来自DataStax的软件工程师赵洋参与了存储附加索引Storage Attached Index、物化视图Materialized View和Streaming等Cassandra核心功能的开发。
在Cassandra Day China活动演讲中,赵老师就物化视图展开了深入介绍,分享了包括使用物化视图的目的、写入路径、冲突解决以及修复功能等方面的经验。
本文截取了赵老师演讲的部分内容,点击文末“阅读原文”查看完整演讲视频,了解更多技术细节。
大家好,我是赵洋。我是DataStax数据库团队的软件工程师。我主要关注的方向包括索引、Streaming和物化视图。
今天很高兴可以和大家分享Materialized View物化视图的设计和实现。我会主要讨论为什么要用物化视图、物化视图的更新、一致性以及使用物化视图的注意事项。
我们都知道,Cassandra是一种非关系型数据库,即NoSQL数据库。它与关系型数据库不同,所以我们不能用关系型数据库的方式来建表。
在Cassandra数据库中如果建表不合理,很可能导致表的性能下降,甚至失去伸缩性。
所以我们在Cassandra数据库中一般使用denormalization(反范式)的方式建模。也就是说,我们会根据我们的读请求来建表,即使是在不同的表之间会导致数据冗余(duplication)。
但是这种解决方案存在一个问题:当我们需要更改用户信息的时候,我们需要维护多个表。
其实这样的情况下,用户已经在客户端实现了类似于物化视图的功能。既然如此,我们完全可以把这种功能在数据库中实现,从而提高性能和一致性。
简单来说,物化视图就是把原本的数据根据新的分区键重新分到不同的表,然后由服务端(server)维护视图的更新。故此,物化视图有另外一个名字,叫做global index(全局索引)。
对于客户端(client)来说,物化视图就像是一个只可以读的表。这个表的数据插入是根据基表的更新来维护的。
物化视图是可以保证集群的伸缩性以及读请求的低延迟。因为不管集群有多少节点,协调者只需联系固定数量的副本来满足读请求。
Cassandra物化视图的设计中,最重要的特点就是基表跟物化视图的最终一致性。
对于一般的表,它的冲突解决方案非常简单,即比较插入的时间戳,最新的数据就会胜出(last-write-win)。
一般来说,冲突解决会发生在两个地方。一是当本地节点有compaction和本地读时,二是当协调者有客户端读时要联系不同节点并把最新数据返回给客户端。
所以Cassandra的冲突解决的语义(Semantics)就是:只要数据里面有任意一个字段存活,不被墓碑覆盖,这条数据就能存活。
但是在物化视图中,以上这个冲突解决方案就会变得复杂。
我们先来讲一下物化视图的种类以及其物理结构。
一般来说有两种物化视图,第一种就是把基表中的非主键字段变成了物化视图中的主键;另外一种是主键字段不变,但是字段可能变换顺序且部分非主键的字段不在物化视图里面。
对于上面提到的第一种物化视图来说,它的语义就是:只要变主键的字段在基表存活,视图数据就存在。如果变主键的字段在基表中不存在或被墓碑覆盖,那么视图数据就不存在。因为该字段是主键的一部分,没有主键就没有数据。
对于上面提到的第二种物化视图来说,它的语义就是:只要有基表数据存在,视图数据就存在。
但是这造成了一些问题:现有的物化视图的物理结构并不支持这样复杂的语义。所以Cassandra中一共有过三种不同的解决方案,具体请参考Cassandra-11500这个ticket。
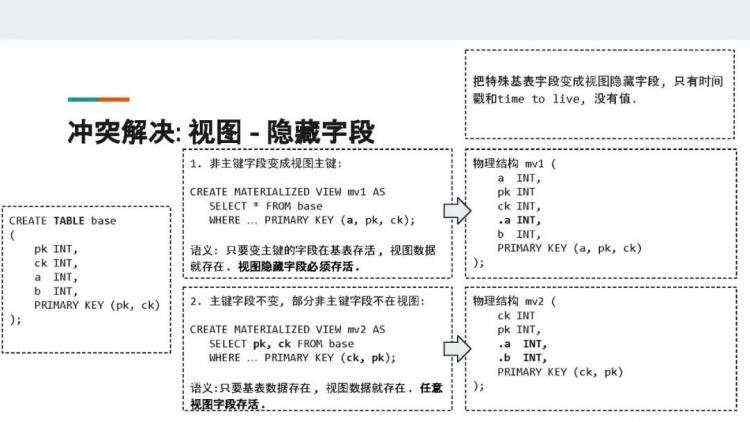
今天我想和大家重点分享的一个比较通用的方案,叫做隐藏字段Hidden Columns。我们打算把这个机制开源到Cassandra新的版本里面。
这个方案的原理很简单,就是把所有物化视图需要的时间戳信息从基表中存储到不同的隐藏字段里面。注意,这些特殊字段只包含时间戳和TTL(time to live),并不包含任何值。这样可以减少储存引擎的损耗。
相应地,物化视图的物理结构也有所改变。
对于前面提到的第一种物化视图来说,它的物理结构中出现了一个对应字段a的隐藏字段.a,来承载原本a字段的时间戳信息。因为字段a已经变成视图主键的一部分,所以它是没有单独的时间戳信息的。
对于这种物化视图来说,它解决冲突的语义是:变主键的字段在基表存活,且视图隐藏字段必须存活,视图数据就存在。如果隐藏字段被墓碑覆盖或因为time to live而过期,视图数据会被认为已经死亡,客户端不可以再读取。
对于前面提到的第二种物化视图来说,我们在其中添加了基表中未被选择的字段a和b对应的隐藏字段.a和.b。
对于这种物化视图来说,它解决冲突的语义是:基表数据存在,且任意视图字段存活,视图数据就存在。即.a, .b, ck, pk中的任意一个没有被墓碑覆盖,物化视图都可以返回活的数据。不过隐藏字段是不会返回给客户端的,因为它没有值,只有时间戳。
Repair的目的很简单——在Cassandra中,一般为了高可用,我们会使用3副本,读写使用Quorum。这种情况下,某些数据很有可能只存在两个节点。所以为了保证数据的一致性,我们需要定期运行repair。
在Repair的过程中,两个存有副本的节点会比较数据的哈希值,如果不一致,节点就会互相stream不同的SSTable。
但是在有物化视图的情况下,基表节点的不一致往往也意味着视图的不一致。所以我们需要把收到的SSTable的数据转化为基表的更新,然后通过物化视图的写路径来更新基表和视图。
不难想到,这里会出现锁、读后写和batchlog,并且也会和客户端的并发更新来竞争锁。所以Repair的开销是非常大的。
接下来我们来看看Incremental repair增量修复基表。增量修复的概念比较简单,即标记已经修复的SSTable,在增量修复时就可以跳过这些SSTable。
在没有物化视图的情况下,已经修复的SSTable直接并入本地节点,放入已经修复的组里面,在之后的增量修复中不会再被增量修复。
但是在有物化视图的情况下,我们需要把增量修复转换成数据更新并通过写路径来更新基表和视图,之后把基表数据插入到memtable。
可是新插入基表memtable的数据又会重新变成未修复数据,在下一次修复时,同样的数据又会被传送回去。
所以在有物化视图的基表上面不推荐使用增量修复。
本文内容版权归DataStax所有
未经书面允许禁止转载
DataStax在中国
技术资讯 | 行业动态 | 活动信息
阅读这篇文章有收获?
请通过点赞、分享和在看告诉我们








 京公网安备 11010802041100号
京公网安备 11010802041100号