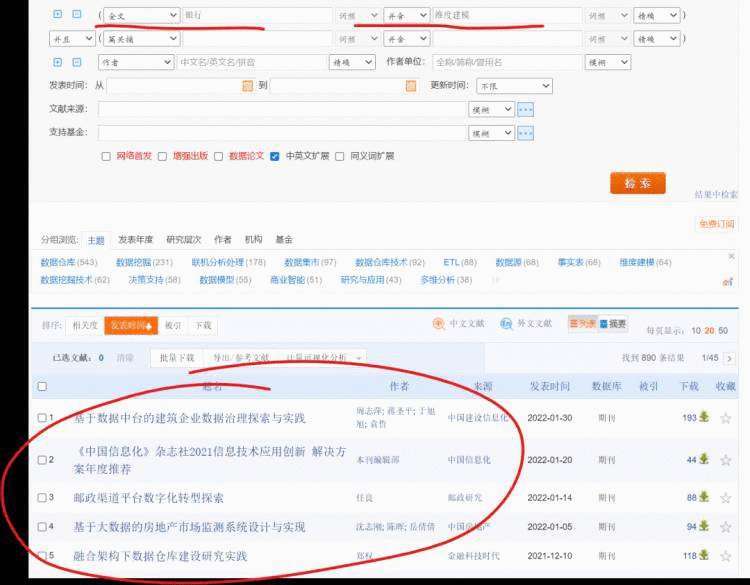
书,网摘(博客,公众号文章),论文,这些都是信息源,过去信息非常闭塞,只有少数人在讨论,在发声,我们想要了解一个技术,行业,往往热衷于混论坛,订阅 RSS.
而现在的互联网,乐于分享的人多了,造成了信息过剩。内容一旦量产,同质化就会很严重,于是判断一个信息源是否可信,就非常关键。
有时候即使付费了,依然得不到有用的信息,时间金钱两丢。
以我的经验,一般会选择书,论文,网文这样的顺序。同一信源中,还要挑选优质的作者,出版社。这就更需要花时间了。
如果有朝一日,我的公众号《有关SQL》能在你的收录名单里,我会非常开心。当然,我会尝试做得更好,写更优质的文章。
世上什么最贵?信任!!!
三,多做多试,勤于记录
相信你身边一定有这样的人,遇到难题请教他们时,他们会很快回答你:哦,这个事情啊,很简单,只要这样这样,那样那样。
或者给他们一些任务时,他们永远反馈:放心吧,这个简单,给我 2天时间,就能搞定。
我见过很多这样的人,事情刚在脑子里登机,结论马上从口里降落了。他们究竟是要展示大包大揽的勇气,还是自己快人一拍的智商?
这些年,啪啪啪打脸的经验告诉我,最危险的,也是收获最小的做事方式:脑子里煮饺子,就是吃不着。说人话,纯靠脑子里的臆想,从来不主动落实,就永无完成日。
大致上,做事情有规律可循:计划,实施,检验,重复,即 PDCA. 这样的做事路径,再配合每次对各个步骤的时间统计,就能估摸出一件事情的时间成本。
就拿学数据库这样的系统性工程,大约学到能干活的程度,需要掌握整个体系的40%。
从整理得到的 RDMBS 体系章节来看,也就是要掌握 6 个知识点,即 SQL, 内存管理,存储结构,事务控制,权限控制,查询引擎,就可以找到一份工作。
那么 6个知识点,乍一看,非常简单。读一遍目录,只要没语言障碍,就那么点东西,2分钟读完了。
此时,脑子给你的反馈就是,撑死 8天。但现实,往往是,就装个 MySQL, 可能 2 天时间就没了。还时不时的连不上,各种给你脸色看。
这个时候,你就会开始怀疑自己的能力和智商了。
解决之道,便是相信记录。事无巨细,哪怕是一个奇怪的异常,都要记录下来。把目前的困境,用过的解决方案,尝试写下来,问题就具象化了。
你的记录越多,越能感知时间的消耗。等到任务完成,立体的时间成本就会向你报到。
我一直推荐,柳比歇夫的笔记方式。做完一件事,及时写上这件事的用时,培养自己的时间观。
让自己变平庸的方式有很多,只用已有的技巧和经验,去不停的解决同一类问题,便是一种。这就是大家深恶痛绝的“卷”,枯燥且无意义!
这篇文章,并不是我一本正经教大家怎么学 SQL,同时也是写给我自己看的,时刻提醒自己,多尝试,多实验。
最后我以最近在学的 Maven, Flink 及 Scala 的任务看板,作为今天的结尾,我和大家一样,也在不断地扩展自己的技术领域,相信不久的将来,我能多写一些其他编程领域的知识。你我共勉!

往期精彩:
本号精华合集(三)
外企一道 SQL 面试题,刷掉 494 名候选人
我在面试数据库工程师候选人时,常问的一些题
零基础 SQL 数据库小白,从入门到精通的学习路线与书单






 京公网安备 11010802041100号
京公网安备 11010802041100号