作者:mobiledu2502934511 | 来源:互联网 | 2023-08-30 17:50
本次的主要任务是利用pytorch实现对GAN网络的搭建,并实现对手写数字的生成。GAN网络主要包含两部分网络,一部分是生成器,一部分是判别器。本次采用的数据库还是MNIST数据集,这里对数据的获取不在赘述。
1、生成器
生成器的主要功能是生成我们所需要的样本,这里是28*28的图片。首先生成长度为100的高斯噪声,并且将噪声通过线性模型升维到784维。激活函数采用Relu。
# 定义判别器 #####Generator######使用多层网络来作为判别器
# 输入一个100维的0~1之间的高斯分布,多层映射到784维class generator(nn.Module):def __init__(self):super(generator, self).__init__()self.gen = nn.Sequential(nn.Linear(100, 256), # 用线性变换将输入映射到256维nn.ReLU(True), # relu激活nn.Linear(256, 512), # 线性变换nn.ReLU(True), # relu激活nn.Linear(512, 784), # 线性变换nn.Tanh() # Tanh激活使得生成数据分布在【-1,1】之间,因为输入的真实数据的经过transforms之后也是这个分布)def forward(self, x):x = self.gen(x)return x
2、判别器
识别器的主要功能是分辨真实图片与构造的图片,实际上就是一个二分类问题,这里采用全连接网络提取特征并进行二分类,也可以利用CNN、LSTM等网络进行特征提取。
# 定义判别器 #####Discriminator######使用多层网络来作为判别器
# 将图片利用LeNet网络进行二分类,判断图片是真实的还是生成的
class discriminator(nn.Module):def __init__(self):super(discriminator, self).__init__()self.f1 = nn.Sequential(nn.Linear(784, 512),nn.LeakyReLU(0.2))self.f2 = nn.Sequential(nn.Linear(512, 256),nn.LeakyReLU(0.2))self.out = nn.Sequential(nn.Linear(256, 1),nn.Sigmoid())def forward(self, x):x = self.f1(x)x = self.f2(x)x = self.out(x)return x
3、定义损失函数
(1)判别器损失
判别器主要实现对真假样本的分类,因此需要将真的图片判断为真,假的图片判断为假。因此需要分别计算两种情况的损失函数相加。
# ########判别器训练train#####################
# 分为两部分:1、真的图像判别为真;2、假的图像判别为假
# 计算真实图片的损失
real_out = self.D(real_img) # 将真实图片放入判别器中
d_loss_real = self.criterion(real_out, real_label) # 得到真实图片的loss
real_scores = real_out # 得到真实图片的判别值,输出的值越接近1越好
# 计算假的图片的损失
z = Variable(torch.randn(num_img, Config.z_dim)).cuda() # 随机生成一些噪声
fake_img = self.G(z).detach() # 随机噪声放入生成网络中,生成一张假的图片。 # 避免梯度传到G,因为G不用更新, detach分离
fake_out = self.D(fake_img) # 判别器判断假的图片,
d_loss_fake = self.criterion(fake_out, fake_label) # 得到假的图片的loss
fake_scores = fake_out # 得到假图片的判别值,对于判别器来说,假图片的损失越接近0越好
# 损失函数和优化
d_loss = d_loss_real + d_loss_fake # 损失包括判真损失和判假损失
self.d_optimizer.zero_grad() # 在反向传播之前,先将梯度归0
d_loss.backward() # 将误差反向传播
self.d_optimizer.step() # 更新参数
(2)生成器损失
# ==================训练生成器============================
# ###############################生成网络的训练
# 希望生成的图片被认为是真的照片,因此需要假图片对应真label的损失,并且更新生成器的参数z = Variable(torch.randn(num_img, Config.z_dim)).cuda() # 得到随机噪声
fake_img = self.G(z) # 随机噪声输入到生成器中,得到一副假的图片
output = self.D(fake_img) # 经过判别器得到的结果
g_loss = self.criterion(output, real_label) # 得到的假的图片与真实的图片的label的loss
# bp and optimize
self.g_optimizer.zero_grad() # 梯度归0
g_loss.backward() # 进行反向传播
self.g_optimizer.step() # .step()一般用在反向传播后面,用于更新生成网络的参数
4、训练模型
import torch
from torchvision import datasets, transforms
import torch.nn as nn
from torch.autograd import Variable
from torchvision.utils import save_image
import osclass Config:device = torch.device('cuda:0')batch_size = 128epoch = 100alpha = 3e-4print_per_step = 100 # 控制输出z_dim = 100# 定义判别器 #####Discriminator######使用多层网络来作为判别器
# 将图片利用LeNet网络进行二分类,判断图片是真实的还是生成的
class discriminator(nn.Module):def __init__(self):super(discriminator, self).__init__()self.f1 = nn.Sequential(nn.Linear(784, 512),nn.LeakyReLU(0.2))self.f2 = nn.Sequential(nn.Linear(512, 256),nn.LeakyReLU(0.2))self.out = nn.Sequential(nn.Linear(256, 1),nn.Sigmoid())def forward(self, x):x = self.f1(x)x = self.f2(x)x = self.out(x)return x# 定义判别器 #####Generator######使用多层网络来作为判别器
