首页
技术博客
PHP教程
数据库技术
前端开发
HTML5
Nginx
php论坛
新用户注册
|
会员登录
PHP教程
技术博客
编程问答
PNG素材
编程语言
前端技术
Android
PHP教程
HTML5教程
数据库
Linux技术
Nginx技术
PHP安全
WebSerer
职场攻略
JavaScript
开放平台
业界资讯
大话程序猿
登录
极速注册
取消
热门标签 | HotTags
php7
function
python2
cpython
byte
datetime
cSharp
rsa
ascii
io
jsp
list
php5
hook
foreach
case
dockerfile
settings
web
int
random
request
erlang
main
audio
iostream
require
js
go
python
const
keyword
header
heatmap
sum
include
tree
netty
metadata
integer
chat
object
future
expression
spring
callback
char
runtime
tags
buffer
less
copy
ip
uml
get
php
httprequest
bash
dll
nodejs
uri
substring
bitmap
lua
python3
typescript
plugins
solr
golang
range
command
yaml
hashcode
actionscrip
flutter
cPlusPlus
text
timestamp
install
当前位置:
开发笔记
>
编程语言
> 正文
【技术分享】传统数仓转型,如何避开数据处理的“深坑”
作者:爱lovely壮壮_366 | 来源:互联网 | 2023-05-22 16:16
传统数据仓库的数据处理技术及思考;大数据环境下对于公共数据及行为数据的数据处理处理技术;由传统数据仓库到大数据数据仓库的数据
本文整理自DTCC2016主题演讲内容,录音整理及文字编辑IT168@田晓旭@老鱼。如需转载,请先联系本公众号获取授权!
演讲嘉宾
张粤磊
飞谷云创始人
飞谷云(www.feiguyun.com)创始人,平安付大数据平台架构师。历经了DBA,到开发工程师,再到大数据平台架构师的经历转变,有着10余年各行业(制造,咨询服务,互联网金融)一线数据处理及技术实践经验。
分享内容
我最早是做数仓和ETL架构系统,后来开始做大数据架构,现在在自主创业,做了一个技术分享的网站。这个网站主要是结合我自己目前在做的大数据、数据处理、数据分析的项目,以及圈里朋友的经验技巧来给大家做一些技术分享。
我从2005年开始接触DBA工作,2010年在HP 的TRAM项目中担任ETL开发组长,2012年,在外汇交易中心ETL项目担任开发经理,2014年,在平安付做大数据架构师。在这些年的工作过程中,接触了很多数据库,也有一些数据处理的经验想和大家来分享。
