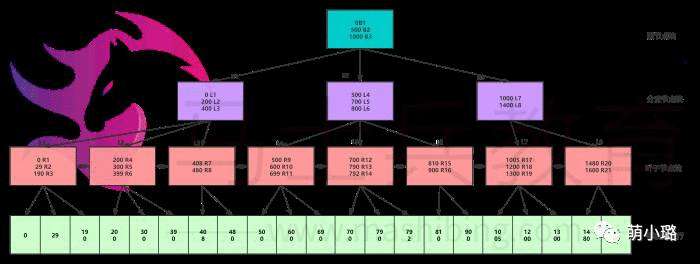

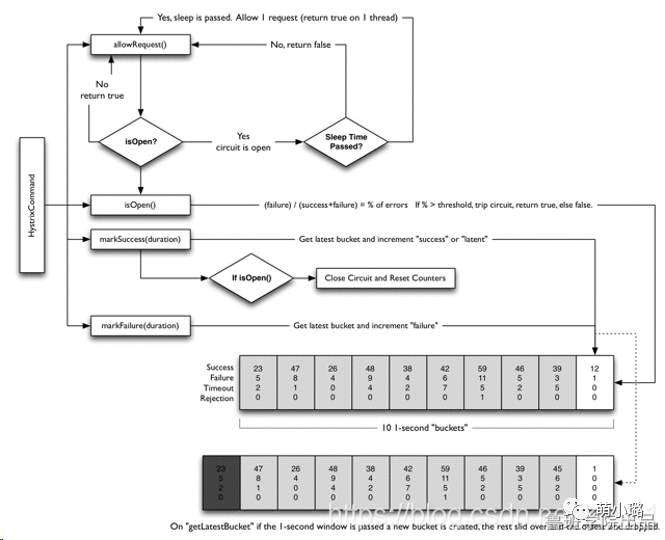
例如,对于一个依赖于30个服务的应用程序,其中每个服务的正常运行时间为99.99%,您可以期望: 99.9930=99.7%正常运行时间 10亿个请求中的0.3%=3000000个失败








 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有