作者:xaony23625 | 来源:互联网 | 2023-08-15 20:12
新冠肺炎疫情依旧严峻,在这场生死时速的战“疫”中,人工智能成为一股不可或缺的力量。近日,在武汉市的各家医院里陆续出现了一批特殊的“工作人员”——机器人,它们灵活地穿梭在医院的隔离区
新冠肺炎疫情依旧严峻,在这场生死时速的战“疫”中,人工智能成为一股不可或缺的力量。近日,在武汉市的各家医院里陆续出现了一批特殊的“工作人员”——机器人,它们灵活地穿梭在医院的隔离区,担负起为医护人员与患者送餐、送药的职责。不仅降低了医护人员被感染的风险,同时也提高了配送效率,节约了一次性防护用品。
在我们身边,人工智能也无处不在。“拿了就走”的Amazon Go、迎宾和导购机器人、智能穿衣镜、货架监测和管理机器人、送Pizza的无人车……在炫酷黑科技的背后,是数字化时代中从生产制造到物流配送、从仓储分拨到终端零售等各环节向着全渠道营销和提升客户体验的不断迈进。
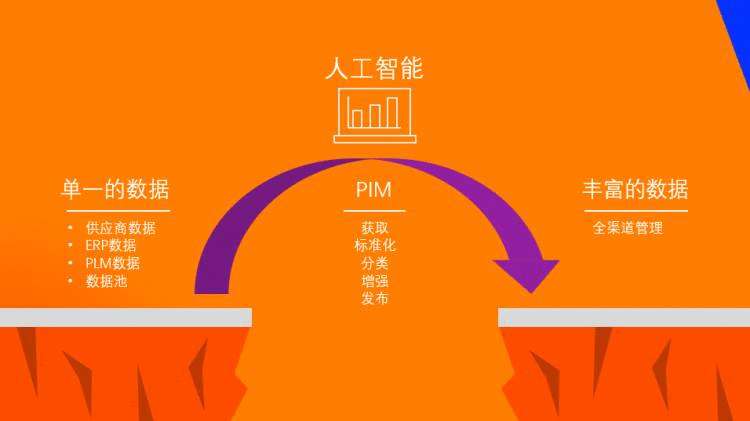
传统的信息化系统大都是基于单一目的而建立,例如之前建立的供应链管理、企业资源管理、生产计划管理、客户关系管理等难以满足数字化时代对数据丰富度的要求,形成巨大的数据鸿沟,选择通过人工智能技术驱动的产品信息管理,才能帮助企业更好地采集数据、实现数据标准化、增强数据丰富程度、对产品数据进行分类发布,最终真正实现全渠道管理。
Informatica数据管理专家——数博士硬核登场,与你相约【Informatica云课堂】,带来首秀——《AI驱动的下一代智能产品信息管理》。
以下是云课堂内容的精彩回顾
▼▼▼
01
机器学习:我读故我在
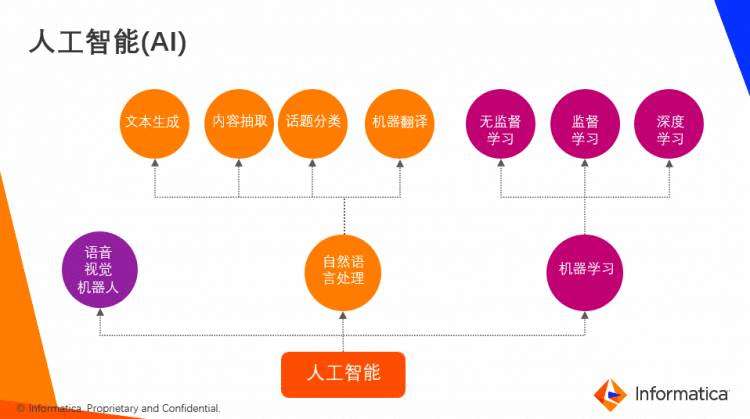
人工智能的读和思是指对自然语言的处理和机器学习。其中自然语言处理,包括文本生成、内容抽取、话题分类和机器翻译。而机器学习则可以分为监督学习、无监督学习和深度学习。
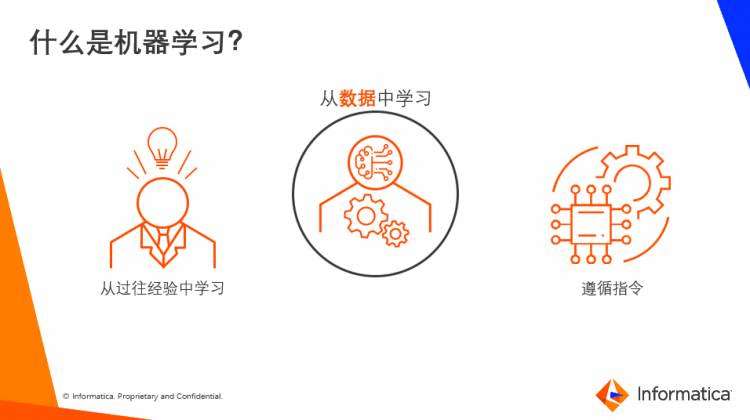
机器学习不同于人。人类通常从他人或自身经验里学习,获得知识;而机器却机械遵循发给它们的指令。他们需要通过编程、训练才能完成工作。而机器学习则把两样东西紧密的结合在一起,它通过数据来学习。准确可信的数据是机器学习成功的关键。