我今天演讲的主要分三个部分,第一部分是分享一下我在传统数据仓库的一些数据处理技术和配置方面的思考;接下来讲一下大数据环境下,公共数据和行为数据的数据处理技术;最后会讲一下从传统数据仓库迁移到大数据数据仓库的数据处理实践思考及建议。
传统数据仓库的数据处理技术及思考
我从自己实际参与的大型数据仓库项目出发,和大家分享一下传统数据仓库的数据处理技术。这个案例融合了我在外资企业、央企、民企、金融行业等等各个行业的项目实践经验,它是涵盖了整个传统数据仓库的标准流程。坦白讲,现在很多企业没有很标准的数据模型。数据模型是国外最早开始做的,比较经典的是惠普和eBay,他们的数据处理和数据模型的领导力比较强,也比较规范和科学,这两个团队在整体数据模型方面有一套成熟的方法论。数据处理方法同样适用整体的数据平台。
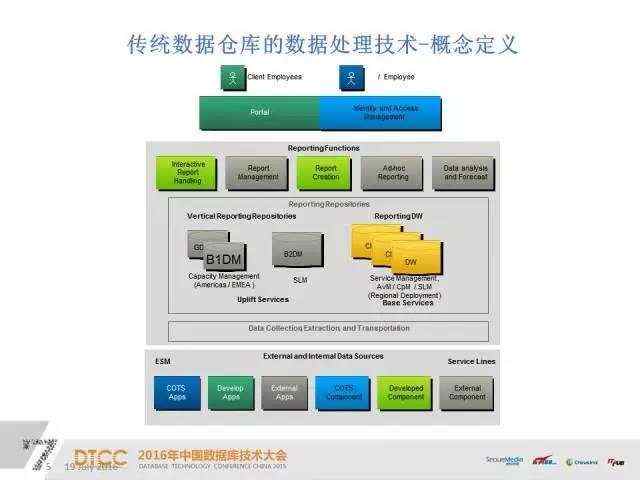
做一个数据管理仓库首先要做概念定义,这个一般是针对大型项目,分为企业内部和客户群体两部分,接下来是Portal和对应的权限管理,中间部分是根据实际业务去定义功能,有些功能是比较经典的,还有一些是根据特定业务场景去设计的。再下面一层是我们整体的数据集成层,再底层就是元数据层。
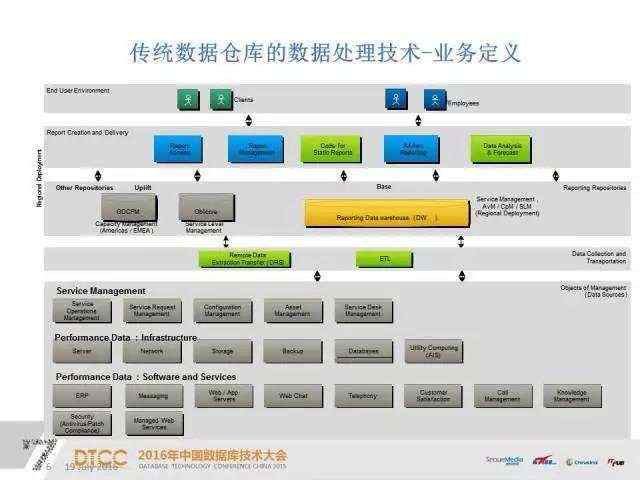
概念定义的产出一般是SOW,用来表明数据治理要做的功能单位。在这之下是业务定义,细化业务、系统功能,包括客户部分对应的联系人以及对应的清单,包括报表需要用哪些数据的实现。如果按实际应用来分的话,假设这是一个IT服务系统,下面会分服务管理和性能管理,性能管理又分硬件和软件的管理。
业务定义之后会有一个业务清单,业务清单里会有详细的业务要求以及相对应的工作项,这样可以保证数据不会出现遗漏,保证业务落实到位。
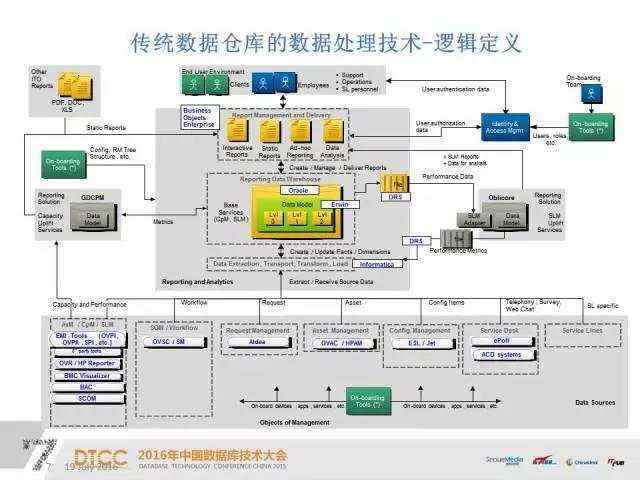
业务定义之后是逻辑定义,逻辑定义划分的就更细了,涉及具体业务怎么实现、由什么来实现。我们通常的做法是选择一些工具来实现报表的权限管理、元数据管理。ETL我们选择了informatics,数据文件的传输,尤其是跨域网站的数据传输,我们也是选用组件来完成的。再底层的话是业务系统,这个业务系统比较详细,一般都会定义到具体的业务名,清单里面也会有系统、接口这些信息。接下来还要进一步细化,比如业务DB的名称后,要去查看它的网段、所在服务器、端口、防火墙等等信息并需要做连通性验证等。这样就实现了从业务层到物理层面的落地。
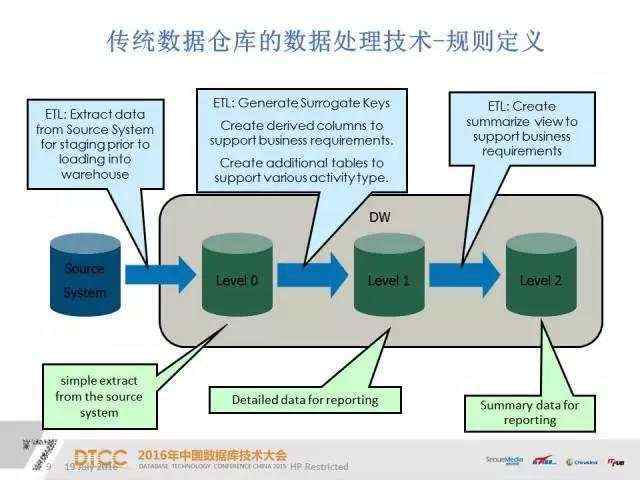
物理层面落地之后就应该进行数据规则定义。规则定义就是要把数据像整理衣柜一样分层治理好,比较经典的就是三层维度模型。从元数据层到数据仓库层再到管理层,把元数据原封不动的抽到对应的数据仓库层。图中的Level 1层主要是数据仓库的技术层,包括维度表和事实表的加载、各业务系统的维度表和事实表的加载、各业务整体维度表的生成以及基于事实表产生对应的维度指标和度量值。这层同时也是整体数据仓库的核心层或生成层。Level 2层主要是为报表服务做一些聚合,根据不同的业务需要会产生按周、按天、按月等等不同维度的报表去维护。
