作者:wuyanting67412 | 来源:互联网 | 2023-07-07 16:59
Hive表数据的导入从本地导入loaddatalocalinpath‘local_path’intotabletable_name;hive4.pnghive5.png从hdfs导
Hive表数据的导入
load data local inpath ‘local_path’ into table table_name;
 hive4.png
hive4.png
 hive5.png
hive5.png
load data inpath ‘hdfs_path’ into table table_name;
 hive6.png
hive6.png
load data local inpath ‘local_inpath’ overwrite into table table_name;
load data inpath ‘hdfs_inpath’ overwrite into table table_name;
创建表时通过子查询加载(会自动创建表结构)
 hive7.png
hive7.png
- insert加载子查询到已创建好的表中(手动创建表结构)
hive (test_db)> create table emp3 like emp;
hive (test_db)> insert into table emp3 select * from emp;
- 在创建表时location 指定文件位置(外部表)
create table … location ‘hdfs_location’;
load data [local] inpath ‘paht’ into table table_name partition(partioncol1=val1…);
Hive查询结果和表数据的导出
排序
- order by:order by子句对一列按升序(asc)或降序(desc)排列。但是只能限制于一个reduce。
hive (test_db)> select sal from emp order by sal desc;
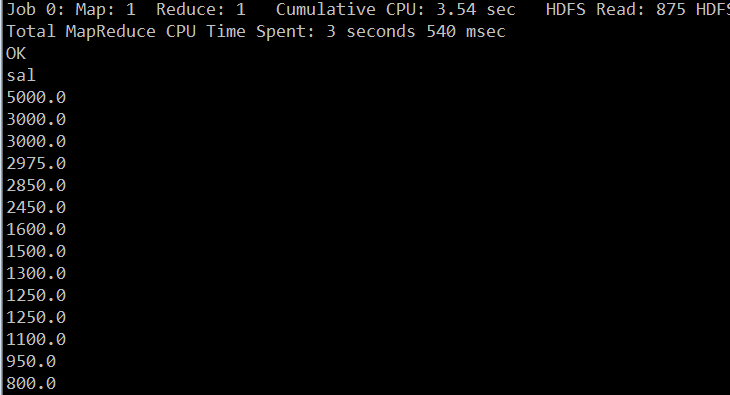 hive12.png
hive12.png
- sort by:对每个reduce中的数据进行单独排序,但是全局不一定有序。
hive (test_db)> set mapreduce.job.reduces=3;
hive (test_db)> select sal,deptno from emp sort by sal desc;
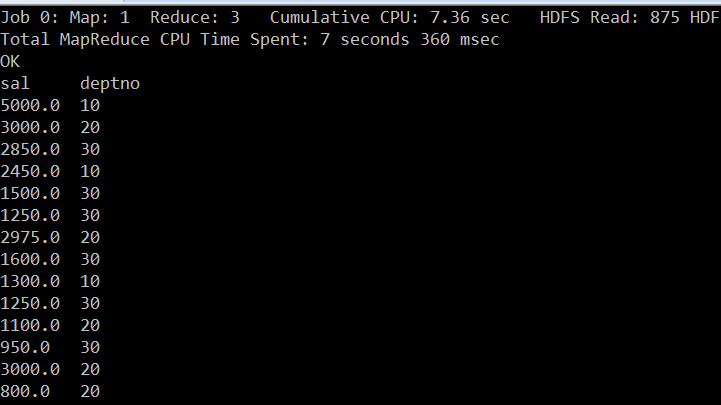 hive13.png
hive13.png
- distribute by:shuffle中的分区默认是按照key值计算hash值然后取余均匀的分发到reducer中。distribute by可以设置map端输出后是按照哪一个字段进行hash取余分区的。
hive (test_db)> select sal,deptno from emp distribute by deptno sort by sal desc;
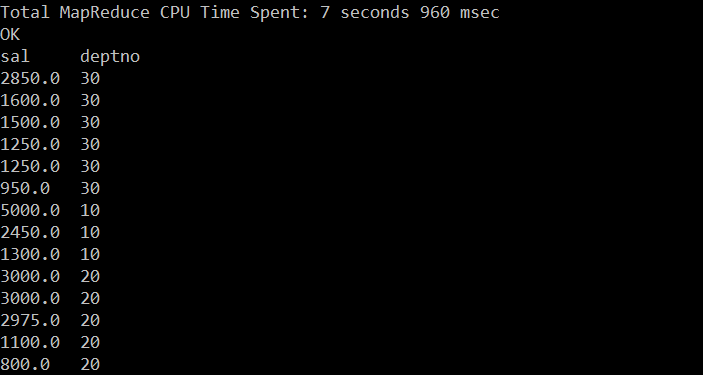 hive14.png
hive14.png
- cluster by:当dstribute by和sort by字段相同时,可以使用cluster by,相当于一种简写方式。
分组
- group by和having group by对一列进行分组,一般与聚合函数结合使用
hive (test_db)> select avg(sal) avg_sal,deptno from emp group by deptno having avg_sal>2000;
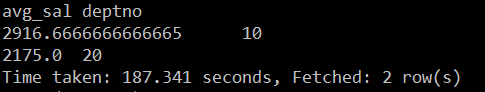 hive15.png
hive15.png
- over(partition by):与group具有同样的分组功能,但是显示方式会不同。
hive (test_db)> select sal,deptno,avg(sal) over(partition by deptno) avg_sal from emp;
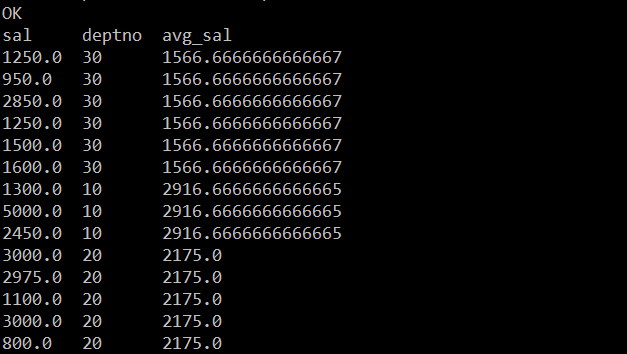 hive16.png
hive16.png
表的join
- 等值join:只有进行连接的两个表中都存在于连接标准相匹配的数据才会保存下来。
hive (test_db)> select e.empno,e.ename,d.deptno from emp e join dept d on e.deptno=d.deptno;
- 左join和右join:left join返回左表中的所有值,加上右表,如果右表对应项没有则用null填充。right join相反
select e.empno,e.ename ,d.deptno ,e.sal from emp e left join dept d on e.deptno=d.deptno;
select e.empno,e.ename ,d.deptno ,e.sal from emp e right join dept d on e.deptno=d.deptno;
 hive9.png
hive9.png hive11.png
hive11.png hive10.png
hive10.png


![基于Linux开源VOIP系统LinPhone[四]](https://img.php1.cn/3cd4a/1eebe/cd5/ed19db63ee478b98.png)

 京公网安备 11010802041100号
京公网安备 11010802041100号