作者:so-sweet天地 | 来源:互联网 | 2023-10-13 10:28
1. 比赛背景
官网介绍:本次比赛以阿里电商广告为研究对象,提供了淘宝平台的海量真实交易数据,参赛选手通过人工智能技术构建预测模型预估用户的购买意向,即给定广告点击相关的用户(user)、广告商品(ad)、检索词(query)、上下文内容(context)、商店(shop)等信息的条件下预测广告产生购买行为的概率(pCVR),形式化定义为:pCVR=P(cOnversion=1 | query, user, ad, context, shop)。
结合淘宝平台的业务场景和不同的流量特点,我们定义了以下两类挑战:
(1)日常的转化率预估
(2)特殊日期的转化率预估
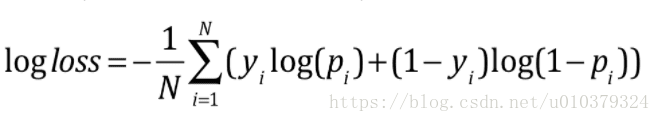
2. 比赛数据
本次比赛为参赛选手提供了5类数据(基础数据、广告商品信息、用户信息、上下文信息和店铺信息)。基础数据表提供了搜索广告最基本的信息,以及“是否交易”的标记。广告商品信息、用户信息、上下文信息和店铺信息等4类数据,提供了对转化率预估可能有帮助的辅助信息。
用于初赛的数据包含了若干天的样本。最后一天的数据用于结果评测,对选手不公布;其余日期的数据作为训练数据,提供给参赛选手。
在上述各张数据表中,绝大部分样本包含了完整的字段数据,也有少部分样本缺乏特定字段的数据。如果一条样本的某个字段为“-1”,表示这个样本的对应字段缺乏数据。
3. 数据预处理
首先,我们针对数据做了一个整体分析:
- 虽然个别数据有缺失值,但均在1%以下,对整个训练结果影响非常轻微。
- 对每个特征进行可视化分析,有些特征符合正太分布,例如:各个用户等级数目,各个店铺的评价等级数目。有些特征符合长尾分布,例如:展示页面点击次数,各个广告商品的销量等级数目。
- 日常的转化率和点击次数都很稳定,周末也相同。特殊日期转化率是正常日期的4倍以上。
3.1 缺失值处理
基于数据基本比较完好,我们不用做什么额外的学习,来补全缺失值,仅通过中位数或者众数补全即可。
当然,我们也需要看看数据中有没有异常数据。对于本题目来说,除了-1代表缺失值来说,没有特别的异常数据。
对于树模型来说,我们可以不做任何处理,因为树模型本身就具有处理缺失数据的能力,而比赛提供的数据缺失值又非常稀少,所以可以忽略。
对于SVM,LR,神经网络模型来说,我们通过中位数,均值,众数任选一补全即可。
3.2 归一化
对于LR,SVM,神经网络等数值运算型的模型来说,数值是否稳定,具有非常重要的意义。
对于长尾分布的数值特征,一般采用取log,再进行最大最小归一化(Min-Max Scaling 又称为Min-Max normalization)
对于正太分布的数值特征,一般采用正则归一化(Z-score normalization)
我们在神经网络wide_deep模型中采用了Min-Max Scaling来进行归一化操作。
对于非数值化的类别特征,我们它进行0-n数值化编码,使之可以分类,也可以作为连续型特征使用。
4. 特征提取
特征主要分成几大类:
- 原始特征。对原始特征进行一些简单处理,例如日期,类别,属性列表等。
- 交叉特征。不同值和值之间的交叉特征。例如性别和商品类别交叉,城市和商品类别交叉等。
- 计数特征。例如均值,最大值,中位数,众数,最小值。
- 比例特征。包括商品转化率,用户转化率等关于转化率特征,以及属性占比特征。
4.1 原始特征
1. 日期特征。我们把单个日期字段(context_timestamp)给拆分出来,分成日(day)和小时(hour)。