规则定义之后就是具体的设计,这个设计一般就是我们架构组里面的建模组长、ETL组长干的事情,具体的有源系统信息、目标系统信息和ETL抽取。做数据管理首先要做好设计定义,之后你就只需要根据设计文档去做具体的开发实现。图上是我们做的一个设计定义,大家可以参考一下。
我在09-14年之间,做了大概6年的Infomatica的开发和管理工作,在ITPub上还有很多笔记,大家要是有兴趣,可以去了解一下。
做Infomatica比较成熟的是惠普和eBay的,国内对Infomatica比较熟悉的企业应该就是神州数码了,因为神州数码是第一家代理厂商。Infomatica相对Datastag、SSIS来说,元数据管理平台更完善。我们不仅可以从之前的模型定义去实现主数据管理的一致性,还可以将Infomatica跑出来的数据和元数据抽取出来的信息做及时的校验比对。Infomatica后来也有了自己的元数据管理工具,现在也在接触一些Hadoop工具。
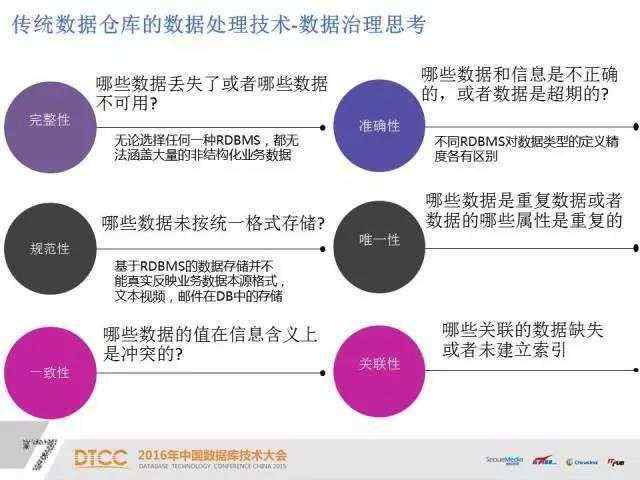
数据仓库的治理六大要素:完整性、准确性、规范性、唯一性、一致性、关联性。下面我主要讲解两点,第一个是完整性,传统的RDBMS无论是哪一种都无法涵盖大量的非结构化业务数据。作为一个数据架构师、数据处理师不应该有依赖工具的思想,任何一个工具都不是完美的。
第二个是准确性,不同RDBMS对数据类型的定义精确度各有不同,当源系统与目标系统属于不同RDBMS或字符集等情况,可能存在字符类型不兼容问题,如:Oracle 的date数据类型有时分秒,而DB2的date数据类型不含时分秒;oracle的Integer数据类型是8字节38位精度,DB2的Integer数据类型是4字节10位精度。
公共数据及行为数据的数据处理技术
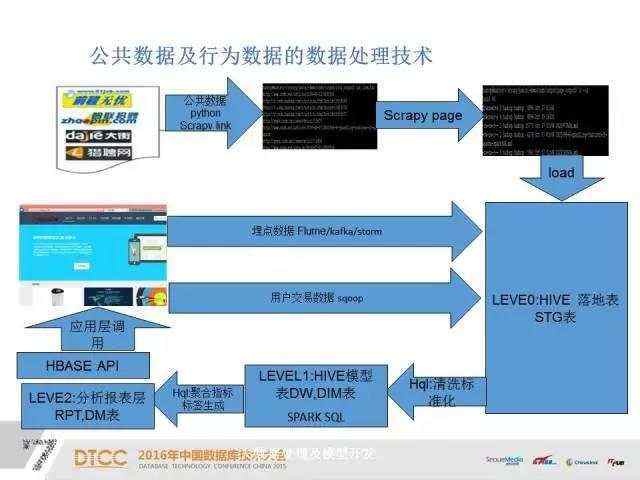
接下来我们讨论一下公共数据及行为数据的处理技术。一般我们处理的数据分为三类,一种是公共数据,常用的获取数据的工具是基于各种语言的爬虫框架,目前流行的是Python。第二种是埋点数据,通常是接入Talkingdata、友盟平台来获取对应的行为数据,或者是自己开发SDK采集工具。第三种是用户及交易数据,此类数据一般存储在结构化数据库中,获取数据的常用工具是SQOOP工具。
数据进入大数据平台的HDFS后,会使用大数据的数据仓库工具HIVE进行数据的ETL和模型构建。这里一般是三层结构:第一层是数据的原始落地层;第二层是数据的集成层,是模型的主要构建层;第三层是数据的分析层,主要用于数据的分析挖掘。
数据经过大数据仓库HIVE基础模型化后,会利用Spark工具对Hive的处理逻辑进行计算引擎的提升,一般会提升10倍左右的计算速度,并利用Spark的ML技术进行数据挖掘分析,SparkR进行图形化分析展现。
大数据经过挖掘分析处理后的统计数据,或需要自定义分析即席报表所需的基础模型表,一般使用HBase或RDBMS来保证查询显示的快速调用和结果反馈。
