如果存量数据来源于其它数据源,可以使用批量导入功能,快速将存量数据导成 Hoodie 表格式。
原理:
批量导入省去了 avro 的序列化以及数据的 merge 过程,后续不会再有去重操作, 数据的唯一性需要自己来保证。
bulk_insert 需要在 Batch Execution Mode 下执行更高效, Batch 模式默认会按照 partition path 排序输入消息再写入 Hoodie, 避免 file handle 频繁切换导致性能下降。
set execution.runtime-mode = batch;
set execution.checkpointing.interval = 0;
write.tasks 指定, 并发的数量会影响到小文件的数量,理论上, bulk_insert write task的并发数就是划分的 bucket 数, 当然每个 bucket 在写到 文件大小 上限(parquet 120 MB) 的时候会 rollover 到新的句柄,所以最后: 写文件数量 >= bulk_insert write task数。建表:
CREATE TABLE `mysql_cdc` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
写存储过程批量插入数据:
DELIMITER //
CREATE PROCEDURE p5()
BEGIN
declare l_n1 int default 1;
while l_n1 <&#61; 10000000 DO
insert into mysql_cdc (id,name) values (l_n1,concat(&#39;test&#39;,l_n1));
set l_n1 &#61; l_n1 &#43; 1;
end while;
END;
//
DELIMITER ;
三. 案例1&#xff1a;COW表导入(写checkpoint&#xff0c;并行度:1)
启动yarn session
内存尽量多指定&#xff0c;不然会包 OOM的错误
$FLINK_HOME/bin/yarn-session.sh -jm 8192 -tm 8192 -d 2>&1 &
/home/flink-1.14.5/bin/sql-client.sh embedded -s yarn-session
Flink SQL操作:
set execution.checkpointing.interval&#61;10sec;
CREATE TABLE flink_mysql_cdc8 (
id BIGINT NOT NULL PRIMARY KEY NOT ENFORCED,
name varchar(100)
) WITH (
&#39;connector&#39; &#61; &#39;mysql-cdc&#39;,
&#39;hostname&#39; &#61; &#39;hp8&#39;,
&#39;port&#39; &#61; &#39;3306&#39;,
&#39;username&#39; &#61; &#39;root&#39;,
&#39;password&#39; &#61; &#39;abc123&#39;,
&#39;database-name&#39; &#61; &#39;test&#39;,
&#39;table-name&#39; &#61; &#39;mysql_cdc&#39;,
&#39;server-id&#39; &#61; &#39;5409-5415&#39;,
&#39;scan.incremental.snapshot.enabled&#39;&#61;&#39;true&#39;
);
set sql-client.execution.result-mode&#61;tableau;
