作者:四川盛地地产顾问有限公司_255 | 来源:互联网 | 2024-11-21 11:40
本文介绍了如何使用Python及其相关库(如NumPy、scikit-learn和matplotlib)构建KNN分类器模型。通过详细的数据准备、模型训练及新样本预测的过程,展示KNN算法的实际操作步骤。
在本文中,我们将使用Python 3.6、NumPy 1.14、scikit-learn 0.19以及matplotlib 2.2等库来构建一个K近邻(K-Nearest Neighbors, KNN)分类器。KNN是一种基于实例的学习方法,用于解决分类问题,其核心思想是在特征空间中找到与待分类样本最近的K个训练样本,并根据这K个样本的多数类别来决定待分类样本的类别。
1. 数据准备
数据准备阶段包括数据的加载与可视化。这一部分相对直观,主要目的是通过图表展示数据的分布情况,以便于后续分析。以下是数据分布的示例图:

2. KNN分类器的构建与训练
2.1 模型构建与训练
构建KNN分类器的过程类似于其他机器学习模型,如支持向量机(SVM)和随机森林(Random Forest)。下面是使用scikit-learn构建KNN分类器的代码示例:
# 导入必要的库
from sklearn.neighbors import KNeighborsClassifier
# 定义K值
K = 10
# 创建KNN分类器实例
knn = KNeighborsClassifier(n_neighbors=K, weights='distance')
# 使用数据集训练模型
knn.fit(dataset_X, dataset_y)
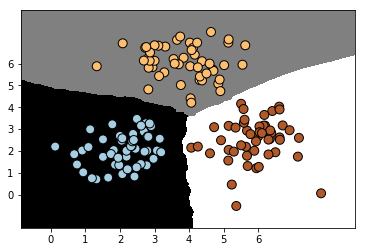
上述代码展示了如何利用给定的数据集训练KNN模型。接下来,我们可以通过绘制分类模型在训练数据集上的决策边界来评估模型的性能。从下图可以看出,KNN分类器能够有效地将数据集中的不同类别区分开来:
2.2 预测新样本
使用训练好的KNN模型进行新样本的预测也非常简单。以下是预测新样本的代码示例:
# 新样本数据
new_sample = np.array([[4.5, 3.6]])
# 预测新样本的类别
predicted = knn.predict(new_sample)[0]
print("KNN Predicted: {}".format(predicted))
预测结果显示,新样本被归类为第二类。为了更好地理解这一分类结果,我们可以将新样本及其最近的K个邻居在图中标出。为此,我们对绘图函数进行了调整,以显示新样本的具体位置及其周围的K个邻居。调整后的绘图函数如下所示:
# 定义绘图函数
import matplotlib.pyplot as plt
import numpy as np
def plot_classifier(knn_classifier, X, y, new_sample, K):
x_min, x_max = X[:, 0].min() - 1.0, X[:, 0].max() + 1.0
y_min, y_max = X[:, 1].min() - 1.0, X[:, 1].max() + 1.0
step_size = 0.01
x_values, y_values = np.meshgrid(np.arange(x_min, x_max, step_size),
np.arange(y_min, y_max, step_size))
mesh_output = knn_classifier.predict(np.c_[x_values.ravel(), y_values.ravel()])
mesh_output = mesh_output.reshape(x_values.shape)
plt.figure()
plt.pcolormesh(x_values, y_values, mesh_output, cmap=plt.cm.gray)
plt.scatter(X[:, 0], X[:, 1], c=y, s=80, edgecolors='black', linewidth=1, cmap=plt.cm.Paired)
plt.scatter(new_sample[:, 0], new_sample[:, 1], marker='*', color='red')
dist, indices = knn_classifier.kneighbors(new_sample)
plt.scatter(X[indices][0][:, 0], X[indices][0][:, 1], marker='x', s=80, color='r')
plt.xlim(x_values.min(), x_values.max())
plt.ylim(y_values.min(), y_values.max())
plt.xticks(np.arange(int(X[:, 0].min()), int(X[:, 0].max()), 1.0))
plt.yticks(np.arange(int(X[:, 1].min()), int(X[:, 1].max()), 1.0))
plt.show()
执行上述绘图函数后,得到的结果图如下所示:
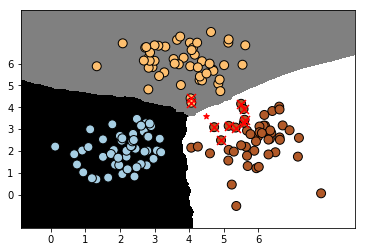
从图中可以看到,红色五角星代表新样本,而红色叉号则表示与新样本最近的K个邻居。大多数邻居属于第二类,因此新样本也被分类为第二类,这与predict函数返回的结果一致。
总结
- 构建和训练KNN分类器非常简便,只需通过scikit-learn库调用相应的函数即可。
- KNN分类器通过计算新数据点与训练集中所有数据点的距离,选择最近的K个数据点,并根据这些数据点的多数类别来确定新数据点的类别。通常推荐K值为奇数,以避免平局情况。
- 选择最优K值是KNN分类器的一个挑战,可以通过交叉验证、网格搜索或随机搜索等方法来实现。
注:本文中涉及的所有代码已上传至我的GitHub仓库,欢迎下载并参考使用。参考资料包括《Python机器学习经典实例》一书,由Prateek Joshi撰写,陶俊杰和陈小莉翻译。








 京公网安备 11010802041100号
京公网安备 11010802041100号