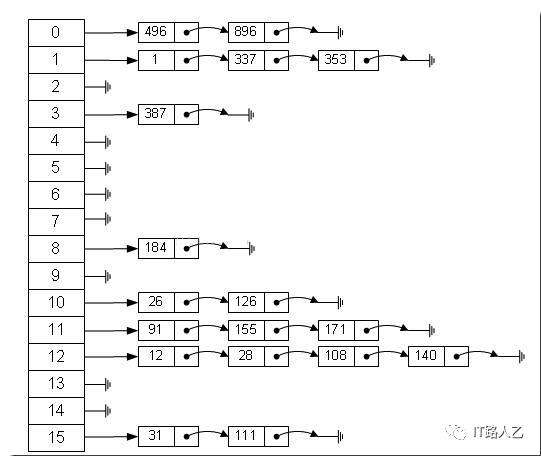
像散列表这么优秀的数据结构没理由不单独挑出来独自咀嚼啊!因此,这部分会重点分析散列表。
散列表
散列表,又叫哈希表,是能够通过给定关键字的值直接访问到具体对应的值的一种数据结构。也就是说,把关键字映射到一个表中的位置来直接访问记录,以加快访问的速度。通常,我们把关键字叫做key,把对应的记录叫做value,也就是说通过key访问一个映射关系来得到value的访问地址。我们称这个映射关系叫做散列函数或者哈希函数,存放记录的数组叫做散列表。某些特殊情况下,通过不同的key,可能访问到同一个地址,这种现象叫做冲突(Collision)。根据上述描述,散列由两个重要部分组成: 散列函数解决寻址问题;散列表解决存储问题。常用的散列函数包括
直接寻址法
取关键字或关键字的某个线性函数的值作为散列地址。设关键字为x,那么散列地址可表示为:
p(x) = x 或 H(x) = ax + b (a、b为常数)
保留余数法
取关键字被某个不大于散列表的表长 n 的数 m 除后所得的余数 p 为散列地址,关键字 x 的数据元素的散列地址为:
p(x) = x mod m
在保留余数法中,选取合适的m很重要,如果选取不当,则导致大量的碰撞。一般情况下,m为素数或者直接用 n时,散列表的分布比较均匀。
数字分析法
通过对数据的分析,发现数据中冲突较少的部分,并构造散列地址。
平方取中法
当无法确定关键字里哪几位的分布相对比较均匀时,可以先求出关键字的平方值,然后按需要取平方值的中间几位作为散列地址。
取随机数法
使用一个随机函数,取关键字的随机值作为散列地址,这种方式通常用于关键字长度不同的场合。
不存在一种万能的散列函数,在任何情况下都是出色的。但是大部分情况下,保留余数法比较好。
当发生冲突时,常见的处理冲突的方法有两种
将溢出的数据元素存放到散列表中没有使用的单元中
常见的处理方法有
开发地址法 :在数组中从映射到的位置开始顺序查找空位置,如果需要,从最后一个位置绕回第一个位置。这种方法碰撞可能引起连锁反应,使表中形成一些较长的连续被占用的单元,如:从1---10的地址全部被使用。从而使散列表的性能降低。
二次探测发 :不直接检查下一个单元,而是检查远离初始探测点的某一单元,以消除线性探测法中的初始聚集的问题。
再散列法 :有两个散列函数H1和H2。H1用来计算探测序列的起始地址,H2用来计算下一个位置的步长。
将映射到同一地址的数据元素分别保存到其他数据结构中
由于地址相同的数据元素个数变化比较大,因此通常采用链表的方式。散列表本身只保存一个指向各自链表中第一个节点的指针。通常使用的方法是链地址法。
散列表在JDK中具体实现有HashMap和ConcurrentHashMap,这里我们简要分析一下HashMap中的实现,ConcurrentHashMap到红黑树的时候分析。那么,HashMap的哈希函数是什么呢?下面我们从源码层面分析,
...
static class Node implements Map.Entry {
final int hash;
final K key;
V value;
Node next;
Node(int hash, K key, V value, Node next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
...
结点数据结构中,包含了结点本身的hash值,结点的key,结点key对应的value和下一个界面的指针。
...
1)
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
...
2)
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
...
3)
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node[] tab; Node p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node e; K k;
if (p.hash == hash &&
...
4)
Node newNode(int hash, K key, V value, Node next) {
return new Node<>(hash, key, value, next);
}
...
我们以2)put函数为切入点,直接可以看出首先调用了1)hash函数计算key值的hash值,然后再委托3)putVal函数将键值对存储到散列表中。对3)putVal函数的分析可知,1)并不是HashMap的哈希函数,那么,它的哈希函数式什么呢?事实上,只要锁定3)putVal函数中的数组下表i就可以了,
i = (n - 1) & hash
因此,HashMap的散列函数为(n - 1) & hash。上述公式中,hash通过1)hash函数计算出来;n是多少呢?打开resize方法,
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 <<4; // aka 16
...
final Node[] resize() {
Node[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap <<1)
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr <<1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node[] newTab = (Node[])new Node[newCap];
table = newTab;
...从源码可以看出,table的长度newCap默认值为DEFAULT_INITIAL_CAPACITY。DEFAULT_INITIAL_CAPACITY默认值为16。所以,n默认值为16。
通过哈希函数找到数组下标之后,如果出现冲突怎么解决呢?HashMap采用的策略是:如果冲突元素8个以内采用单向链表存储;否则,将Node转换为TreeNode采用红黑树存储。代码片段如下
...
static final int TREEIFY_THRESHOLD = 8;
...
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node[] tab; Node p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
...
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
...
首先p被赋值为数组中下标为哈希函数映射值的结点,也就是链表的头结点,然后执行for循环,e赋值为p结点的下一个结点,如果p结点为尾结点,则新生成一个结点,追加到p结点之后,跳出循环;如果p结点不是尾结点,则将p指向p结点的下一个结点(p = e),直到p指向了链表的尾结点,同时,生成新结点追加到p之后,此时,如果结点数量已经大于TREEIFY_THRESHOLD,则执行treeifyBin()函数,
...
final void treeifyBin(Node[] tab, int hash) {
int n, index; Node e;
if (tab == null || (n = tab.length)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode hd = null, tl = null;
do {
TreeNode p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
...函数中,首先将单向链表转换为双向链表(do...while),然后调用根节点的treeify()方法将双向链表转换为红黑树,具体转换过程,在红黑树部分分析。
优点
缺点
适用范围
散列表比较适合无序、需要快速访问的情况。此外,哈希表也可以用来查重处理。








 京公网安备 11010802041100号
京公网安备 11010802041100号