
想提高机器学习实验的效率,把更多精力放在解决业务问题而不是写代码上?低代码平台或许是个不错的选择。
最近,机器之心发现了一个开源低代码机器学习 Python 库 PyCaret,它支持在「低代码」环境中训练和部署有监督以及无监督的机器学习模型。
-
GitHub 地址:https://github.com/pycaret/pycaret
-
用户文档:https://www.pycaret.org/guide
-
Notebook 教程:https://www.pycaret.org/tutorial
PyCaret 库支持数据科学家快速高效地执行端到端实验,与其他开源机器学习库相比,PyCaret 库只需几行代码即可执行复杂的机器学习任务。该库适合有经验的数据科学家、倾向于低代码机器学习解决方案的公民数据科学家,以及编程背景较弱甚至没有的新手。
PyCaret 库支持多种 Notebook 环境,包括 Jupyter Notebook、Azure notebook 和 Google Colab。从本质上来看,PyCaret 是一个 Python 封装器,封装了多个机器学习库和框架,如 sci-kit-learn、XGBoost、Microsoft LightGBM、spaCy 等。
机器学习实验中所有步骤均可使用 PyCaret 自动开发的 pipeline 进行复现。在 Pycaret 中所执行的所有操作均按顺序存储在 Pipeline 中,该 Pipeline 针对模型部署进行了完全配置。
不管是填充缺失值、转换类别数据、执行特征工程设计,还是调参,Pycaret 都能够自动执行。而且 pipeline 可以保存为二进制文件格式,支持在不同环境中进行迁移。
PyCaret 包含一系列函数,用户通过它们完成机器学习实验。PyCaret 库的函数可分为以下五个大类,涵盖 初始化、模型训练、集成、分析与部署 :
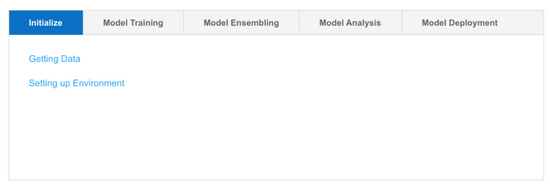
此外, PyCaret 提供 6 个模块,支持有监督和无监督模型的训练和部署,分别是分类、回归、聚类、异常检测、自然语言处理和关联规则挖掘 。每个模块封装特定的机器学习算法和不同模块均可以使用的函数。用户可以根据实验类型,将模块导入环境中。
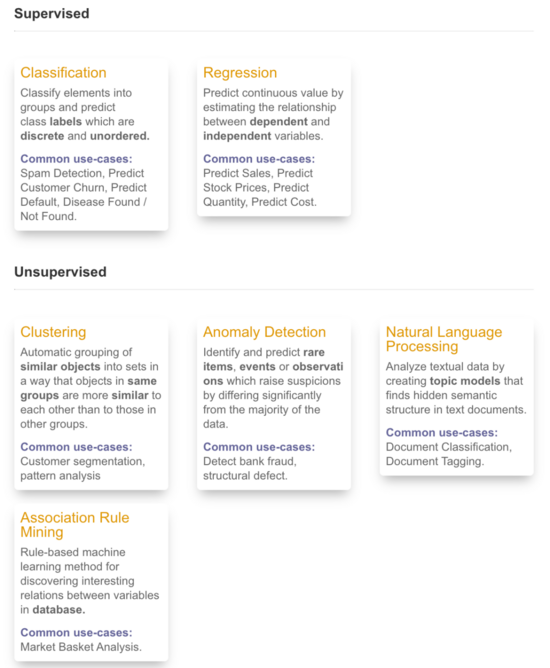
PyCaret 库提供的六个模块。
接下来,我们就来了解一下 PyCaret 库的安装和使用方法吧。
