
本节内容主要是对 CAS 操作原理进行讲解,由于 CAS 涉及到了并发编程包的使用,本节课程只对 CAS 的原理问题进行讲解,有助于同学后续对并发编程工具使用的学习。本节具体内容点如下:
了解 CAS 的概念,这是本节内容的基础知识;
了解 CAS 诞生的背景,能够更好地理解 CAS,这是本节的基础知识;
了解 CAS 操作诞生的意义,这也是 CAS 操作的作用所在;
了解 CAS 的操作原理,这也是本节内容的核心知识点,其他知识点都是围绕这一知识点展开的;
了解 CAS 中常见的 ABA 问题,这是本节内容的重点。
概念:CAS 是 CompareAndSwap 的简称,是一种用于在多线程环境下实现同步功能的机制。
从字面上理解就是比较并更新。简单来说,从某一内存上取值 V,和预期值 A 进行比较,如果内存值 V 和预期值 A 的结果相等,那么我们就把新值 B 更新到内存,如果不相等,那么就重复上述操作直到成功为止。
synchronized 时代:在多线程中为了保持数据的准确性,避免多个线程同时操作某个变量,很多情况下利用关键字 synchronized 实现同步锁。
使用 synchronized 关键字可以使操作的线程排队等待运行,可以说是一种悲观策略,认为线程会修改数据,所以开始就把持有锁的线程锁住,其他线程只能是挂起状态,等待锁的释放,所以同步锁带来了效率问题。
synchronized 时代效率问题:在线程执行的时候,获得锁的线程在运行,其他被挂起的线程只能等待着持有锁的线程释放锁才有机会运行,在效率上都浪费在等待上。
在很多的线程切换的时候,由于有同步锁,就要涉及到锁的释放,加锁,这又是一个很大的时间开销。
volatile 时代:与锁(阻塞机制)的方式相比有一种更有效地方法,非阻塞机制,同步锁带来了线程执行时候之间的阻塞,而这种非阻塞机制在多个线程竞争同一个数据的时候不会发生阻塞的情况,这样在时间上就可以节省出很多的时间。
我们会想到用 volatile,使用 volatile 不会造成阻塞,volatile 保证了线程之间的内存可见性和程序执行的有序性可以说已经很好的解决了上面的问题。
volatile 时代原子操作问题:一个很重要的问题就是,volatile 不能保证原子性,对于复合操作,例如 i++ 这样的程序包含三个原子操作:取值,增加,赋值。
意义:从上边 CAS 操作诞生的背景所说的,CAS(Compare And Swap 比较和交换)解决了 volatile 不能保证原子性的问题。从而 CAS 操作即能够解决锁的效率问题,也能够保证操作的原子性。
Tips:在 JDK1.5 新增的 java.util.concurrent (JUC java 并发工具包) 就是建立在 CAS 之上的。相比于 synchronized 这种堵塞算法, CAS 是非堵塞算法的一种常见实现。所以 JUC 在性能上有了很大的提升。
CAS 主要包含三个操作数,内存位置 V,进行比较的原值 A,和新值 B。
当位置 V 的值与 A 相等时,CAS 才会通过原子方式用新值 B 来更新 V,否则不会进行任何操作。无论位置 V 的值是否等于 A,都将返回 V 原有的值。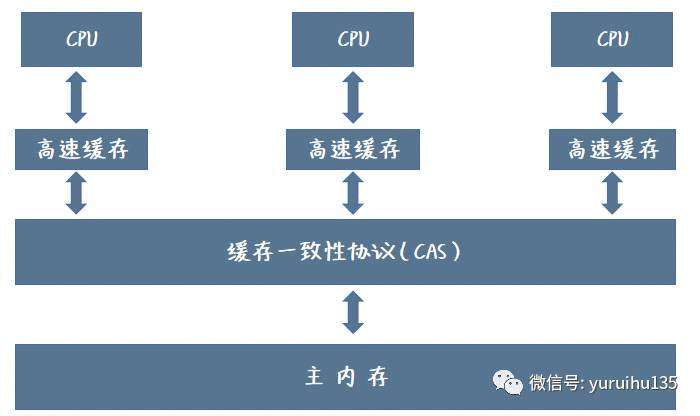
上面说到了同步锁是一种悲观策略,CAS 是一种乐观策略,每次都开放自己,不用担心其他线程会修改变量等数据,如果其他线程修改了数据,那么 CAS 会检测到并利用算法重新计算。
CAS 也是同时允许一个线程修改变量,其他的线程试图修改都将失败,但是相比于同步锁,CAS 对于失败的线程不会将他们挂起,他们下次仍可以参加竞争,这也就是非阻塞机制的特点。
ABA 问题描述:
假设有两个线程,线程 1 和线程 2,线程 1 工作时间需要 10 秒,线程 2 工作需要 2 秒;
主内存值为 A,第一轮线程 1 和线程 2 都把 A 拿到自己的工作内存;
第 2 秒,线程 2 开始执行,线程 2 工作完成把 A 改成了 B ;
第 4 秒,线程 2 把 B 又改成了 A,然后就线程 2 进入休眠状态;
第 10 秒,线程 1 工作完成,看到期望为 A 真实值也是 A 认为没有人动过,其实 A 已经经过了修改,只不过又改了回去,然后线程 1 进行 CAS 操作。
ABA 问题解决:为了解决这个问题,在每次进行操作的时候加上一个版本号或者是时间戳即可。
本节内容的核心知识点即了解 CAS 的操作原理,其他知识点都是围绕这一知识点展开的,对于 CAS 中所引发的 ABA 问题以及该问题的解决方式为本节内容重点。需要对这两点进行着重掌握。
本节内容主要是对 Unsafe 类方法进行介绍,JDK jar 包中的 Unsafe 类提供了硬件级别的原子性操作,Unsafe 类中的方法都是 native 方法,它们使用 JNI 的方式访问本地 C++实现库。
本节我们来了解一下 Unsafe 提供的几个主要的方法进行介绍。为我们后续对 Unsafe 方法的使用奠定良好的基础。
| 方法 | 作用 |