2. 商品类别列表。根据数据特点,只有第二个类别有用,我们取item_category_list第二列作为特征。
3. 商品属性列表。我们直接按照排列顺序进行特征拆分。将一个item_property_list拆分成10个特征。
其他原始变化特征:
1. 商品属性数目/商品类别数目。
2. 连续型特征分段。在本赛中用处不大,因为很多数值型特征已经被处理过成level级别的数据了,如果没有处理过的话,可以自己处理,例如年龄分段,店铺评价数量分段。本题中,我们对商店物流评分,服务评分,描述评分,评价评分进行分段。
Tips: 连续型特征分段的好处。
- 避免异常值对模型的影响,例如一个年龄为300的人就会对LR模型造成很大困扰。
- 分段之后可以做离散化(one-hot)处理。例如年龄30岁和35岁,其实兴趣应该变化不大。例如18岁和23岁,人的兴趣会有极大的转变。那我们按10-20,20-30,这样进行处理,并进行离散化,这样能大概区分出10个特征。
- 分段之后就可以与其他离散化特征进行特征交叉操作,挖掘出更多的潜在信息。
- 简化模型特征,降低过拟合风险。
4.2 交叉特征
特征交叉是对两个或者三个或更多个离散化变量进行组合,可以获得非线性的特征,从而获得更多的潜在信息。
举个例子:例如男性对化妆品品类应该不太感兴趣,对运动类品类更有兴趣,女性恰好相反。从特征表达的角度来讲,男性这个特征对化妆品为1,对运动类也为1。品类这个特征不能反应出性别对品类是否感兴趣。于是我们进行特征组合,【性别-品类】。这样 【性别-品类】特征中 男性-化妆品 在男性下为0,在女性下为1。
我们对在该比赛做了以下尝试:
- 用户性别和其他用户信息的两两组合。
- 商品销售信息和其他商品信息的两两组合。
4.3 计数特征
计数特征非常多样,常见的有统计次数,最大值,最小值,均值,众数,中位数等等。
这个比赛的特征主要分成三个对象:商品,商铺,用户。
我们分别对着三个对象进行特征描述。下面以用户为例子:
- 关于用户的各类均值特征,主要是对关于商品和商铺求均值。例如:平均消费商品价格,平均商品销量水平,平均商铺评分。
- 用户关于item_id 和 cat_id 的时间差特征。
- 统计用户当天该次点击之前的点击次数。
- 是否为用户第一次点击,中间点击,最后一次点击。
4.4 比例特征
比例特征是特征中重要性非常高的一类特征,因为比起交叉特征,更能体现出用户的兴趣,以及商品的内在特质。从特征角度来说,他是分布在0-1之间的稠密性连续型特征,比起0-1类特征包含了更多的信息。而且它数值波动小,更适合模型去拟合。
比例特征包括各类组合特征的统计,以及出现次数比例统计,以及相关转化率统计。下面以用户例子:
- 计算关于用各个性别中的各个年龄比例,各个职业占比比例,各个用户等级级别比例。同理可得。
- 用户属性和商铺对象属性,商品对象属性的交叉。例如各个用户性别中各个商品销量等级比例,比如男性用户中商品销量等级为1的商品的占所有男性用户商品的比例。
- 各类属性转化率特征。用户转化率,用户性别转化率,用户职业转化率等。
4.5 其他特征
这个比赛我们后期没有取得很好的单模型效果,与前排大佬的最好单模型效果差了接近2个千分点。我猜测主要原因是没有利用好广告预测属性和商品本身属性,我们只是对比了一下广告预测属性和商品本身属性是否相同这一特征。
本次冠军在github上分享了他的处理思路:主要是通过属性来描述用户对属性的偏好,从而得到足够的信息来判断用户转化率。
- 对属性做one-hot处理(但是由于属性ID太多,one-hot内存爆炸,很好奇冠军是怎么处理的,后期再更新)
- groupby 用户ID,对每个属性出现次数做一个均值处理,当作用户的偏好特征