# 输入一个100维的0~1之间的高斯分布,多层映射到784维class generator(nn.Module):def __init__(self):super(generator, self).__init__()self.gen = nn.Sequential(nn.Linear(100, 256), # 用线性变换将输入映射到256维nn.ReLU(True), # relu激活nn.Linear(256, 512), # 线性变换nn.ReLU(True), # relu激活nn.Linear(512, 784), # 线性变换nn.Tanh() # Tanh激活使得生成数据分布在【-1,1】之间,因为输入的真实数据的经过transforms之后也是这个分布)def forward(self, x):x = self.gen(x)return xclass TrainProcess:def __init__(self):self.data = self.load_data()self.D = discriminator().to(Config.device)self.G = generator().to(Config.device)self.criterion = nn.BCELoss() # 定义损失函数self.d_optimizer = torch.optim.Adam(self.D.parameters(), lr=Config.alpha)self.g_optimizer = torch.optim.Adam(self.G.parameters(), lr=Config.alpha)@staticmethoddef load_data():transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5,), (0.5,)) # (x-mean) / std])data = datasets.MNIST(root='./data/',train=True,transform=transform,download=True)# 返回一个数据迭代器# shuffle:是否打乱顺序data_loader = torch.utils.data.DataLoader(dataset=data,batch_size=Config.batch_size,shuffle=True)return data_loader@staticmethoddef to_img(x):out = 0.5 * (x + 1)out = out.clamp(0, 1) # Clamp函数可以将随机变化的数值限制在一个给定的区间[min, max]内:out = out.view(-1, 1, 28, 28) # view()函数作用是将一个多行的Tensor,拼接成一行return outdef train_step(self):# ##########################进入训练##判别器的判断过程#####################for epoch in range(Config.epoch): # 进行多个epoch的训练for i, (img, _) in enumerate(self.data):num_img = img.size(0)# view()函数作用是将一个多行的Tensor,拼接成一行# 第一个参数是要拼接的tensor,第二个参数是-1# =============================训练判别器==================img = img.view(num_img,-1)real_img = Variable(img).cuda() # 将tensor变成Variable放入计算图中real_label = Variable(torch.ones(num_img)).cuda() # 定义真实的图片label为1fake_label = Variable(torch.zeros(num_img)).cuda() # 定义假的图片的label为0# ########判别器训练train###################### 分为两部分:1、真的图像判别为真;2、假的图像判别为假# 计算真实图片的损失real_out = self.D(real_img) # 将真实图片放入判别器中d_loss_real = self.criterion(real_out, real_label) # 得到真实图片的lossreal_scores = real_out # 得到真实图片的判别值,输出的值越接近1越好# 计算假的图片的损失z = Variable(torch.randn(num_img, Config.z_dim)).cuda() # 随机生成一些噪声fake_img = self.G(z).detach() # 随机噪声放入生成网络中,生成一张假的图片。 # 避免梯度传到G,因为G不用更新, detach分离fake_out = self.D(fake_img) # 判别器判断假的图片,d_loss_fake = self.criterion(fake_out, fake_label) # 得到假的图片的lossfake_scores = fake_out # 得到假图片的判别值,对于判别器来说,假图片的损失越接近0越好# 损失函数和优化d_loss = d_loss_real + d_loss_fake # 损失包括判真损失和判假损失self.d_optimizer.zero_grad() # 在反向传播之前,先将梯度归0d_loss.backward() # 将误差反向传播self.d_optimizer.step() # 更新参数# ==================训练生成器============================# ###############################生成网络的训练################################ 原理:目的是希望生成的假的图片被判别器判断为真的图片,# 在此过程中,将判别器固定,将假的图片传入判别器的结果与真实的label对应,# 反向传播更新的参数是生成网络里面的参数,# 这样可以通过更新生成网络里面的参数,来训练网络,使得生成的图片让判别器以为是真的# 这样就达到了对抗的目的# 计算假的图片的损失z = Variable(torch.randn(num_img, Config.z_dim)).cuda() # 得到随机噪声fake_img = self.G(z) # 随机噪声输入到生成器中,得到一副假的图片output = self.D(fake_img) # 经过判别器得到的结果g_loss = self.criterion(output, real_label) # 得到的假的图片与真实的图片的label的loss# bp and optimizeself.g_optimizer.zero_grad() # 梯度归0g_loss.backward() # 进行反向传播self.g_optimizer.step() # .step()一般用在反向传播后面,用于更新生成网络的参数# 打印中间的损失if (i + 1) % 100 == 0:print('Epoch[{}/{}],d_loss:{:.6f},g_loss:{:.6f} ''D real: {:.6f},D fake: {:.6f}'.format(epoch, Config.epoch, d_loss.data.item(), g_loss.data.item(),real_scores.data.mean(), fake_scores.data.mean() # 打印的是真实图片的损失均值))if epoch == 0:real_images = self.to_img(real_img.cpu().data)save_image(real_images, './img/real_images.png')fake_images = self.to_img(fake_img.cpu().data)save_image(fake_images, './img/fake_images-{}.png'.format(epoch + 1))if __name__ == "__main__":# 创建文件夹if not os.path.exists('./img'):os.mkdir('./img')p = TrainProcess()p.train_step()
结果展示:
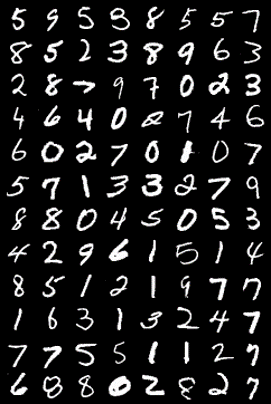

真实样本 训练1个epoch生成的样本


训练50个epoch生成的样本 训练100个epoch生成的样本







 京公网安备 11010802041100号
京公网安备 11010802041100号