启动 PyCaret
使用 pip 安装 PyCaret。
使用命令行界面或 notebook 环境,运行下面的代码进行安装:
pip install pycaret
Azure notebook 和 Google Colab 用户,可以运行下列代码进行安装:
!pip install pycaret
安装 PyCaret 时会自动安装所有依赖项,过程非常简单,如下图所示:

PyCaret 分步教程
数据获取
该教程使用「糖尿病」数据集,目标是根据血压、胰岛素水平以及年龄等多种因素预测患者的预后情况(1 或 0)。数据集参见 PyCaret 的 GitHub 地址。
直接从 PyCaret 库中导入数据集的最简单方法是使用 pycaret.datasets 模块中的 get_data 函数。
from *pycaret.datasets* import *get_data*
diabetes = *get_data*('diabetes')

get_data 的输出。
PyCaret 可以直接处理 Pandas 数据帧。
环境配置
在 PyCaret 中执行任意机器学习实验的第一步都是,通过导入所需模块并初始化 setup() 来设置环境。如下示例中使用的模块是 pycaret.classification。
模块导入后,将通过定义数据结构「糖尿病」和目标变量「类变量」来初始化 setup()。
from *pycaret.classification* import ***exp1 = *setup*(diabetes, target = 'Class variable')
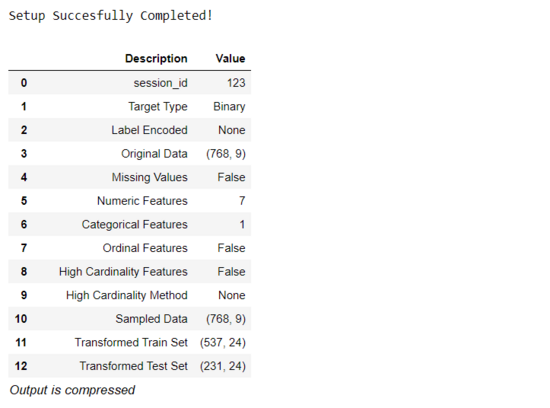
所有预处理的步骤都会应用至 setup() 中,PyCaret 拥有 20 余项功能可运用于 ML 相关的数据准备,例如根据 setup 函数中定义的参数来创建 Transformation pipeline,同时也会自动协调 Pipeline 中所有的相关性及依赖关系。这样面对测试或者未见过的数据集,用户无需再手动管理或是调整执行的顺序。
PyCaret 的 Pipeline 可轻松地在各环境之间相互迁移,比如大规模运行或是轻松部署到生产环境中。下图展示了 PyCaret 首次发布时可用的预处理功能:
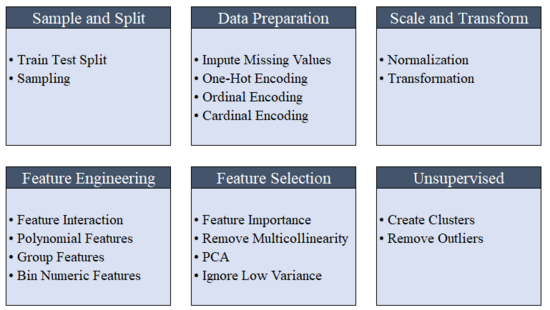
PyCaret 的预处理功能。