|---|---|
| objectFieldOffset(Field) | 返回指定的变量在所属类中的内存偏移地址,该偏移地址仅仅在该 UnSafe 函数中访问指定字段时使用。 |
| arrayBaseOffset(Class) | 获取取数组中第一个元系的地址。 |
| arrayIndexScale(Class) | 获取数组中一个元素占用的字节。 |
| compareAndSwapLong(Object,long,long,long) | 比较对象 obj 中偏移量为 offset 的变量的值是否与 expect 相等,相等则使用 update 值更新,然后返回 true,否则返回 false。 |
| longgetLongvolatile(Object,long) | 获取对象 obj 中偏移量为 offset 的变量对应 volatile 语义的值。 |
| void putLongvolatile(Object,long,long) | 设置 obj 对象中 offset 偏移的类型为 long 的 field 的值为 value, 支持 volatile 语义。 |
| putOrderedLong(Object,long,long) | 设置 obj 对象中 offset 偏移地址对应的 long 型 field 的值为 value。这是一个有延迟的 putLongvolatile 方法,并且不保证值修改对其他线程立刻可见。只有在变量使用 volatile 修饰并且预计会被意外修改时才使用该方法。 |
| unpark(Object) | 唤醒调用 park 后阻塞的线程。 |
方法描述: void park(booleanisAbsolute,longtime):阻塞当前线程,其中参数 isAbsolute 等于 false 且 time 等于 0 表示一直阻塞。
方法解读:time 大于 0 表示等待指定的 time 后阻塞线程会被唤醒,这个 time 是个相对值,是个增量值,也就是相对当前时间累加 time 后当前线程就会被唤醒。如果 isAbsolute 等于 true,并且 time 大于 0,则表示阻塞的线程到指定的时间点后会被唤醒。
这里 time 是个绝对时间,是将某个时间点换算为 ms 后的值。另外,当其他线程调用了当前阻塞线程的 interrupt 方法而中断了当前线程时,当前线程也会返回,而当其他线程调用了 unPark 方法并且把当前线程作为参数时当前线程也会返回。
| 方法 | 作用 |
|---|---|
| getAndSetLong(Object, long, long) | 获取对象 obj 中偏移量为 offset 的变量 volaile 语义的当前值,并设置变量 volaile 语义的值为 update。 |
| getAndAddLong(Object,long,long) | 方法获取 object 中偏移量为 offset 的 volatile 变量的当前值,并设置变量值为原始值加上 addValue |
本节的核心内容即 Usafe 方法的了解,为下边讲解 Unsafe 方法的使用奠定一个良好的基础。
本节对 Unsafe 类的使用进行讲解,上一小节内容已经对 Unsafe 类的常用方法有了大体的概括,本节主要内容点如下:Unsafe 类的简介,对 UnSafe 类有一个整体的认识;Unsafe 类的创建以及创建过程中避免的异常机制,这是开始使用 UnSafe 类的前提;了解 Unsafe 类操作对象属性方法的使用,这是本节内容的重点之一;了解 Unsafe 操作数组元素方法的使用,也是本节内容的重点之一。
本节内容意在了解并掌握 Unsafe 类的常用方法的使用。
Unsafe 类是 Java 整个并发包底层实现的核心,它具有像 C++ 的指针一样直接操作内存的能力,而这也就意味着其越过了 JVM 的限制。
Unsafe 类有如下的特点:
Unsafe 不受 JVM 管理,也就无法被自动 GC,需要手动 GC,容易出现内存泄漏;
Unsafe 的大部分方法中必须提供原始地址 (内存地址) 和被替换对象的地址,偏移量需自行计算,一旦出现问题必然是 JVM 崩溃级别的异常,会导致整个应用程序直接 crash;
直接操作内存,也意味着其速度更快,在高并发的条件之下能够很好地提高效率。
Unsafe 类是不可以通过 new 关键字直接创建的。Unsafe 类的构造函数是私有的,而对外提供的静态方法 Unsafe.getUnsafe () 又对调用者的 ClassLoader 有限制 ,如果这个方法的调用者不是由 Boot ClassLoader 加载的,则会报错。
实例:通过 main 方法进行调用,报错。
import sun.misc.Unsafe;
import sun.misc.VM;
import sun.reflect.Reflection;
public class DemoTest {
public static void main(String[] args) {