select count(*) from flink_mysql_cdc8;
CREATE TABLE flink_hudi_mysql_cdc8(
id BIGINT NOT NULL PRIMARY KEY NOT ENFORCED,
name varchar(100)
) WITH (
&#39;connector&#39; &#61; &#39;hudi&#39;,
&#39;path&#39; &#61; &#39;hdfs://hp5:8020/tmp/hudi/flink_hudi_mysql_cdc8&#39;,
&#39;table.type&#39; &#61; &#39;COPY_ON_WRITE&#39;,
&#39;changelog.enabled&#39; &#61; &#39;true&#39;,
&#39;hoodie.datasource.write.recordkey.field&#39; &#61; &#39;id&#39;,
&#39;write.precombine.field&#39; &#61; &#39;name&#39;,
&#39;compaction.async.enabled&#39; &#61; &#39;false&#39;
);
insert into flink_hudi_mysql_cdc8 select * from flink_mysql_cdc8;
select count(*) from flink_hudi_mysql_cdc8 ;
因为设置了10秒钟一次checkpoint&#xff0c;且并行度为1&#xff0c;而write.tasks默认为4&#xff0c;所以很慢&#xff0c;预估10小时以上。
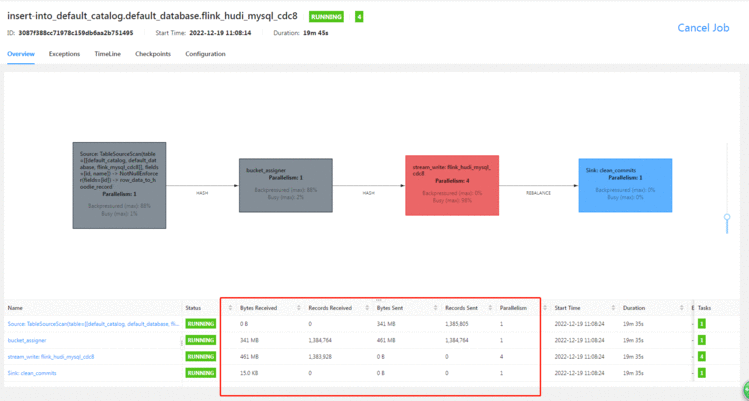
启动yarn session
内存尽量多指定&#xff0c;不然会包 OOM的错误
/home/flink-1.14.5/bin/yarn-session.sh -jm 8192 -tm 8192 -d 2>&1 &
/home/flink-1.14.5/bin/sql-client.sh embedded -s yarn-session
代码:
CREATE TABLE flink_mysql_cdc10 (
id BIGINT NOT NULL PRIMARY KEY NOT ENFORCED,
name varchar(100)
) WITH (
&#39;connector&#39; &#61; &#39;mysql-cdc&#39;,
&#39;hostname&#39; &#61; &#39;hp8&#39;,
&#39;port&#39; &#61; &#39;3306&#39;,
&#39;username&#39; &#61; &#39;root&#39;,
&#39;password&#39; &#61; &#39;abc123&#39;,
&#39;database-name&#39; &#61; &#39;test&#39;,
&#39;table-name&#39; &#61; &#39;mysql_cdc&#39;,
&#39;server-id&#39; &#61; &#39;5409-5415&#39;,
&#39;scan.incremental.snapshot.enabled&#39;&#61;&#39;true&#39;
);
select count(*) from flink_mysql_cdc10;
CREATE TABLE flink_hudi_mysql_cdc10(
id BIGINT NOT NULL PRIMARY KEY NOT ENFORCED,
name varchar(100)
) WITH (