数据预处理是机器学习的必要步骤,比如当初始化 setup() 时,缺失值填充、分类变量编码、标签编码(将 yes or no 转化为 1 or 0)以及 train-test-split 会自动执行。
模型比较
这是监督机器学习实验(分类或回归模块)应该进行的第一步。compare_models 函数训练模型库中的所有模型,并使用 k 折交叉验证(默认 k=10)来比较常见的评估指标。所使用的评估指标如下所示:
*compare_models*()
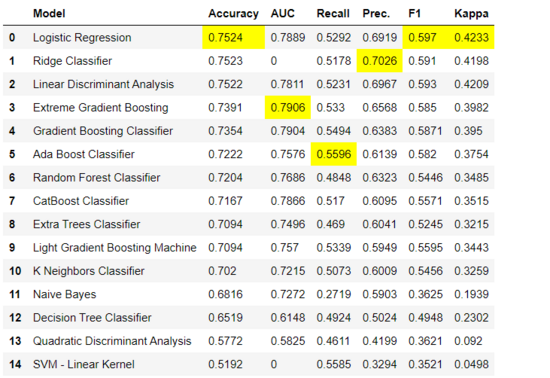
compare_models() 函数的输出。Output from compare_models( ) function
默认使用 10 折交叉验证来评估指标,可以通过改变 fold 参数值来改变评估结果。默认使用精度值(由高到低)来分类 table,同样可以通过改变 sort 参数值来改变分类结果。
模型创建
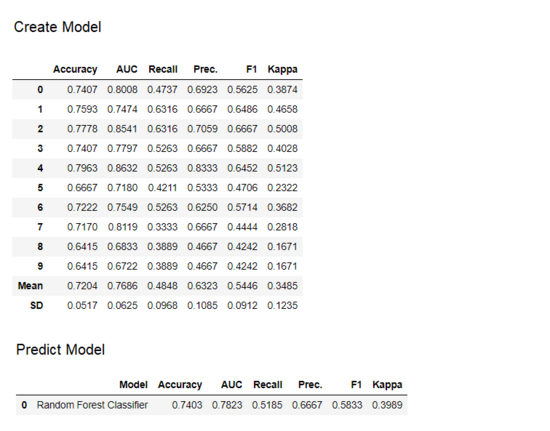
在 PyCaret 的任何模块中,创建模型就像编写 create_model 一样简单,它只需要一个参数,即作为字符串输入来传递的模型名称。此函数返回具有 k 折交叉验证分数和训练好的模型对象的表格。
adaboost = *create_model*('adaboost')
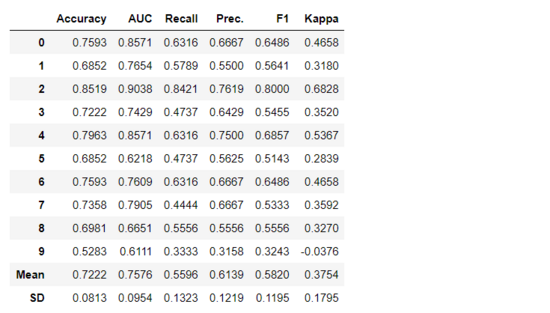
变量「adaboost」存储一个由*create_model*函数返回的训练模型对象,该对象是 scikit 学习估计器。可以通过在变量后使用标点(.)来访问训练对象的原始属性。参见下面的示例:
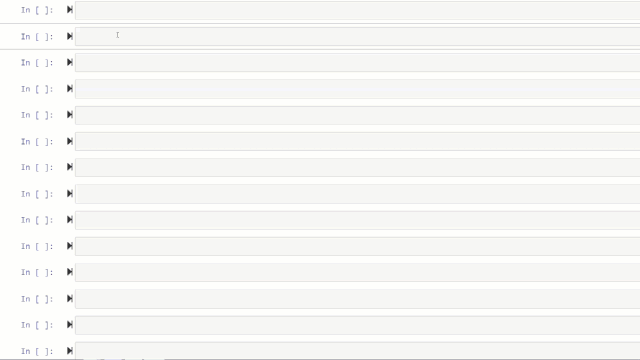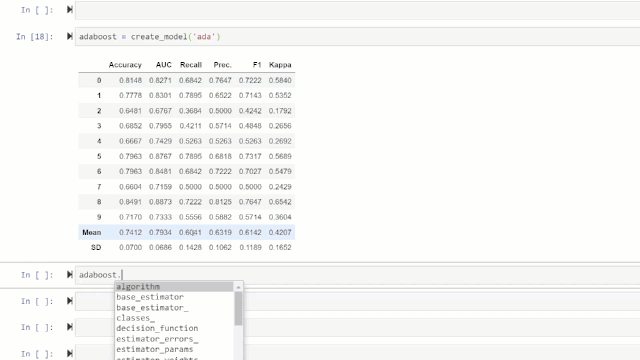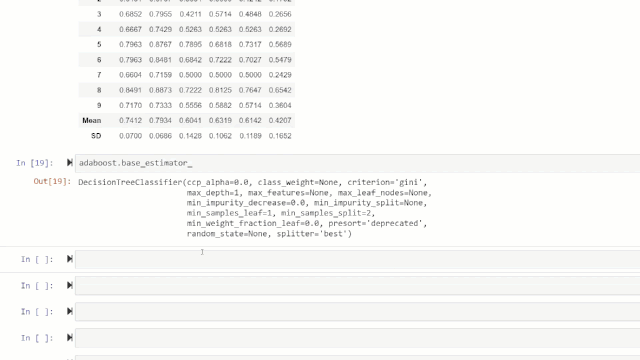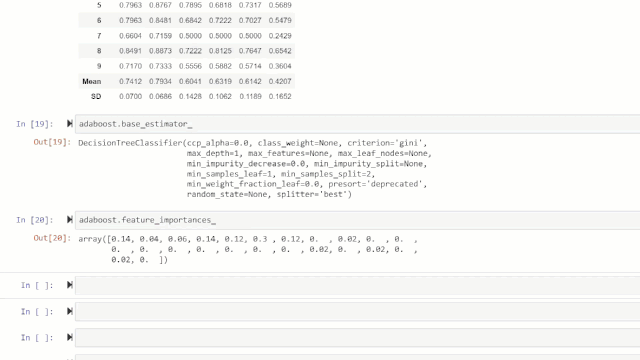
训练好的模型对象的属性。
PyCaret 有 60 多个开源即用型算法。
模型调优
tune_model 函数用于自动调优机器学习模型的超参数。PyCaret 在预定义的搜索空间上使用随机网格搜索。此函数返回具有 k 折交叉验证分数和训练好的模型对象的表格。
tuned_adaboost = tune_model('ada')