对于有监督学习,你必须把一些特性和属性结合起来——应用这些数据建模并不断采用分类和回归的方法来训练这个模型;而对于无监督学习,你需要借助降维和聚类的方法,找到数据中存在的某些相似性。

人工智能在自然语言中的处理是我们非常常见的。不论是亚马逊的Echo智能音箱,或者小度智能音箱,或是苹果的SIRI语音助手,它们都运用了自然语言处理技术。例如你可以直接用日常交流所用的语言提问:最大的动物是什么?
这时候那些自然语言处理程序就会研究拆解刚才说的句子,试图从中获得元信息。例如“最大的动物是什么”这个问题。首先句子里有一个特定的维度:最大的;还有一个名词:动物。收集到这些信息后,他们会连入Google或百度,搜索相应的答案,再把答案返回给你。

不同于机器学习,自然语言处理主要不是训练数据,而是直接对语言进行解析,这要复杂的多。当你将所有的短语从句子中抽取出来,进行自然语言处理时,解析树就形成了。机器学习通过解析树来提取出元信息,进而理解句子的真正含义。
02
AI驱动的产品信息管理
机器学习与自然语言处理在产品信息管理中有许多应用,常见的包括:分类、属性提取、属性创建以及图像分类:
▼
产品分类
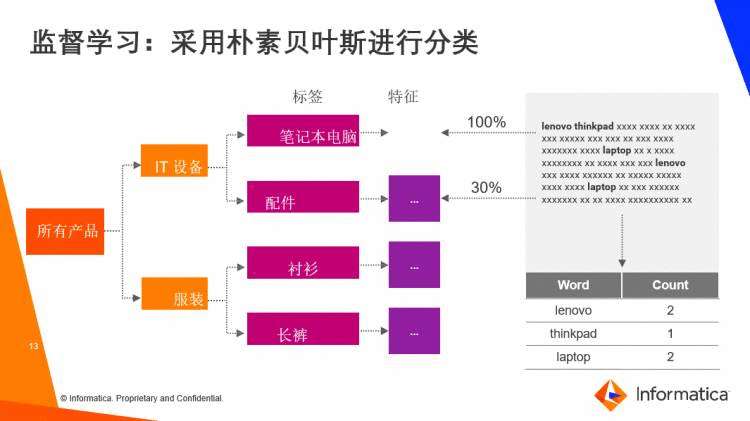
机器学习可以帮助一家拥有海量SKU的零售商进行产品分类,例如将一台拥有复杂配置信息的笔记本电脑分类到各类目录中去。
不过,为了能够使用机器学习来帮助分类,我们需要准备和创建大量的训练数据,即标签的数据。在准备每个类别的训练数据后,就可以使用朴素贝叶斯算法将这个特定的产品进行分类,归到多个层次结构中的某个特定的类别里。其背后的逻辑在于对大量的文本进行分类、匹配、比较:统计出不同的单词在文本中出现的频次,进而得到数据字典。通过机器学习,系统会发现某段文本和“笔记本电脑”这个类别100%匹配,和“配件”这个类别是30%的匹配度。通过这样的训练数据,以后就可以基于类似的文本数据,自动实现产品的分类。
在实际应用场景中,有些客户每天会收到一万多种产品,并且品种会不断的变化。通过采用包含AI技术的Informatica PIM解决方案,他们的效率提升了80%到90%。这就是AI在产品分类中的价值。

▼
属性提取
机器学习可以采用自然语言处理算法来解析文本,识别文本中包含的产品特征,比如这里的型号、CPU、内存等特征,然后将这些特征与库里的“笔记本电脑”这个产品类别进行匹配,自动获得这些信息。