&#39;connector&#39; &#61; &#39;hudi&#39;,
&#39;path&#39; &#61; &#39;hdfs://hp5:8020/tmp/hudi/flink_hudi_mysql_cdc10&#39;,
&#39;table.type&#39; &#61; &#39;COPY_ON_WRITE&#39;,
&#39;changelog.enabled&#39; &#61; &#39;true&#39;,
&#39;hoodie.datasource.write.recordkey.field&#39; &#61; &#39;id&#39;,
&#39;write.precombine.field&#39; &#61; &#39;name&#39;,
&#39;compaction.async.enabled&#39; &#61; &#39;false&#39;
);
set &#39;parallelism.default&#39; &#61; &#39;4&#39;;
insert into flink_hudi_mysql_cdc10 select * from flink_mysql_cdc10;
select count(*) from flink_hudi_mysql_cdc9 ;
3分钟就跑了500W(一半左右的数据)&#xff0c;性能较之前提升了数十倍
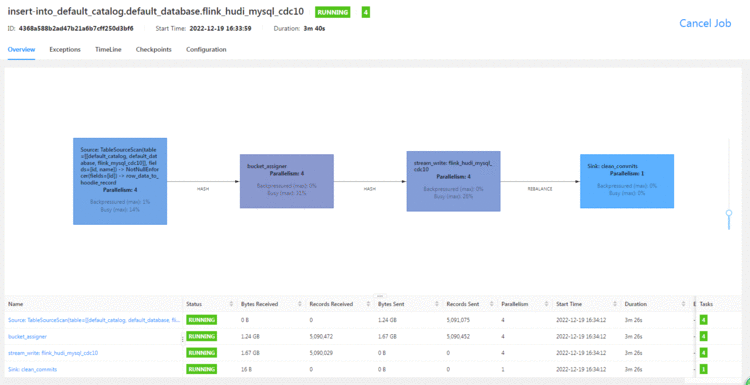
查询报错:

HDFS上的文件也较小:
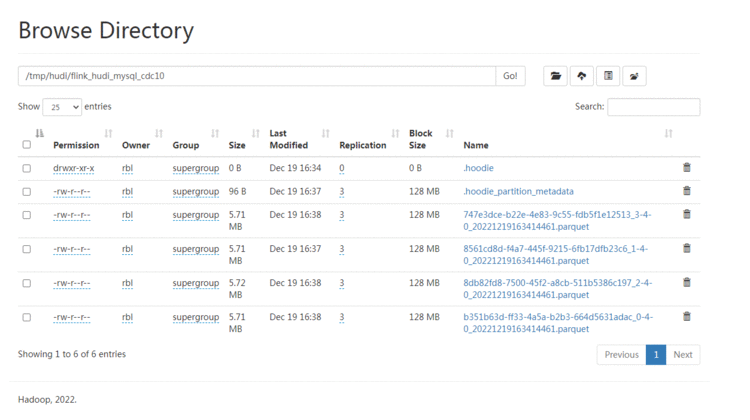
连接Spark SQL
# Spark 3.3
spark-sql --packages org.apache.hudi:hudi-spark3.3-bundle_2.12:0.12.0 \
--conf &#39;spark.serializer&#61;org.apache.spark.serializer.KryoSerializer&#39; \
--conf &#39;spark.sql.extensions&#61;org.apache.spark.sql.hudi.HoodieSparkSessionExtension&#39; \
--conf &#39;spark.sql.catalog.spark_catalog&#61;org.apache.spark.sql.hudi.catalog.HoodieCatalog&#39;
创建Hudi表:
建表的语法存在差异&#xff0c;需要进行调整&#xff0c;有的字段类型都不对应
CREATE TABLE flink_hudi_mysql_cdc10_spark(
id int,
name varchar(100)
)
using hudi
location &#39;hdfs://hp5:8020/tmp/hudi/flink_hudi_mysql_cdc10&#39;;
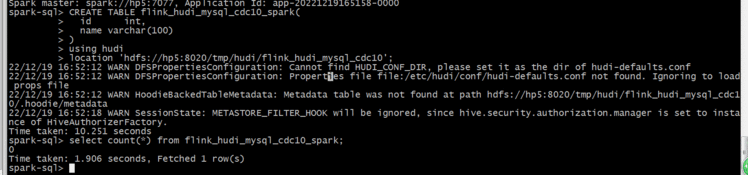
查询数据:
select count(*) from flink_hudi_mysql_cdc10_spark;
居然是0&#xff0c;看来不checkpoint还是不行
本来想测试batch的&#xff0c;经测试&#xff0c;会报错:
org.apache.flink.table.api.ValidationException: Querying an unbounded table &#39;default_catalog.default_database.flink_mysql_cdc11&#39; in batch mode is not allowed. The table source is unbounded.