在处理公共数据的时候应该注意以下几个方面:
1、接口定义加入接口规范变更版本及内容到数据库字段中;
2、落地后的文件时间和成功标志信息同样参与数据处理;
3、在数据仓库处理和分析展示中添加数据处理的可追溯信息;
4、埋点数据一定要符合业务数据信息流才能保证数据处理的完整性和确保数据的业务可用性;
5、行为数据的标识健(UID,DID)要与其它数据源统一关联健和对应时间周期,确保数据的一致性和关联性;
6、行为数据的元数据信息尽可能从源头以字段化方式植入数据处理的数据文件中。
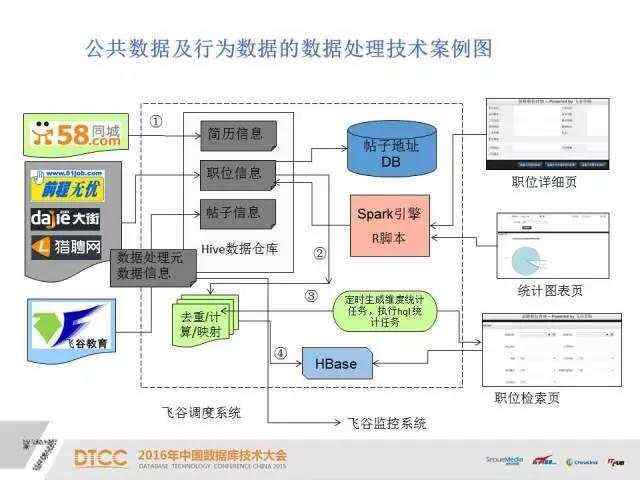
我们从公共数据网站抓取一些信息,然后通过SparkR脚本放到Hive模型里,执行hql任务,生成分析图,最后通过调度系统和监控系统来保证系统的完善统一。
传统数仓到大数据数仓的数据处理
从传统数据仓库到大数据仓库里面应该处理哪些呢?我认为从传统数仓到大数据仓库首要面对的就是数据同步与脱敏。传统数仓是以RDBMS为主要的数据处理存储层,数据库安全级别相对来说比较高。从传统数仓到大数据平台最好的实践方法就是把传统数据仓库与Level 0表全部同步到大数据平台,此时它的数据应该是RDBMS的结构化数据、公共数据和埋点数据全部统一在一起的全样本数据,数据在进入大数据平台后一定要进行脱敏处理,确保数据安全。然后到达以HDFS为主的数据处理层,数据处理的工具要根据数据来源来选择,一般来说,RDBMS采用SQOOP,实时数据采用Kafka、Storm等等。报表层采用自主开发的或者是大数据平台工具。另外,大数据平台一定要注意安全管理。
从传统数据仓库到大数据数据仓库的数据处理的建议:首先数据基因定义一定要完整准确,比如文件从别的地方传输过来,首先要验证文件大小有没有改变,如果没有改变就传一个成功标志位,然后把文件大小、产生时间这些信息添加到数据中,最后将数据整体传到数据层。
其次,数据血缘设计清晰可溯,有时候我们理解写完设计,从最初的源数据一直到最后报表展现的数据,它们之间的关系一定是很清晰的,确保它是可查可控的。
第三,数据安全机制原子化,对数据平台的分层数据做到基于存储机制的原子化安全控制,确保从底层实现数据的安全分层控制。
最后,核心指标及元数据做到可视化和监控自动化,它可以实现元数据数据治理的一个良性循环。通过监控报警发现哪些数据不一致,数据校验的比率、倾斜度超过什么样的指标规则,查看元数据业务或者技术元数据产生的信息,可以及时发现并解决问题。
飞谷云是我们做的一个大数据的平台,现在主要是做数据处理和分析的项目,里面搭建了OpenStack和Hadoop的多种版本。我们和各大公司有经验的技术人员建立了一个社区,主要在数据治理方面为大家做一些技术分享。
关于DTCC
中国数据库技术大会(DTCC)是目前国内数据库与大数据领域最大规模的技术盛宴,于每年春季召开,迄今已成功举办了七届。大会云集了国内外顶尖专家,共同探讨MySQL、NoSQL、Oracle、缓存技术、云端数据库、智能数据平台、大数据安全、数据治理、大数据和开源、大数据创业、大数据深度学习等领域的前瞻性热点话题与技术,吸引IT人士参会5000余名,为数据库人群、大数据从业人员、广大互联网人士及行业相关人士提供了极具价值的交流平台。
