Hive文件格式与压缩 Hive支持的存储数据格式主要有:文本格式(TEXTFILE )、二进制序列化文件(SEQUENCEFILE)、行列式文件(RCFile)、优化的行列式文件(ORC)、PARQUET。其中优化的行列式文件(ORC)、PARQUET以其高效的数据存储和数据处理性能得以在实际的生产环境中大量运用。
注: TEXTFILE和SEQUENCEFILE的存储格式都是基于行式存储的;ORC和PARQUET是基于列式存储的。
1.前置准备 实验环境
1)Oracle Linux 7.4
2)Java1.8.0_144
3)Hadoop2.7.4
4)Hive2.3.3
数据准备
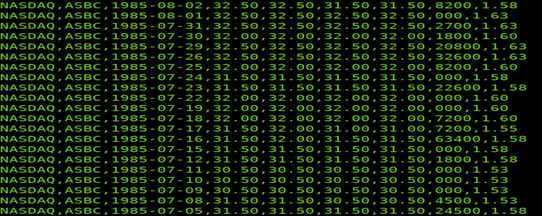
查看股票交易信息的实验数据文件big_stocks.csv内容,共计207万5347行,数据以逗号“,”分隔,依次记录股票交易所编码、股票代码、股票交易日期、股票开盘价、股票开盘价、股票最低价、股票收盘价、股票交易量和股票成交价
2.实验流程 2.1 创建表stocks_txt 默认格式,数据不做压缩,磁盘开销大,数据解析开销大。可结合Gzip、Bzip2使用,但使用Gzip这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
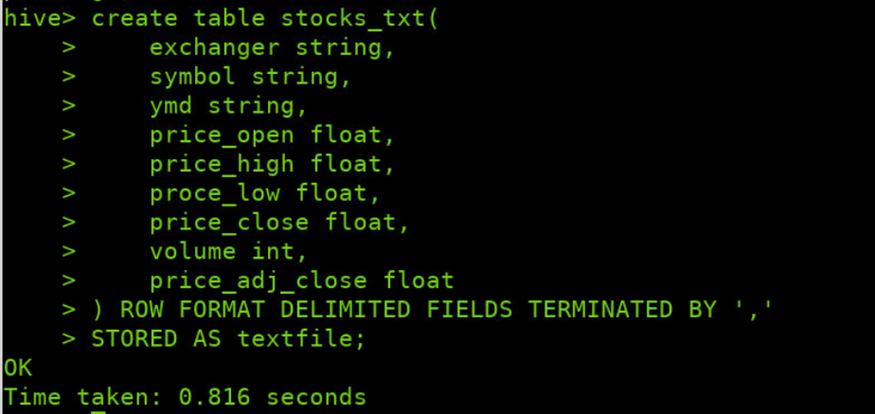
创建表,存储数据格式为TEXTFILE
create table stocks_txt( exchanger string, symbol string, ymd string, price_open float , price_high float , proce_low float , price_close float , volume int , price_adj_close float ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' AS textfile;
加载big_stocks.csv文件内容至表stocks_txt中
LOAD DATA LOCAL INPATH '/root/experiment/datas/hive/big_stocks.csv' OVERWRITE INTO TABLE stocks_txt;
查看数据文件为.csv文本格式
命令端查看
dfs -lsr /data/hive/warehouse/stocks_txt;