checkpoint也不能设置为0
Flink SQL> set execution.checkpointing.interval &#61; 0;
[ERROR] Could not execute SQL statement. Reason:
java.lang.IllegalArgumentException: Checkpoint interval must be larger than or equal to 10 ms
启动yarn session
内存尽量多指定&#xff0c;不然会包 OOM的错误
/home/flink-1.14.5/bin/yarn-session.sh -jm 8192 -tm 8192 -d 2>&1 &
/home/flink-1.14.5/bin/sql-client.sh embedded -s yarn-session
set &#39;parallelism.default&#39; &#61; &#39;4&#39;;
set execution.checkpointing.interval&#61;600sec;
CREATE TABLE flink_mysql_cdc13 (
id BIGINT NOT NULL PRIMARY KEY NOT ENFORCED,
name varchar(100)
) WITH (
&#39;connector&#39; &#61; &#39;mysql-cdc&#39;,
&#39;hostname&#39; &#61; &#39;hp8&#39;,
&#39;port&#39; &#61; &#39;3306&#39;,
&#39;username&#39; &#61; &#39;root&#39;,
&#39;password&#39; &#61; &#39;abc123&#39;,
&#39;database-name&#39; &#61; &#39;test&#39;,
&#39;table-name&#39; &#61; &#39;mysql_cdc&#39;,
&#39;server-id&#39; &#61; &#39;5409-5415&#39;,
&#39;scan.incremental.snapshot.enabled&#39;&#61;&#39;true&#39;
);
CREATE TABLE flink_hudi_mysql_cdc13(
id BIGINT NOT NULL PRIMARY KEY NOT ENFORCED,
name varchar(100)
) WITH (
&#39;connector&#39; &#61; &#39;hudi&#39;,