对零售商来说这尤其有用,许多零售商内部系统有很好的产品数据,需要手工从其中提取所有不同的特性,进行简单的复制粘贴操作。
自然语言处理算法可以解析文本,识别文本中包含的产品特征,比如这里的型号、CPU、内存等特征,然后将这些特征与库里的“笔记本电脑”这个产品类别进行匹配,自动获得信息。此外,还可以通过标准化,对提取的特征值进行规范和补充,确保内部数据的一致性。
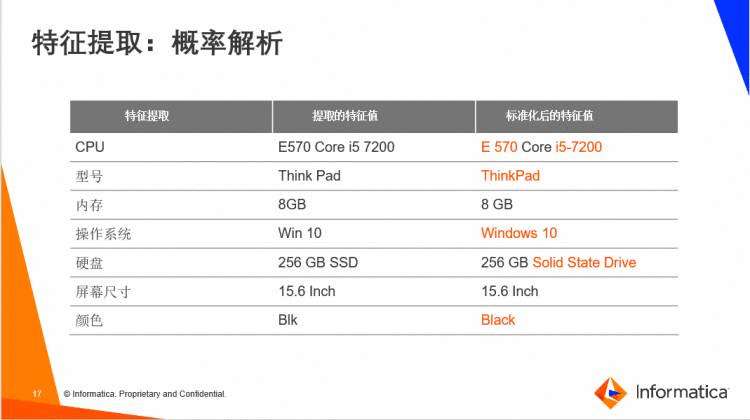
▼
属性创建
基于属性提取我们已经将一台笔记本分门别类,并获得了型号、CPU、内存、硬盘等各种信息。此外还能做什么呢?如何在现有的信息基础上进一步丰富产品信息?这时候K-Nearest Neighbor(kNN)算法就可以大显身手了。
仍以笔记本电脑为例。在“笔记本电脑”这个类别里,还可以从其它类似的产品中得到一些附加属性,比如电池待机时长、保修期,或者电商分类。然后根据这些不同属性和属性值进行统计。在这里例子里,可以看到几个频数较高的属性:比如83.3%的产品电池待机时长是六个小时;83.3%的产品提供两年的保修期;100%的电商分类是“笔记本电脑”。
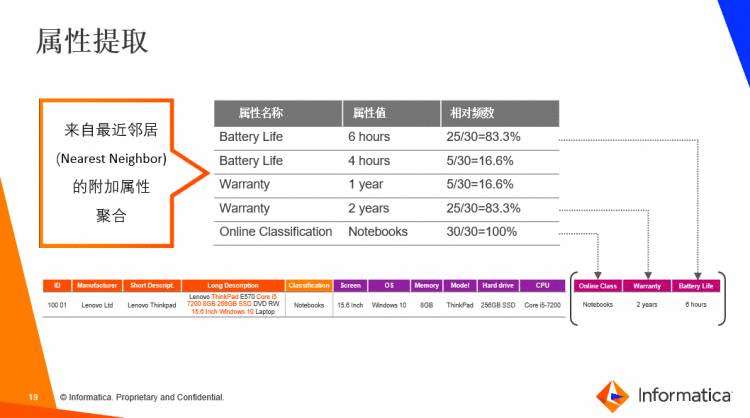
这些从类似产品上获得的额外信息,可以成为非常有用的采购决策判断。
▼
图像分类
机器学习可以帮助一家拥有海量SKU的零售商进
通过从供应商那里获得一张笔记本电脑图片,借助现有的工具,我们可以对许多标签进行分类统计,比如有96%的匹配度是笔记本电脑,90%的匹配是科技,90%的匹配是黑色的。这些标签都是基于机器学习算法自动创建的。在PIM中,可以利用这些技术处理来自不同供应商的不同产品。
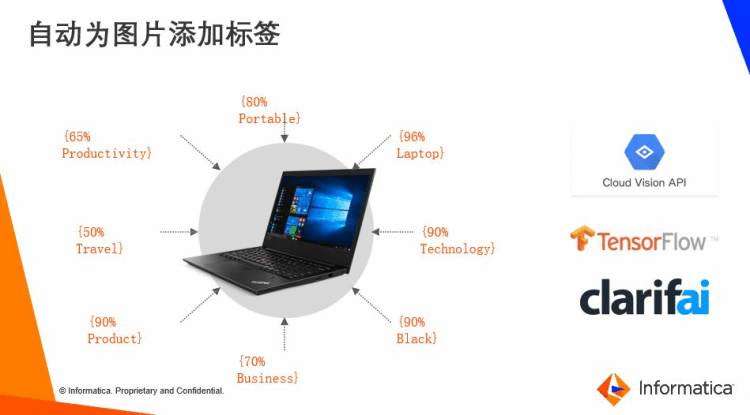
除此之外,自然语言处理与机器学习还能用于采用自然语言生成(NPG)生成文本、使用聚类法查找产品中的差异、寻找交叉销售和增值销售机会,以及基于内容或销售数据自动生成SEO关键字等领域。
03
Informatica PIM提升全渠道体验
基于Informatica的AI引擎Claire,构建在智能数据平台之上,Informatica的下一代PIM解决方案将化解诸多产品信息管理过程中所面临的挑战:
● 产品数据的多样性和不均衡性,以及参差不齐的数据质量。
● 每位客户都有独特的品类结构和特征集。
● 自然语言的描述中,产品描述遵循不同的语法规则。