数据库
架构
数据分析
port
format
文件
服务器
hadoop
oracle
写下你的评论吧 !
吐个槽吧,看都看了
会员登录
|
用户注册
推荐阅读
python
Python处理Word文档的高效技巧
本文详细介绍了如何使用Python处理Word文档,涵盖从基础操作到高级功能的各种技巧。我们将探讨如何生成文档、定义样式、提取表格数据以及处理超链接和图片等内容。 ...
[详细]
蜡笔小新 2024-12-23 10:40:32
python
SaltStack部署实践(4)JOB管理与Returns模块
目录一、salt-job管理#job存放数据目录#缓存时间设置#Others二、returns模块配置job数据入库#配置returns返回值信息#mysql安全设置#创建模块相关 ...
[详细]
蜡笔小新 2024-12-22 18:53:43
python
Linux环境下C语言实现定时向文件写入当前时间
本文介绍如何在Linux系统中使用C语言编程,实现在每秒钟向指定文件中写入当前时间戳。通过此示例,读者可以了解基本的文件操作、时间处理以及循环控制。 ...
[详细]
蜡笔小新 2024-12-21 21:39:27
python
Python 工具推荐 | PyHubWeekly 第二十一期:提升命令行体验的五大工具
本期 PyHubWeekly 为大家精选了 GitHub 上五个优秀的 Python 工具,涵盖金融数据可视化、终端美化、国际化支持、图像增强和远程 Shell 环境配置。欢迎关注并参与项目。 ...
[详细]
蜡笔小新 2024-12-21 14:45:11
main
Linux 文件输入输出操作
本文介绍了Linux系统中的文件IO操作,包括文件描述符、基本文件操作函数以及目录操作。详细解释了各个函数的参数和返回值,并提供了代码示例。 ...
[详细]
蜡笔小新 2024-12-24 02:33:04
python
如何使用PyCharm及常用配置详解
对于一枚pycharm工具的使用新手,正确了解这门工具的配置及其使用,在使用过程中遇到的很多问题也可以迎刃而解,文中有非常详细的介绍, ...
[详细]
蜡笔小新 2024-12-23 17:32:18
python
深入理解Python函数:定义、调用、注释与参数
本文详细介绍了Python中函数的基本概念,包括函数的定义与调用、文档注释、参数传递(形参与实参)、返回值以及函数嵌套。通过具体示例和解释,帮助读者掌握函数在编程中的应用。 ...
[详细]
蜡笔小新 2024-12-23 17:28:06
int
SQL数据库面试题解析
本文深入探讨了SQL数据库中常见的面试问题,包括如何获取自增字段的当前值、防止SQL注入的方法、游标的作用与使用、索引的形式及其优缺点,以及事务和存储过程的概念。通过详细的解答和示例,帮助读者更好地理解和应对这些技术问题。 ...