&#39;path&#39; &#61; &#39;hdfs://hp5:8020/tmp/hudi/flink_hudi_mysql_cdc13&#39;,
&#39;table.type&#39; &#61; &#39;COPY_ON_WRITE&#39;,
&#39;changelog.enabled&#39; &#61; &#39;true&#39;,
&#39;hoodie.datasource.write.recordkey.field&#39; &#61; &#39;id&#39;,
&#39;write.precombine.field&#39; &#61; &#39;name&#39;,
&#39;compaction.async.enabled&#39; &#61; &#39;false&#39;
);
insert into flink_hudi_mysql_cdc13 select * from flink_mysql_cdc13;
select count(*) from flink_hudi_mysql_cdc13 ;
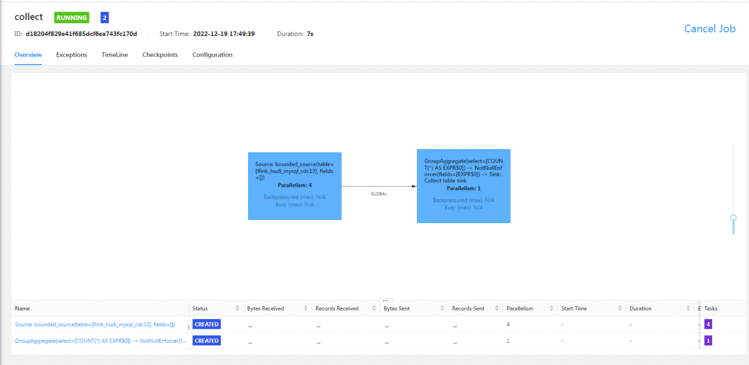
Flink web查看数据更新:
把checkpoint设置为10分钟&#xff0c;并行度设置为4&#xff0c;确实快了不少
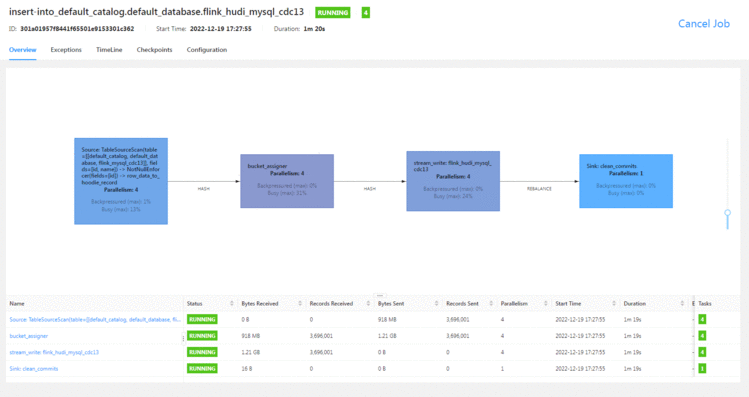
7分钟左右写完1kw的数据&#xff08;页面显示有时候有问题&#xff0c;我提前结束了job&#xff0c;结果发现数据少了&#xff09;
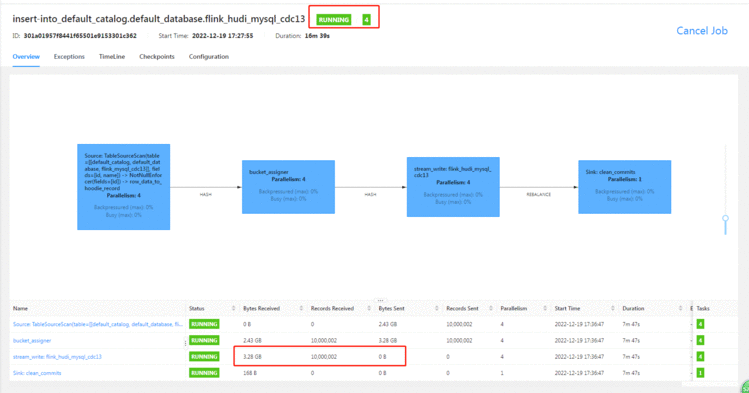
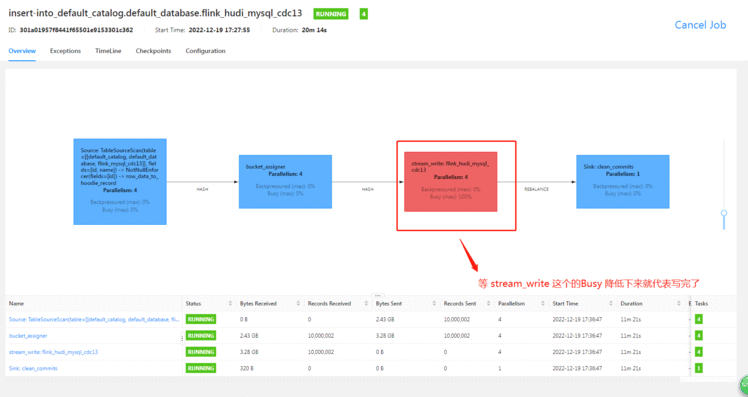
上面显示已经同步过来了&#xff0c;但是其实还没写完&#xff0c;还需要等checkpoint完成&#xff0c;不然的话&#xff0c;数据会丢。
因为Flink一切皆流&#xff0c;所以后续的 对MySQL表的增删改依旧会同步过来&#xff0c;此处我新增了2条&#xff0c;看数据已经过来了。
checkpoint也做了
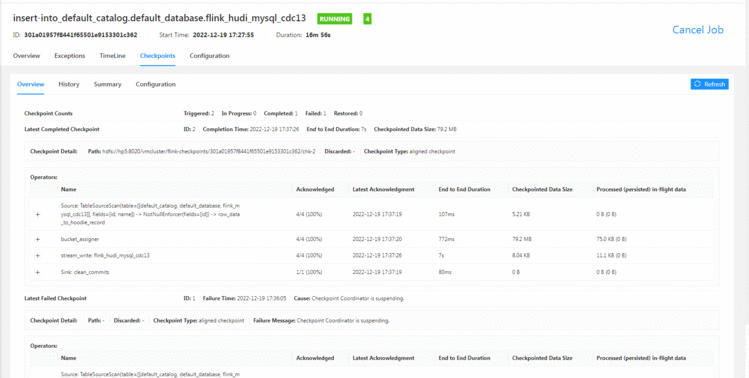
查询数据:
可能是资源影响吧&#xff0c;我查询数据的时候一直处于等待状态。
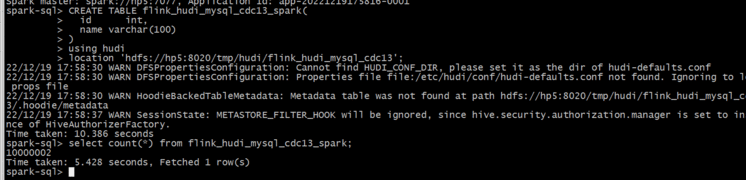
连接Spark SQL
# Spark 3.3
spark-sql --packages org.apache.hudi:hudi-spark3.3-bundle_2.12:0.12.0 \
--conf &#39;spark.serializer&#61;org.apache.spark.serializer.KryoSerializer&#39; \