getUnsafe();
}
public static Unsafe getUnsafe() {
Class unsafeClass = Reflection.getCallerClass();
if (!VM.isSystemDomainLoader(unsafeClass.getClassLoader())) {
throw new SecurityException("Unsafe");
} else {
return null;
}
}
}
运行结果:
Exception in thread "main" java.lang.InternalError: CallerSensitive annotation expected at frame 1
at sun.reflect.Reflection.getCallerClass(Native Method)
at leeCode.DemoTest.getUnsafe(DemoTest.java:12)
at leeCode.DemoTest.main(DemoTest.java:9)
报错原因: Java 源码中由开发者自定义的类都是由 Appliaction ClassLoader 加载的,也就是说 main 函数所依赖的 jar 包都是 ClassLoader 加载的,所以会报错。
所以正常情况下我们无法直接使用 Unsafe ,如果需要使用它,则需要利用反射
实例:通过反射,成功加载 Unsafe 类。
import sun.misc.Unsafe;
import java.lang.reflect.Field;
public class DemoTest {
public static void main(String[] args) {
Unsafe unsafe = getUnsafe();
System.out.println("Unsafe 加载成功:"+unsafe);
}
public static Unsafe getUnsafe() {
Unsafe unsafe = null;
try {
Field field = Unsafe.class.getDeclaredField("theUnsafe");
field.setAccessible(true);
unsafe = (Unsafe) field.get(null);
} catch (Exception e) {
e.printStackTrace();
}
return unsafe;
}
}
结果验证:
Unsafe 加载成功:sun.misc.Unsafe@677327b6
代码块1
总结:Unsafe 类的加载必须使用反射进行,否则会报错。
操作对象属性的常用方法有:
public native Object getObject(Object o, long offset):获取一个 Java 对象中偏移地址为 offset 的属性的值,此方法可以突破修饰符的限制,类似的方法有 getInt ()、getDouble () 等,同理还有 putObject () 方法;
public native Object getObjectVolatile(Object o, long offset):强制从主存中获取目标对象指定偏移量的属性值,类似的方法有 getIntVolatile (),getDoubleVolatile () 等,同理还有 putObjectVolatile ();
public native void putOrderedObject(Object o, long offset, Object x):设置目标对象中偏移地址 offset 对应的对象类型属性的值为指定值。这是一个有序或者有延迟的 putObjectVolatile () 方法,并且不保证值的改变被其他线程立即看到。只有在属性被 volatile 修饰并且期望被修改的时候使用才会生效,类似的方法有 putOrderedInt () 和 putOrderedLong ();
public native long objectFieldOffset(Field f):返回给定的非静态属性在它的类的存储分配中的位置 (偏移地址),然后可根据偏移地址直接对属性进行修改,可突破属性的访问修饰符限制。
实例:
import sun.misc.Unsafe;
import java.lang.reflect.Field;
public class DemoTest {
private String name;
public static void main(String[] args) {
Unsafe unsafe = getUnsafe();
try {
DemoTest directMemory = (DemoTest) unsafe.allocateInstance(DemoTest.class);
//获取name属性