[详细]
蜡笔小新 2024-12-22 14:43:35
go
全面解析运维监控:白盒与黑盒监控及四大黄金指标
本文深入探讨了白盒和黑盒监控的概念,以及它们在系统监控中的应用。通过详细分析基础监控和业务监控的不同采集方法,结合四个黄金指标的解读,帮助读者更好地理解和实施有效的监控策略。 ...
[详细]
蜡笔小新 2024-12-22 14:02:29
web
简化报表生成:EasyReport工具的全面解析
本文详细介绍了EasyReport,一个易于使用的开源Web报表工具。该工具支持Hadoop、HBase及多种关系型数据库,能够将SQL查询结果转换为HTML表格,并提供Excel导出、图表显示和表头冻结等功能。 ...
[详细]
蜡笔小新 2024-12-22 11:11:28
go
深入解析CTF中的PWN挑战:Fastbin与堆溢出
本文将探讨2015年RCTF竞赛中的一道PWN题目——shaxian,重点分析其利用Fastbin和堆溢出的技巧。通过详细解析代码流程和漏洞利用过程,帮助读者理解此类题目的破解方法。 ...
[详细]
蜡笔小新 2024-12-21 18:09:12
int
SDN网络拓扑发现机制解析
本文深入探讨了SDN(软件定义网络)中拓扑发现的原理与实现方法,重点介绍了LLDP协议在OpenFlow环境中的应用,并讨论了非OpenFlow设备存在时的链路发现策略。 ...
[详细]
蜡笔小新 2024-12-21 16:18:37
int
从码农到创业者:我的职业转型之路
在观察了众多同行的职业发展后,我决定分享自己的故事。本文探讨了为什么大多数程序员难以成为架构师,并阐述了我从一家外企离职后投身创业的心路历程。 ...
[详细]
蜡笔小新 2024-12-21 15:55:02
int
ElasticSearch 集群监控与优化
本文详细介绍了如何有效地监控 ElasticSearch 集群,涵盖了关键性能指标、集群健康状况、统计信息以及内存和垃圾回收的监控方法。 ...
[详细]
蜡笔小新 2024-12-21 13:43:04
python
Python 条件与循环语句详解
本文详细介绍了 Python 中的条件语句和循环结构。主要内容包括:1. 分支语句(if...elif...else);2. 循环语句(for, while 及嵌套循环);3. 控制循环的语句(break, continue, else)。通过具体示例,帮助读者更好地理解和应用这些语句。 ...
[详细]
蜡笔小新 2024-12-21 12:58:28
爱lovely壮壮_366
这个家伙很懒,什么也没留下!
Tags | 热门标签
php7
function
python2
cpython
byte
datetime
cSharp
rsa
ascii
io
jsp
list
php5
hook
foreach
case
dockerfile
settings
web
int
random
request
erlang
main
audio
iostream
require
js
go
python
RankList | 热门文章
1
linux防火墙配置教程之允许转发实验(2)
2
基于Xshell使用密钥方式连接远程主机
3
Linux与Windows文件互传(VMWare)
4
Linux编程之ICMP洪水攻击
5
Linux中samba服务器的搭建教程
6
Linux修改网卡名称、主机名的方法
7
Linux shell利用sed如何批量更改文件名详解
8
Ubuntu cron日志开启与查看的实现步骤
9
arm linux利用alsa驱动并使用usb音频设备
10
CentOS6.9下NFS服务安装配置教程
11
Linux下文件的切分与合并的简单方法介绍
12
ubuntu中snap包的安装、更新删除与简单使用
13
解决Unixbench安装报错信息的问题
14
浅谈Linux 网络 I/O 模型简介(图文)
15
浅谈Linux的编码及编码转换方法
PHP1.CN | 中国最专业的PHP中文社区 |
DevBox开发工具箱
|
json解析格式化
|
PHP资讯
|
PHP教程
|
数据库技术
|
服务器技术
|
前端开发技术
|
PHP框架
|
开发工具
|
在线工具
Copyright © 1998 - 2020 PHP1.CN. All Rights Reserved |
京公网安备 11010802041100号
|
京ICP备19059560号-4
| PHP1.CN 第一PHP社区 版权所有

























 京公网安备 11010802041100号
京公网安备 11010802041100号