--conf &#39;spark.sql.extensions&#61;org.apache.spark.sql.hudi.HoodieSparkSessionExtension&#39; \
--conf &#39;spark.sql.catalog.spark_catalog&#61;org.apache.spark.sql.hudi.catalog.HoodieCatalog&#39;
创建Hudi表:
建表的语法存在差异&#xff0c;需要进行调整&#xff0c;有的字段类型都不对应
CREATE TABLE flink_hudi_mysql_cdc13_spark(
id int,
name varchar(100)
)
using hudi
location &#39;hdfs://hp5:8020/tmp/hudi/flink_hudi_mysql_cdc13&#39;;
查询数据:
select count(*) from flink_hudi_mysql_cdc13_spark;
数据没问题了
对于MySQL这种数据源而言&#xff0c;MOR表更适合&#xff0c;全量导入后再接增量。
启动yarn session
内存尽量多指定&#xff0c;不然会包 OOM的错误
/home/flink-1.14.5/bin/yarn-session.sh -jm 8192 -tm 8192 -d 2>&1 &
/home/flink-1.14.5/bin/sql-client.sh embedded -s yarn-session
还是不能使用batch:
[ERROR] Could not execute SQL statement. Reason:
org.apache.flink.table.api.ValidationException: Querying an unbounded table &#39;default_catalog.default_database.flink_mysql_cdc14&#39; in batch mode is not allowed. The table source is unbounded.
set &#39;parallelism.default&#39; &#61; &#39;4&#39;;
set execution.checkpointing.interval&#61;100sec;
CREATE TABLE flink_mysql_cdc16 (
id BIGINT NOT NULL PRIMARY KEY NOT ENFORCED,
name varchar(100)
) WITH (
&#39;connector&#39; &#61; &#39;mysql-cdc&#39;,