long nameOffset = unsafe.objectFieldOffset(DemoTest.class.getDeclaredField("name"));
//设置name属性
unsafe.putObject(directMemory, nameOffset, "并发编程");
System.out.println("属性设置成功:"+ directMemory.getName());
} catch (Exception e) {
e.printStackTrace();
}
}
public static Unsafe getUnsafe() {
Unsafe unsafe = null;
try {
Field field = Unsafe.class.getDeclaredField("theUnsafe");
field.setAccessible(true);
unsafe = (Unsafe) field.get(null);
} catch (Exception e) {
e.printStackTrace();
}
return unsafe;
}
public void setName(String name) {
this.name = name;
}
public String getName() {
return name;
}
}
结果验证:
属性设置成功:并发编程
代码块1
Unsafe 操作数组元素主要有如下两个方法:
public native int arrayBaseOffset(Class arrayClass):返回数组类型的第一个元素的偏移地址 (基础偏移地址);
public native int arrayIndexScale(Class arrayClass):返回数组中元素与元素之间的偏移地址的增量,配合 arrayBaseOffset () 使用就可以定位到任何一个元素的地址。
实例:
import sun.misc.Unsafe;
import java.lang.reflect.Field;
public class DemoTest {
private static String[] names = {"多线程", "Java", "并发编程"};
public static void main(String[] args) {
Unsafe unsafe = getUnsafe();
try {
Class a = String[].class;
int base = unsafe.arrayBaseOffset(a);
int scale = unsafe.arrayIndexScale(a);
// base + i * scale 即为字符串数组下标 i 在对象的内存中的偏移地址
System.out.println(unsafe.getObject(names, (long) base + 2 * scale));
} catch (Exception e) {
e.printStackTrace();
}
}
public static Unsafe getUnsafe() {
Unsafe unsafe = null;
try {
Field field = Unsafe.class.getDeclaredField("theUnsafe");
field.setAccessible(true);
unsafe = (Unsafe) field.get(null);
} catch (Exception e) {
e.printStackTrace();
}
return unsafe;
}
}
结果验证:
并发编程
代码块1
通过对数组的元素的地址进行内存偏移,最后得到的结果为最后一个元素,并发编程。base + 2 * scale 表示字符串数组下标 i 在对象的内存中的偏移地址,偏移两个元素,得到最后一个元素。
本节内容主要对 Unsafe 类的常用方法的使用进行介绍,使学习者能够在使用 Unsafe 类操作对象和数组时,能够快速的使用课程中提供的实例思路。其实 Unsafe 类还可以操作内存地址,操作 CAS,对于初学者来说就比较晦涩了。
此处对操作对象和操作数组常用的方法的讲解,是本节的核心知识,掌握 Unsafe 类的常用方法的使用,非常重要。
本节内容主要是对 Java 多线程锁进行介绍,是对锁的一个全方位的概述,为我们对后续深入学习不同的锁的使用方法奠定一个良好的基础。本节内容的知识点如下:
乐观锁与悲观锁的概念,以及两种锁之间的区别,这是并发编程中经常涉及到的知识点,这是本节课程的核心知识点,是热度很高的必须要掌握的知识,后续还会有专门的小节进行详细讲解;
公平锁与非公平锁的介绍,并发编程中经常涉及到的知识点,需要掌握其概念与区别;
独占锁与共享锁的介绍,并发编程中经常涉及到的知识点,需要掌握其概念与区别;
自旋锁的介绍,对于自旋锁,了解其概念即可。
定义:悲观锁指对数据被外界修改持保守态度,认为数据很容易就会被其他线程修改(很悲观),所以在数据被处理前先对数据进行加锁,并在整个数据处理过程中,使数据处于锁定状态。