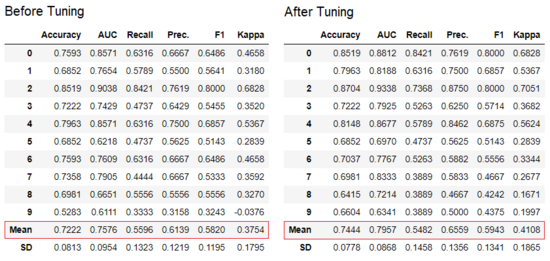
在无监督模块中的 tune_model 函数,比如 pycaret.nlp,pycaret.clustering 和 pycaret.anomaly 可以和监督模块结合使用。举例而言,通过评估监督 ML 模型中的目标或者损失函数,PyCaret 的 NLP 模块可以用来调整准确度或 R2 等指标的数值。
模型集成
ensemble_model 函数用于集成训练好的模型。它只需要一个参数,即训练好的模型对象。此函数返回具有 k 折交叉验证分数和训练好的模型对象的表格。
# creating a decision tree model
dt = *create_model*('dt')# ensembling a trained dt model
dt_bagged = *ensemble_model*(dt)
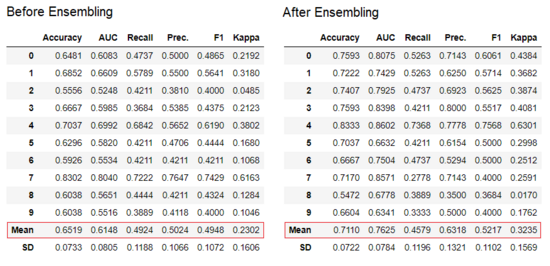
该库默认使用 Bagging 方法用于模型集成,用户也可使用 ensemble_model 函数中的 method 参数将其转换为 Boosting。
PyCaret 还提供了 blend_models 和 stack_models 功能,来集成多个训练好的模型。
模型绘制
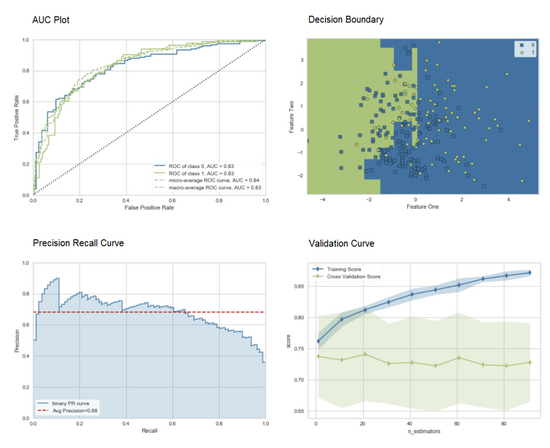
训练好的机器学习模型的性能评估和诊断可以通过 plot_model 函数来完成,具体而言,将训练模型对象和 plot 类型作为 plot_model 函数中的字符串输入(string input)。
# create a model
adaboost = *create_model*('ada')# AUC plot
*plot_model*(adaboost, plot = 'auc')# Decision Boundary
*plot_model*(adaboost, plot = 'boundary')# Precision Recall Curve
*plot_model*(adaboost, plot = 'pr')# Validation Curve
*plot_model*(adaboost, plot = 'vc')