&#39;hostname&#39; &#61; &#39;hp8&#39;,
&#39;port&#39; &#61; &#39;3306&#39;,
&#39;username&#39; &#61; &#39;root&#39;,
&#39;password&#39; &#61; &#39;abc123&#39;,
&#39;database-name&#39; &#61; &#39;test&#39;,
&#39;table-name&#39; &#61; &#39;mysql_cdc&#39;,
&#39;server-id&#39; &#61; &#39;5409-5415&#39;,
&#39;scan.incremental.snapshot.enabled&#39;&#61;&#39;true&#39;
);
CREATE TABLE flink_hudi_mysql_cdc16(
id BIGINT NOT NULL PRIMARY KEY NOT ENFORCED,
name varchar(100)
) WITH (
&#39;connector&#39; &#61; &#39;hudi&#39;,
&#39;path&#39; &#61; &#39;hdfs://hp5:8020/tmp/hudi/flink_hudi_mysql_cdc16&#39;,
&#39;table.type&#39; &#61; &#39;MERGE_ON_READ&#39;,
&#39;changelog.enabled&#39; &#61; &#39;true&#39;,
&#39;hoodie.datasource.write.recordkey.field&#39; &#61; &#39;id&#39;,
&#39;write.precombine.field&#39; &#61; &#39;name&#39;,
&#39;compaction.async.enabled&#39; &#61; &#39;false&#39;
);
insert into flink_hudi_mysql_cdc16 select * from flink_mysql_cdc16;
select count(*) from flink_hudi_mysql_cdc16 ;
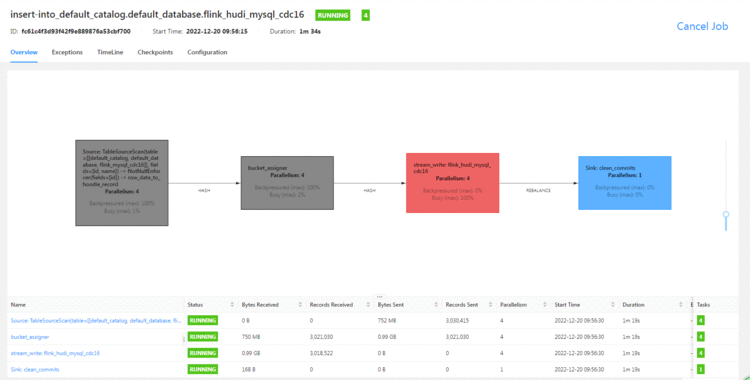
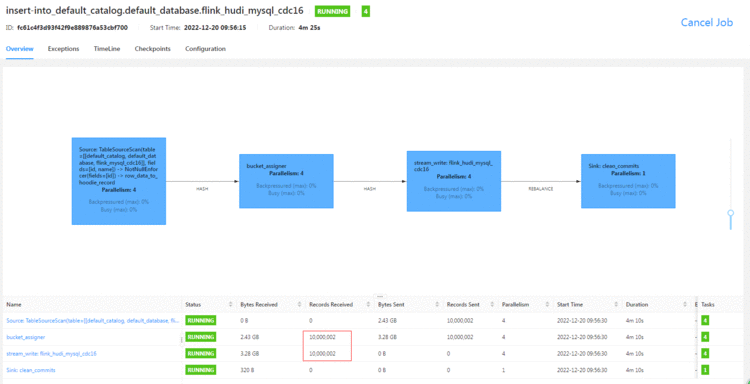
Flink web
没想到&#xff0c;MOR的表速度也挺快的&#xff0c;我最开始用的是小内存&#xff0c;并行度为1&#xff0c;然后一直失败和OOM。
