1. 逻辑回归
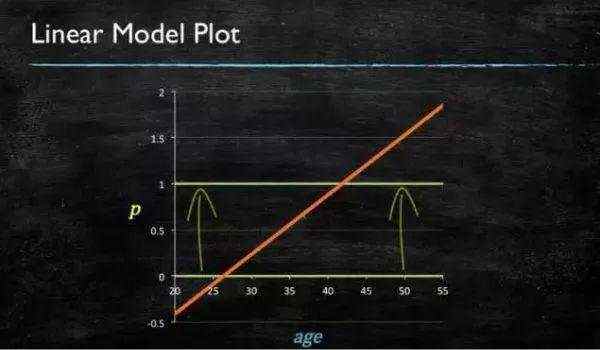
当预测目标是概率这样的,值域需要满足大于等于0,小于等于1的,这个时候单纯的线性模型是做不到的,因为在定义域不在某个范围之内时,值域也超出了规定区间。
所以此时需要这样的形状的模型会比较好
这个模型需要满足两个条件大于等于0,小于等于;大于等于0的模型可以选择绝对值、平方值,这里用指数函数,一定大于0;小于等于1用除法,分子是自己,分母是自身加上1,那一定是小于1的了。
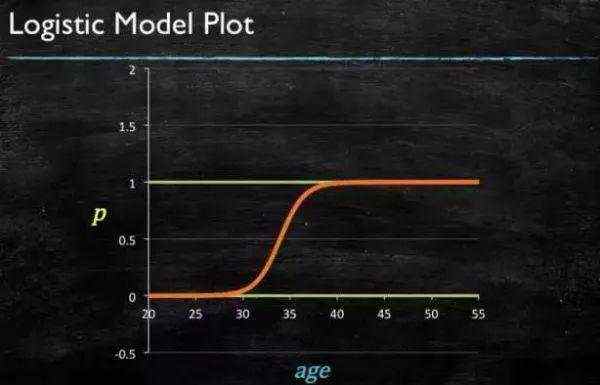
再做一下变形,就得到了 logistic regression 模型
通过源数据计算可以得到相应的系数了
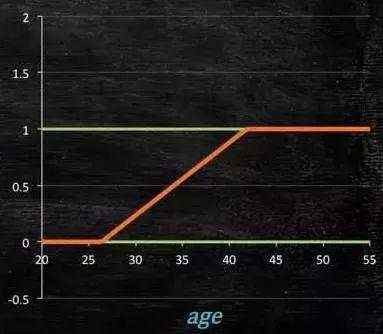
最后得到 logistic 的图形
2. 神经网络
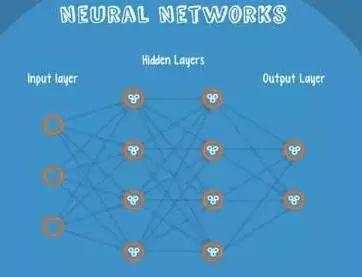
Neural Networks 适合一个input可能落入至少两个类别里。NN 由若干层神经元,和它们之间的联系组成。第一层是 input 层,最后一层是 output 层。在 hidden 层 和 output 层都有自己的 classifier。
input 输入到网络中,被激活,计算的分数被传递到下一层,激活后面的神经层,最后output 层的节点上的分数代表属于各类的分数,下图例子得到分类结果为 class 1。
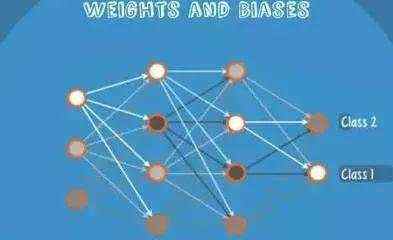
同样的 input 被传输到不同的节点上,之所以会得到不同的结果是因为各自节点有不同的weights 和 bias,这也就是 forward propagation。
3. 朴素贝叶斯
举个在 NLP 的应用,给一段文字,返回情感分类,这段文字的态度是positive,还是negative。为了解决这个问题,可以只看其中的一些单词。
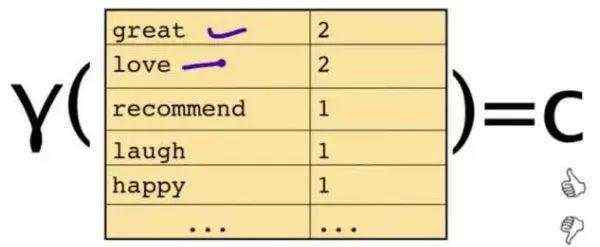
这段文字,将仅由一些单词和它们的计数代表
通过 bayes rules 变成一个比较简单容易求得的问题
问题变成,这一类中这句话出现的概率是多少,当然,别忘了公式里的另外两个概率。
栗子:单词 love 在 positive 的情况下出现的概率是 0.1,在 negative 的情况下出现的概率是 0.001。
编辑:衡力
投稿或者其他事宜,请联系:
zhenjie.zhao@icbc.com.cn

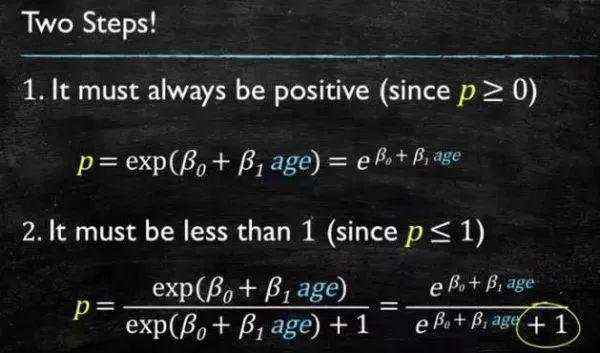

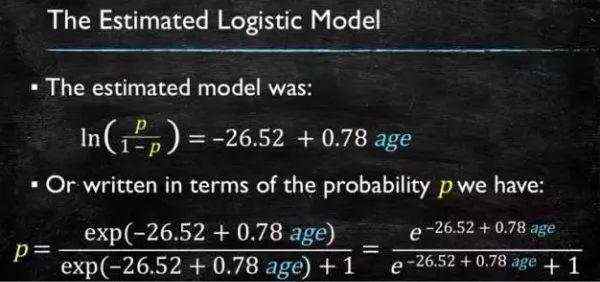




![[译]技术公司十年经验的职场生涯回顾](https://img8.php1.cn/3cdc5/24912/711/b6574f3292f9dc00.png)







 京公网安备 11010802041100号
京公网安备 11010802041100号