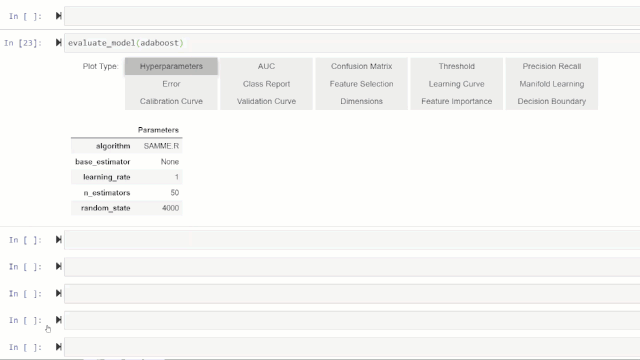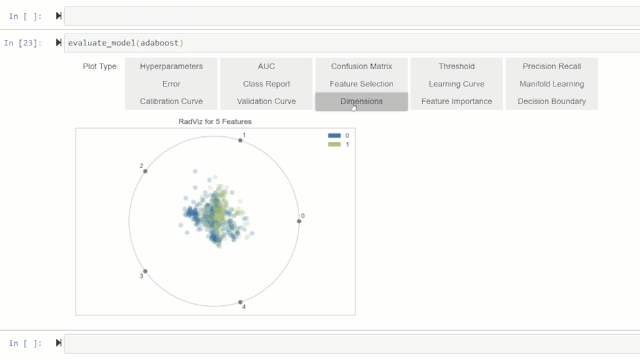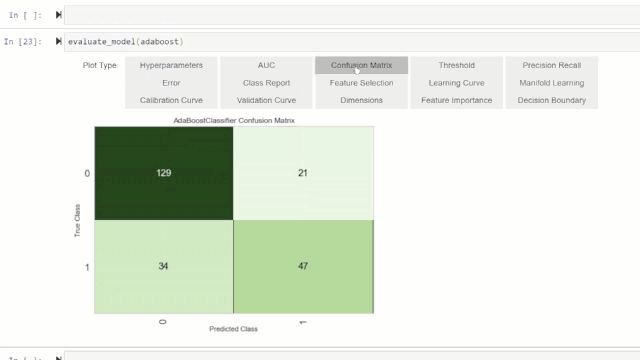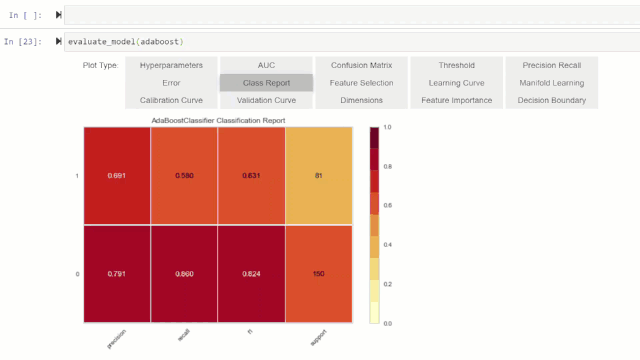
此外,用户还可以使用 evaluate_model 函数在 notebook 的用户界面上看到可视化图。
*evaluate_model*(adaboost)
pycaret.nlp 模块中的 plot_model 函数可用于可视化文本语料库和语义主题模型。
模型解释
数据中的关系呈非线性是实践中常常出现的情况。这时总会看到基于树的模型要比简单的高斯模型的表现好得多。但这是以牺牲可解释性为代价的,因为基于树的模型无法像线性模型那样提供简单的系数。
PyCaret 通过 interpret_model 函数实现了 SHAP(SHapley Additive exPlanations)。
# create a model
xgboost = *create_model*('xgboost')# summary plot
*interpret_model*(xgboost)# correlation plot
*interpret_model*(xgboost, plot = 'correlation')
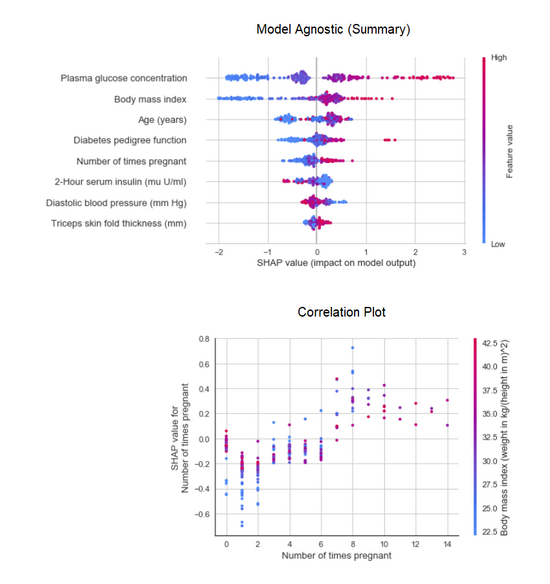
测试数据集上特定数据点的解释可以通过『reason』图来评估。如下图所示:在测试数据集上检查首个实例。
*interpret_model*(xgboost, plot = 'reason', observation = 0)

模型预测
到目前为止,所看到的结果仅基于训练数据集上 k 折交叉验证(默认 70%)。所以为了得到模型在测试或者 hold-out 数据集上的预测结果和性能,用户可以使用 predict_model 函数。如下所示:
# create a model
rf = *create_model*('rf')# predict test / hold-out dataset
rf_holdout_pred* = predict_model*(rf)
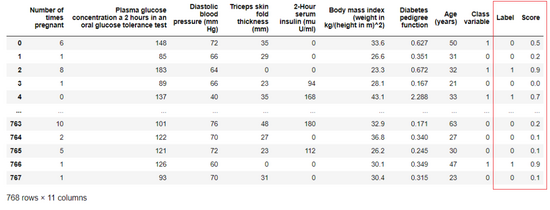
predict_model 函数还可以用来预测未见过的数据集。现在,将训练时所使用的数据集用作新的未见过数据集的代理(proxy)。在实践中,predict_model 函数会被迭代地使用,每次使用都会有一个新的未见过的数据集。