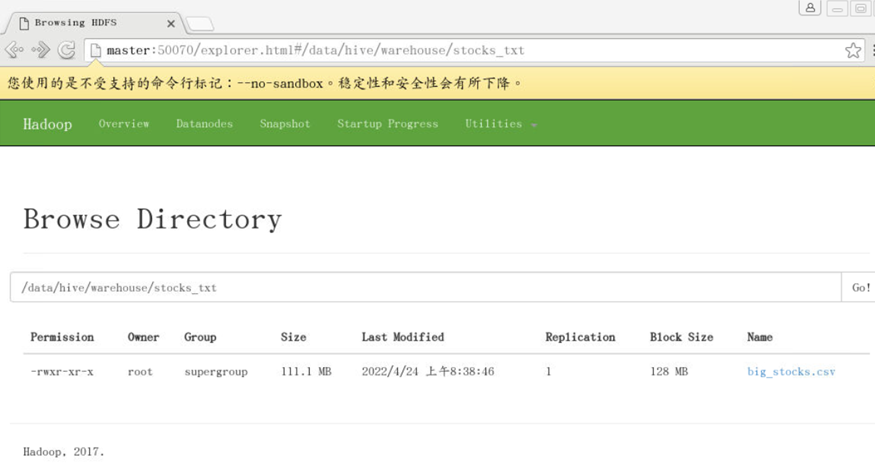
Web端查看
2.2 创建表stocks_orc Orc (Optimized Row Columnar)是Hive 0.11版引入的新的存储格式。ORC存储的文件是一种带有模式描述的行列式存储文件,有别于传统的数据存储文件,它会将数据先按照行组进行切分,一个行组内部包含若干行,每一行再按列进行存储 。例如:每个Orc文件由1个或多个stripe组成,每个stripe250MB大小,这个Stripe实际相当于RowGroup概念。
ORC文件结构由三部分组成:
条带(Stripe) :ORC文件存储数据的地方。文件脚注(File Footer) :包含文件中stripe的列表,每个stripe的行数,以及每个列的数据类型。它还包含了每个列的最小值、最大值、行计数、求和等聚合信息。Postscript :记录整个文件的压缩类型,含有压缩参数和压缩大小相关的信息。
Stripe结构也可以分为三个部分:
Index Data:它保存了所在条带的一些统计信息,以及数据在stripe中的位置索引信息。它是一个轻量级的索引,默认是每隔1W行做一个索引。这里做的索引应该只是记录某行的各字段在Row Data中的offset。
从上面的ORC文件结构可知ORC在每个文件中提供了3个级别的索引:
文件级:这一级的索引信息记录文件中所有stripe的位置信息,以及文件中所存储的每列数据的统计信息。 File Footer Index Data metadata stream
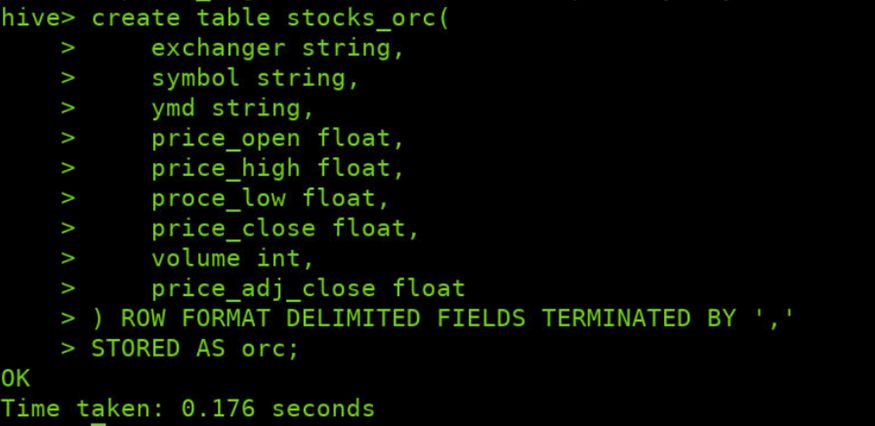
create table stocks_orc( exchanger string, symbol string, ymd string, price_open float , price_high float , proce_low float , price_close float , volume int , price_adj_close float ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' AS orc;
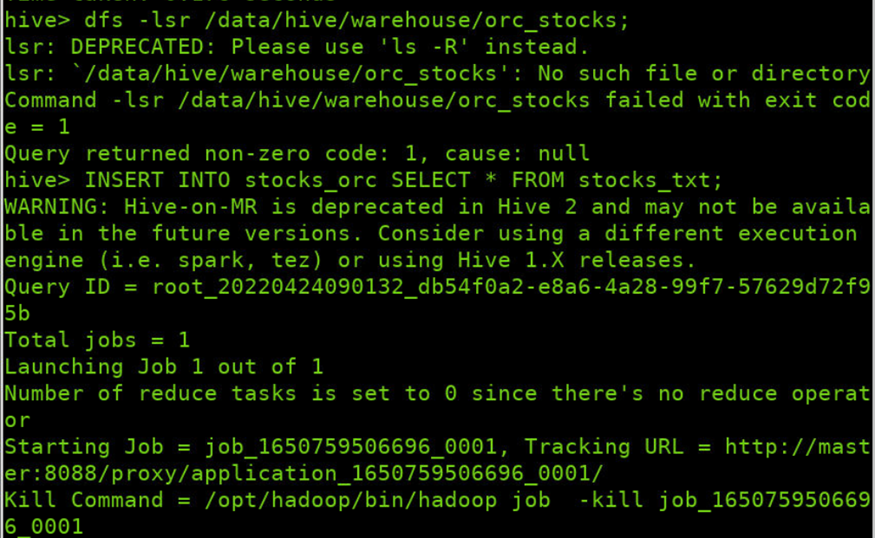
加载big_stocks.csv文件内容至表stocks_orc中
INSERT INTO stocks_orc SELECT * FROM stocks_txt;