- groupby 商品ID,对上述得到的用户属性偏好均值再求均值,得到商品的均值偏好特征。
本次比赛冠军分享:商品属性处理
5. 特征选择
这个比赛让我感受到,特征选择不是必须的,如果你特征构建的好的话,全部都用上是一个不错的选择。但是如果你特征实在是太多了,可以通过特征选择选择出多个效果相似,但是差异性较大的特征子集。这样我们在后期融合的时候,可以得到较大的提升。另外,由于初赛数据集太小,所以特征选择出现了很好的效果,一般来说,特征越多引入的噪音也越多。
特征选择一般有三种方法:1. 过滤式(filter)2. 包裹式(wrapper)3. 嵌入式(embedding)
- filter式比较简单。主要就是一个打分函数,对每个特征打分,然后根据规则选择特征。例如信息增益(可以根据树模型得到),卡方检验(检验特征与结果分布的独立性),皮尔逊相关系数。
- 包裹式就比较消耗时间。主要是逐个或者随机加入特征,再训练模型检验效果是否提升,如果是则加入,如果否则抛弃。有很多启发式算法可以应用在其中,例如粒子群,退火算法。该方法在比赛中应用最广。
- 嵌入式为L1正则式。
在复赛情况下,由于数据量太大,有前排大佬分享,可以通过线上线下数据对特征先做一个检测,如果分布不同则直接去除掉,减少特征子空间。之后再通过启发式算法进行特征选择。通过选择出多套结果优秀且不同的特征子集后,进行模型融合。
6. 模型构建
对于这种比赛,亲测lgb和xgb效果是别的模型无可比拟的。wide_deep 和 wide_cross 神经网络模型无法也超越这两个树模型。
对于lgb,xgb为什么在各个比赛中大显身手,乃至无可比拟。个人觉得是因为
- 特征偏少,最多也在百和千这个量级。
- 特征稠密,多数为连续数值型特征。
- 特征和预测结果存在着大量的非线性关系。
- 训练数据量偏少,复赛中虽然共有1000万数据,但是实际上真正可用的也就是特殊日期那一天的上午100万条。
- 特征构成复杂,既有连续型特征,也有数值型特征。
7. 模型融合
我们尝试了传统的stacking方法,效果不好,原因不详。
冠军把前7的数据对特殊日期进行预测,把预测结果作为特征输入到特殊日期模型中,我觉得是一个很好的想法,之前一直想怎么利用好前7天的数据,也只是想在加入更多的数据量这个层面上思考,并没有思考说做一个模型进行预测。但是我们有把wide_deep神经网络的输出结果当作特征输入xgb模型中,注意输入之后一定要有不同(要么之后模型的特征空间不同,要么是模型的数据集不同),所以输入之后我们在训练xgb的时候删掉了wide_deep用到的特征。
我们后来试了一个融合的骚操作,就是依据下面这个公式,但是进行逆向融合,也就是先求逻辑函数的逆操作,然后进行逻辑函数操作,融合提升了一个万分点。

8. 比赛总结
这场比赛有几个失误的点:
1. 初赛很认真地做了各种特征分析,特征分布,乃至把预测属性和真实商品属性也考虑了,在复赛中却没有静下心来再次分析。(也是下意识觉得初赛和复赛数据分布应该差不多,结果啪啪啪打脸)
2. 在复赛中没有好好做特征选择,而是盲目用了全部特征进行训练,导致模型提升很被动。(其实也有因为初赛最后所有特征加起来比特征选择结果好的因素)
3. 没有划分好线下预测集。这个问题特别大,因为不能在线下很好地预估模型的效果,包括特征选择和模型调优都存在过拟合的风险。必须要划分好预测集,使得线下线上同升同降,这样能大大减少工作量。
总的来说,还是很感谢两位队友,一位来自西电,一位来自浙大。作为第一次参加的萌新,能取得初赛第7,复赛第23名的成绩还是感到满足。





 京公网安备 11010802041100号
京公网安备 11010802041100号