悲观锁的实现:开发中常见的悲观锁实现往往依靠数据库提供的锁机制,即在数据库中,在对数据记录操作前给记录加排它锁。如果获取锁失败,则说明数据正在被其他线程修改,当前线程则等待或者抛出异常。如果获取锁成功,则对记录进行操作,然后提交事务后释放排它锁。
实例:Java 中的 synchronized 关键字就是一种悲观锁,一个线程在操作时,其他的线程必须等待,直到锁被释放才可进入方法进行执行,保证了线程和数据的安全性,同一时间,只能有一条线程进入执行。
我们用一段熟悉的代码进行悲观锁的展示。
public class Student {
private String name;
public synchronized String getName() {
return name;
}
public synchronized void setName(String name) {
this.name = name;
}
}
代码分析 :假设有 3 条线程,如下图,线程 3 正在操作 Student 类,此时线程 1 和线程 2 必须要等待线程 3 执行完毕方可进入,这就是悲观锁。

定义:乐观锁是相对悲观锁来说的,它认为数据在一般情况下不会造成冲突,所以在访问记录前不会加排它锁,而是在进行数据提交更新的时候,才会正式对数据冲突与否进行检测。
乐观锁的实现:依旧拿数据库的锁进行比较介绍,乐观锁并不会使用数据库提供的锁机制, 一般在表中添加 version 宇段或者使用业务状态来实现。 乐观锁直到提交时才锁定,所以不会产生任何死锁。
Java 中的乐观锁:我们之前所学习的 CAS 原理即是乐观锁技术,当多个线程尝试使用 CAS 同时更新同一个变量时,只有其中一个线程能更新变量的值,而其它线程都失败,失败的线程并不会被挂起,而是被告知这次竞争中失败,并可以再次尝试。

Tips:我们这里所说的对于乐观锁,当多个线程尝试使用 CAS 同时更新同一个变量时,只有其中一个线程能更新变量的值,而其它线程都失败。注意失败两字,失败意味着有操作,而悲观锁是等待,意味着不能同时操作。
在多线程竞争下,加锁、释放锁会导致比较多的上下文切换和调度延时,引起性能问题;
一个线程持有锁会导致其它所有需要此锁的线程挂起;
如果一个优先级高的线程等待一个优先级低的线程释放锁会导致优先级倒置,引起性能风险。
对比于悲观锁的这些问题,另一个更加有效的锁就是乐观锁。其实乐观锁就是:每次不加锁而是假设没有并发冲突而去完成某项操作,如果因为并发冲突失败就重试,直到成功为止。
分类:根据线程获取锁的抢占机制,锁可以分为公平锁和非公平锁。
公平锁:表示线程获取锁的顺序是按照线程请求锁的时间早晚来决定的,也就是最早请求锁的线程将最早获取到锁。
非公平锁:非公平锁则在运行时闯入,不遵循先到先执行的规则。
ReentrantLock:ReentrantLock 提供了公平和非公平锁的实现。我们本节只做介绍,后续章节会对 ReentrantLock 进行深入的讲解。
分类:根据锁只能被单个线程持有还是能被多个线程共同持有,锁可以分为独占锁和共享锁。
独占锁:保证任何时候都只有一个线程能得到锁,ReentrantLock 就是以独占锁方式实现的。
共享锁:则可以同时由多个线程持有,例如 ReadWriteLock 读写锁,它允许一个资源可以被多线程同时进行读操作。
独占锁是一种悲观锁,由于每次访问资源都先加上互斥锁,这限制了并发性,因为读操作并不会影响数据的一致性,而独占锁只允许在同一时间由一个线程读取数据,其他线程必须等待当前线程释放锁才能进行读取。
共享锁则是一种乐观锁,它放宽了加锁的条件,允许多个线程同时进行读操作。
由于 Java 中的线程是与操作系统中的线程相互对应的,所以当一个线程在获取锁(比如独占锁)失败后,会被切换到内核状态而被挂起。
当该线程获取到锁时又需要将其切换到内核状态而唤醒该线程。而从用户状态切换到内核状态的开销是比较大的,在一定程度上会影响并发性能。
自旋锁:自旋锁则是当前线程在获取锁时,如果发现锁已经被其他线程占有,它不马上阻塞自己,在不放弃 CPU 使用权的情况下,多次尝试获取(默认次数是 10,可以使用-XX:PreBlockSpinsh 参数设置该值)。
很有可能在后面几次尝试中其他线程己经释放了锁。如果尝试指定的次数后仍没有获取到锁则当前线程才会被阻塞挂起。由此看来自旋锁是使用 CPU 时间换取线程阻塞与调度的开销,但是很有可能这些 CPU 时间白白浪费了。
本节内容为锁的基础概念介绍,其中对于悲观锁和乐观锁的讲解,为本节核心知识点,因为这两种锁在数据库的领域也是应用十分广泛。对于本节提到的具体的锁实现,如 ReentrantLock ,我们在后续章节中会有详细的讲解。
本节内容为基础介绍,掌握本节内容的基础上,能够更好地学习后续的章节知识。






 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有