2.3 创建表stocks_parquet Parquet是面向分析型业务的列式存储格式,由Twitter和Cloudera合作开发,2015年5月从Apache的孵化器里毕业成为Apache顶级项目。
在一个Parquet类型的Hive表文件中,数据被分成多个行组(Row Group),一个行组包含这个行组对应的区间内的所有列的列块(column chunk)。一个列块负责存储某一列的数据,一个列块由page组成,page是压缩和编码的单元。Row Group是数据读写时的缓存单元。
Parquet文件是以二进制方式存储的,所以是不可以直接读取的,文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的。
通常情况下,在存储Parquet数据的时候会按照Block大小设置行组的大小,由于一般情况下每一个Mapper任务处理数据的最小单位是一个Block,这样可以把每一个行组由一个Mapper任务处理,增大任务执行并行度。
在Parquet中,有三种类型的页:数据页、字典页和索引页 。
数据页用于存储当前行组中该列的值,字典页存储该列值的编码字典,每一个列块中最多包含一个字典页,索引页用来存储当前行组下该列的索引,目前Parquet中还不支持索引页。
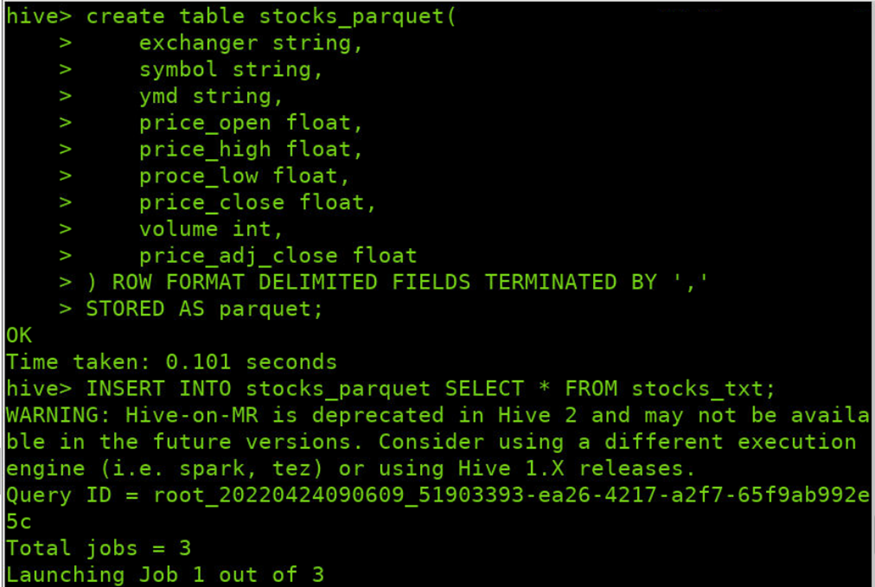
创建存储数据格式为parquet的表stocks_parquet
create table stocks_parquet( exchanger string, symbol string, ymd string, price_open float , price_high float , proce_low float , price_close float , volume int , price_adj_close float ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' AS parquet;
加载big_stocks.csv文件内容至表parquet_stocks中
INSERT INTO stocks_parquet SELECT * FROM stocks_txt;
2.4 创建表stocks_sequence 设置块压缩格式
SET io. seqfile. compression. type = BLOCK;
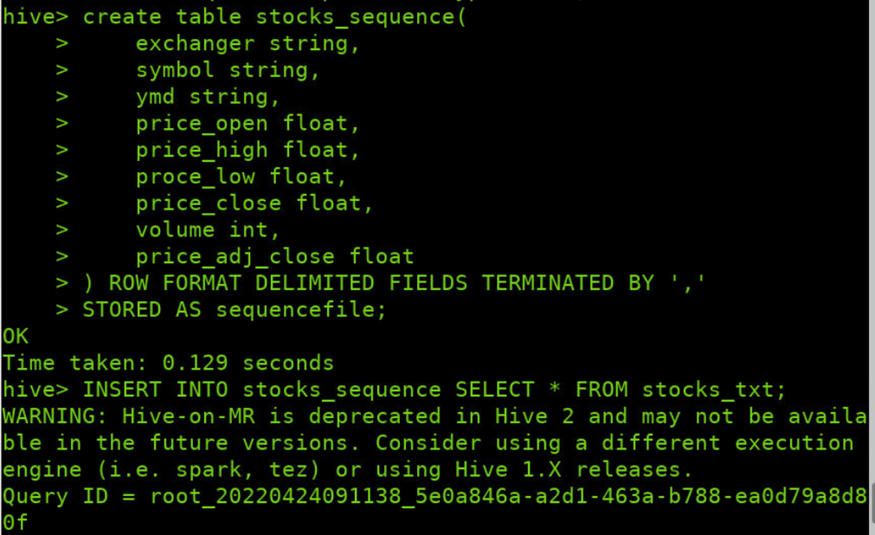
