作者: | 来源:互联网 | 2023-10-10 16:05
1.背景1.1何为图嵌图嵌入是利用节点属性、节点间拓扑关系将复杂、高维图数据进行向量化的一项技术。图数据结构突破传统数据库按记录组织数据的限制,具备更灵活的现实
1. 背景
1.1 何为图嵌
图嵌入是利用节点属性、节点间拓扑关系将复杂、高维图数据进行向量化的一项技术。
图数据结构突破传统数据库按记录组织数据的限制,具备更灵活的现实数据建模能力。如何将图数据结构中的信息进行合理表征,方便地应用于下游任务成为一个问题。
近年来随着NLP领域预训练词向量技术的流行,图嵌入,也就是图数据向量化也成为了一个越来越活跃的研究领域。
1.2 图数据向量化
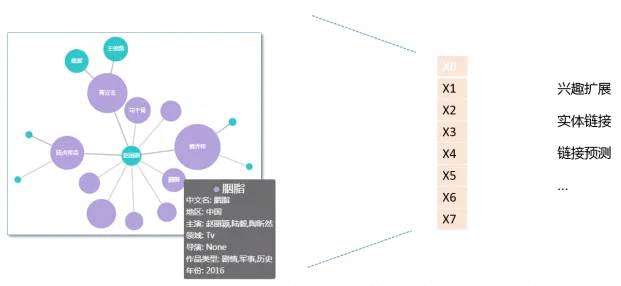
①可以进行相似/相关节点计算、图数据挖掘等下游计算,延伸至内容推荐业务兴趣扩展模块、连接预测;
②也可以将图数据中蕴含的知识编码到深度学习网络中,参与到文本、图像、流媒体等内容理解的计算中。
在本文中,OPPO互联网技术团队针对知识图谱领域数据特性对图嵌入计算的三种思维方法,进行简要介绍。
1.3 通用知识图谱数据的特点
①关系:节点(知识图谱中称实体)之间会存在诸如互为好友、参演作品、作品归属类型等关系;
②属性:每个节点会存在各种各样的属性,比如人物会存在基本信息、背景描述等属性;
③类型:图谱中会存在诸如人物、作品、品牌、景点等类型。
2. 方法
2.1 node2vec
针对图数据中的关系,B. Perozzi等提出DeepWalk模型,开启了随机游走图嵌入的先河。
DeepWalk基本思想如下:
随机选中图中的节点,沿图中的关系进行随机的闲逛,将图数据转化为一段段类似自然语言的序列,然后通过NLP(自然语言处理)领域word2vec对序列中节点的相邻性进行建模,进而得出每个节点的向量。

DeepWalk存在一个问题:游走完全随机,无法根据网络特点(如关系权重)做到对游走进行干预。
Aditya Grover等针对这一问题提出node2vec算法,通过p/q两个参数控制随机游走下一跳的概率分配。

2.2 ANRL
针对图谱中未拆分为关系的属性(诸如描述等拆分后度极低的属性以及其他一些)研究者们提出了很多方法。本文选取其中一种ANRL来进行介绍;
ANRL由Zhen Zhang等提出,思想如下:
通过一个双目标网络,分别对节点属性、关系进行建模,最终得到的图嵌入向量受属性、关系训练数据的制约,得到一个融合了属性和关系信息的图嵌入向量。

2.3 Metapath2Vec
知识图谱通常涵盖若干领域,尤其是通用知识图谱,其中节点的类型更是各式各样。除了其中有实际意义的实体,也会有一些为了属性节点。(诸如国家)
不同类型的节点具有不同的特性:诸如国家可能会与一个电影有地域关系,也会与一个明星有国家归属关系,也会与一个景点有归属关系,也会与一个战斗机有产地关系。
所以不同类型的节点按照相同的规则进行随机游走也会存在一些固有的问题。
事实上,node2vec的随机游走确实会偏向度比较大的节点,另外我们也需要根据业务场景对不同领域的节点进行不同程度的隔离。
Yuxiao Dong等提出MetaPath2Vec算法,算法中将通过类型序列控制随机游走只在特定的类型之间进行游走,当然也可以根据业务特点进行游走概率降权。其主要过程如下:

3. 最后
知识是人类之于机器的优势。现今随着深度学习的发展,AI在很多领域通过大量的监督数据能够高效、精准的完成各种具体的任务。
然而现今深度学习等各种模型尚不能像人类一样进行普世知识积累、联想、推理、想象,或许知识图谱会是AI下一个飞跃的翅膀;事实上,图嵌入、图神经网络领域的研究近几年逐渐成为AI顶会热门话题。
本文是根据OPPO互联网服务项目中实际业务背景,对图嵌入相关技术进行了几个介绍,希望可以起到抛砖引玉的作用。









 京公网安备 11010802041100号
京公网安备 11010802041100号