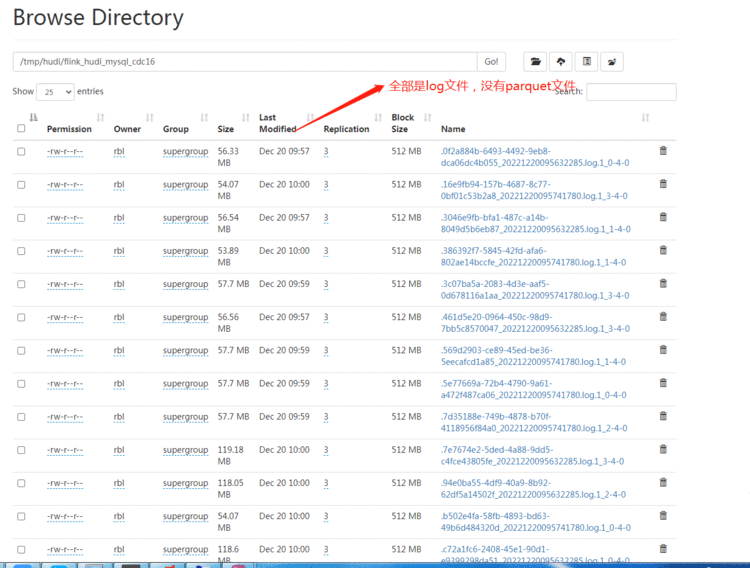
HDFS:
全部是log文件&#xff0c;没有parquet文件
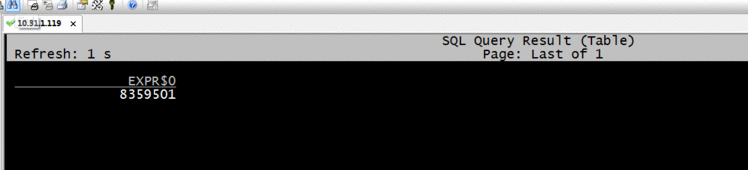
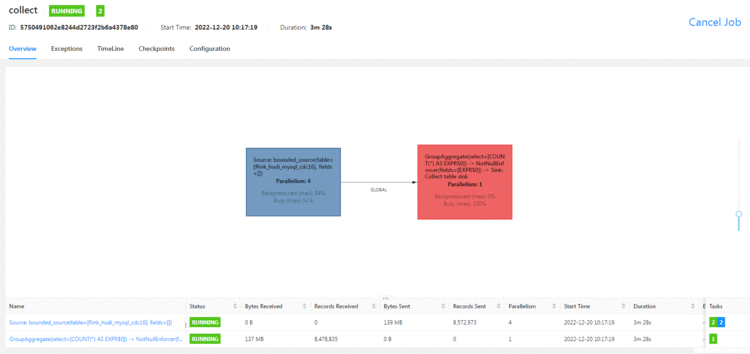
Flink SQL查询数据
select count(*) from flink_hudi_mysql_cdc16;
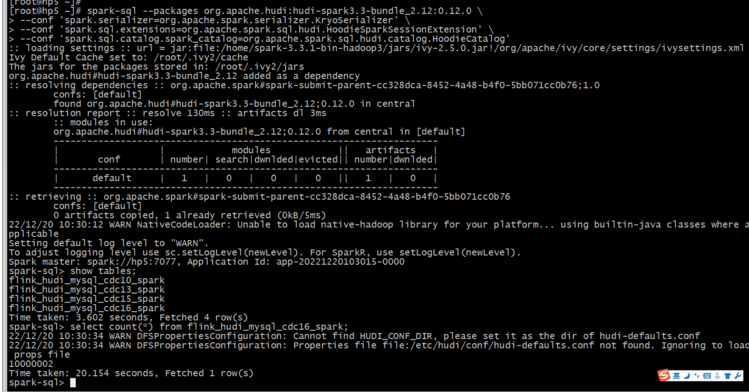
Spark SQL查询:
# Spark 3.3
spark-sql --packages org.apache.hudi:hudi-spark3.3-bundle_2.12:0.12.0 \
--conf &#39;spark.serializer&#61;org.apache.spark.serializer.KryoSerializer&#39; \
--conf &#39;spark.sql.extensions&#61;org.apache.spark.sql.hudi.HoodieSparkSessionExtension&#39; \
--conf &#39;spark.sql.catalog.spark_catalog&#61;org.apache.spark.sql.hudi.catalog.HoodieCatalog&#39;
CREATE TABLE flink_hudi_mysql_cdc16_spark(
id int,
name varchar(100)
)
using hudi
location &#39;hdfs://hp5:8020/tmp/hudi/flink_hudi_mysql_cdc16&#39;;
select count(*) from flink_hudi_mysql_cdc16_spark;
Hive SQL查询:
cd /home/hudi-0.12.0/hudi-sync/hudi-hive-sync
./run_sync_tool.sh --jdbc-url jdbc:hive2:\/\/hp5:10000 --base-path hdfs://hp5:8020/tmp/hudi/flink_hudi_mysql_cdc16 --database test --table flink_hudi_mysql_cdc16
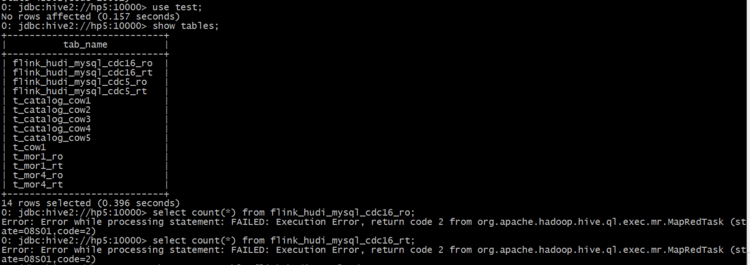
select count(*) from test.flink_hudi_mysql_cdc16_ro;
直接报错





 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 