创建存储数据格式为parquet的表stocks_sequence
create table stocks_sequence( exchanger string, symbol string, ymd string, price_open float , price_high float , proce_low float , price_close float , volume int , price_adj_close float ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' AS sequencefile;
加载big_stocks.csv文件内容至表parquet_stocks中
INSERT INTO stocks_sequence SELECT * FROM stocks_txt;
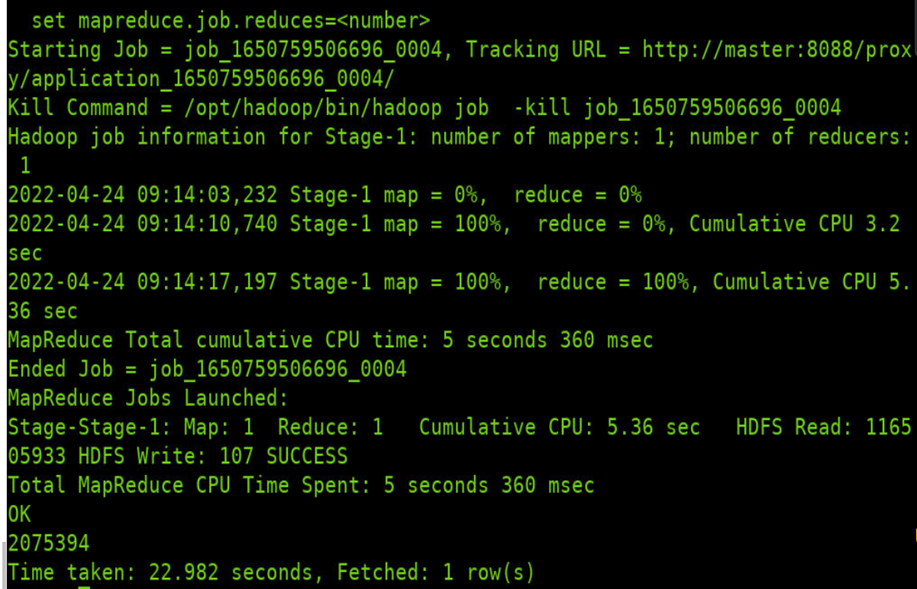
2.5 存储数据格式查询比较 文本格式存储表的统计查询
SELECT count ( * ) FROM stocks_txt;
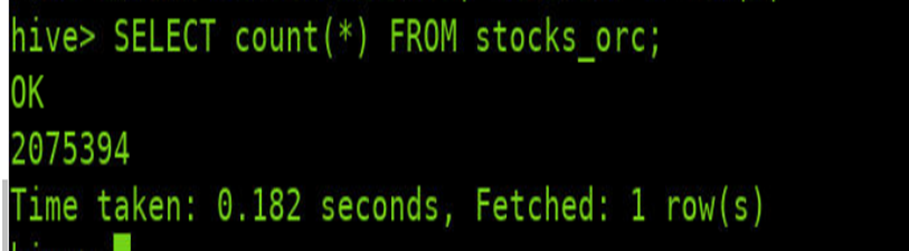
orc存储表的统计查询
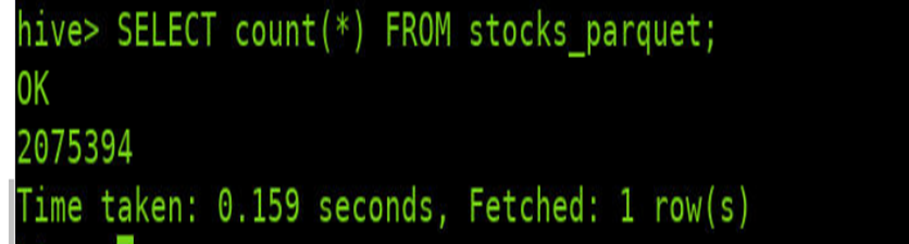
parquet格式存储表的统计查询
sequence格式存储表的统计查询
SELECT count ( * ) FROM stocks_sequence;
3. 实验总结 存储文件的压缩比:
ORC > Sequence >Parquet > textFile
综上所述,涉及到的4个查询经比较可知,在进行文本格式存储表查询时会调用MR任务,在实训开发中,我们应尽可能避免调用MR程序,降低时间成本消耗。
申明:文章仅做记录,涉及侵权内容请联系删除

![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XCu4seIf-1650764585158)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20220424085920900.png)]](https://img0.php1.cn/3cdc5/6d68/339/f2495585d2e0c0b8.png)








 京公网安备 11010802041100号
京公网安备 11010802041100号