predictiOns= *predict_model*(rf, data = diabetes)
此外,对于使用 stack_models 和 create_stacknet 函数创建的模型,predict_model 函数可以预测它们的序列链。不仅如此,借助于 deploy_model 函数,predict_model 函数还可以直接基于托管在 AWS S3 上的模型进行预测。
模型部署
我们可以使用以下方法让训练好的模型在未见过的数据集上生成预测:在训练模型的同一个 notebook 或 IDE 中使用 predict_model 函数。但是,在未见过的数据集上执行预测是一个迭代的过程。其中,基于用例的不同,预测可以分为实时预测和批量预测。
PyCaret 的 deploy_model 函数允许部署整个 pipeline,包括云端训练的模型。
*deploy_model*(model = rf, model_name = 'rf_aws', platform = 'aws',
authentication = {'bucket' : 'pycaret-test'})
模型/实验保存
训练完成后,包含所有预处理转换和训练模型对象在内的整个 pipeline 能够以二进制 pickle 文件的格式保存。
# creating model
adaboost = *create_model*('ada')# saving model*
save_model*(adaboost, model_name = 'ada_for_deployment')

用户也能够以二进制文件的格式保存整个实验,包括所有中间输出(intermediary output)。
*save_experiment*(experiment_name = 'my_first_experiment')

最后,通过 PyCaret 所有模块中可用的 load_model 和 load_experiment 函数,用户还可以下载保存的模型和实验。






![R语言中向量(Vector)数据类型的元素索引与访问:利用中括号[]和赋值操作符在向量末尾追加数据以扩展其长度](https://img5.php1.cn/3cdc5/92e2/2be/c2a171af6e5eeb5a.png)

 京公网安备 11010802041100号
京公网安备 11010802041100号