● 产品数据或许要有多个不同的语言版本。
● ……

AI驱动的下一代智能产品信息管理
产品数据通过供应商、业务用户等多项来源,形成产品数据的中央仓库,为企业内外需要运用产品数据的部门提供了一个智能平台,包括电子商务、数字化营销、产品管理、类别管理、采购等各个部门,以及外部的供应商和合作伙伴。
通过PIM解决方案,各部门与内外部合作伙伴可以更方便的协作,丰富产品的信息,为电商网站、第三方平台、产品目录、社交媒体、线下零售等前端各种销售和市场渠道提供更好的支持。
帮助业务用户以可信、丰富和相关的产品数据做好产品信息管理,实现和内外部伙伴的高效协作,Informatica PIM将致力于提升全渠道的产品体验。
Informatica是PIM解决方案的行业领导者
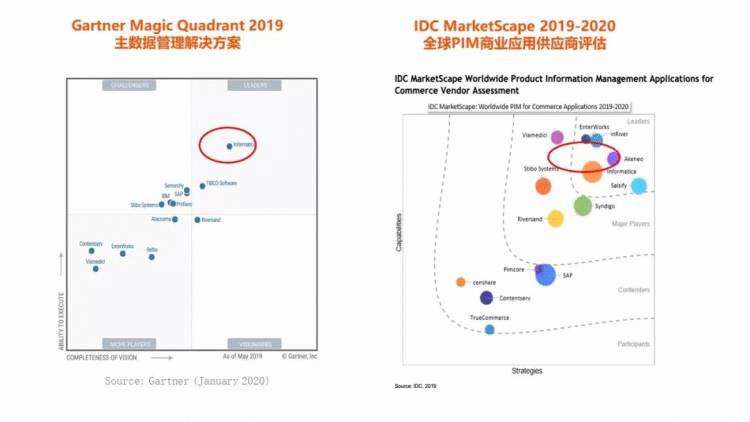
《2020 年 Gartner 主数据管理解决方案魔力象限报告》是 Gartner 第四次发布该报告,也是Informatica 第四次在前瞻性和执行力方面均位居首位。
而在IDC MarketScape报告中,Informatica同样收获肯定,报告中所提及的Informatica优势如下:
● 技术集成:当被问及与外部系统(如ERP、CRM和数字商务)建立技术集成有多容易时,受访客户对Informatica的评价均高于平均水平。
● 数据管理专业知识:Informatica在数据管理领域有很强的影响力,这是其PIM方法的支柱。
● 人工智能战略:受访客户认为Informatica的人工智能/自动化战略远远高于市场平均水平。该公司的CLAIRE人工智能产品旨在实现PIM特定用例的自动化。
该报告还向客户指出:“当您寻找在市场上具有长期业绩的企业级PIM产品、智能数据平台、混合业务模式、广泛的全球PIM/MDM生态系统和本地支持时,推荐考虑Informatica。”
Informatica PIM解决方案已在全球 2,000 多家企业成功实施,使许多大型企业及著名品牌能够进行更为智能高效的产品信息管理。在未来,Informatica还将继续基于数据治理,在AI持续发力,助力更多企业迈向数字化转型的成功。
想了解更多相信信息,请关注Informatica数据管理(微信号:InformaticaChina)





 京公网安备 11010802041100号
京公网安备 11010802041100号