作者:到处旅游增加阅历入 | 来源:互联网 | 2023-07-26 08:44
恒源云_卷积神经网络的工作原理-文章来源|恒源云社区原文地址|卷积神经网络的工作原理原文作者|instter视频链接每当深度学习又有什么重大突破时,这些进展十有八九都和卷
文章来源 | 恒源云社区
原文地址 | 卷积神经网络的工作原理
原文作者 | instter
视频链接
每当深度学习又有什么重大突破时,这些进展十有八九都和卷积神经网络(Convolutional Neural Networks,CNN)有关。 CNN 又被称为 CNNs 或 ConvNets,它是目前深度神经网络(deep neural network)领域的发展主力,在图片辨别上甚至可以做到比人类还精准的程度。 如果要说有任何方法能不负大家对深度学习的期望,CNN绝对是首选。
它们特别棒的地方在于它们很容易理解,至少当你将它们分解成它们的基本部分时。我将引导您完成它。有一段视频更详细地讨论了这些图像。如果中间有什么不懂的地方,只要点击图片,就能跳到影片中对应的说明。
X’s and O’s
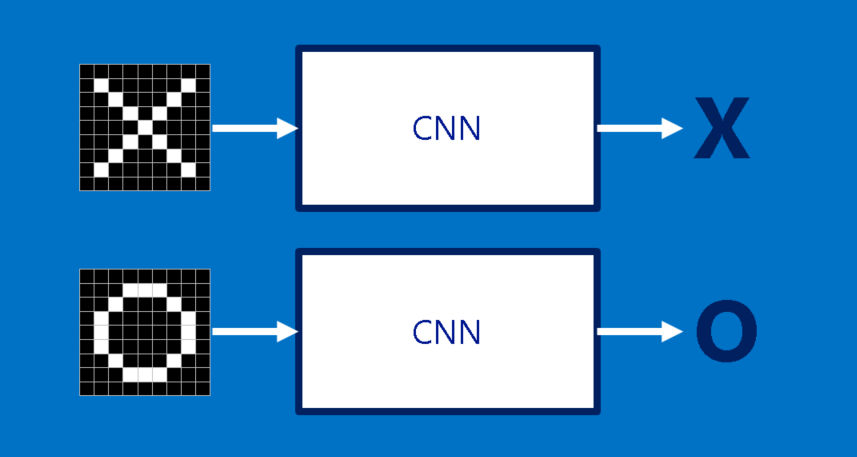
为了说明 CNN,我们可以从一个非常简单的例子开始:辨识图片上的符号是圈还叉。 这个例子一方面已经能很好说明CNN的运作原理,另一方面也够简单,以免我们拘泥于不必要的细节。 在这里CNN最重要的工作,就是每当我们给它一张图,它就会回报上面的符号是圈还是叉。 对它来说结果永远是这两者之一。

首先我们可以想到辨别图片最简单的方法,是直接用圈和叉的图片去比对新的图片,看图上的符号比较像哪个。 但事情没有这么简单,因为电脑在比对这些图片的时候非常刻板。 在电脑看来,这些图片只是一群排成二维矩阵、带有位置编号的像素(就跟棋盘一样)。 在我们的例子里,白色格子(即笔画)的值为 1,黑色格子(即背景)的值为 -1。 所以在比对图片时,如果有任何一个格子的值不相等,电脑就会认为两张图不一样。 理想上,我们希望不管在平移、缩小、旋转或变形等情况下,电脑都能正确判断符号。 这时CNN就派上用场了。
特征
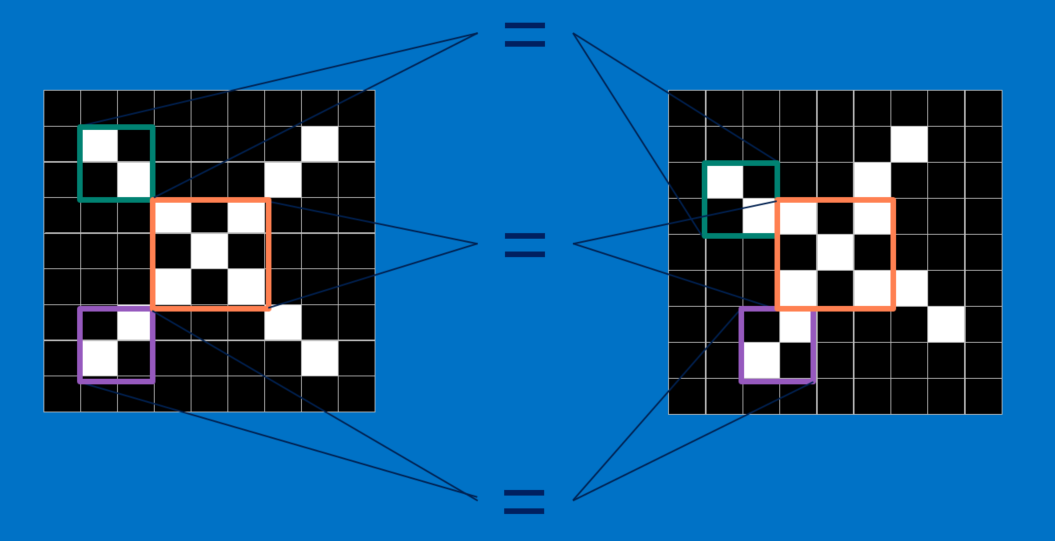
CNN会比较两张图片里的各个局部,这些局部被称为特征(feature)。 比起比较整张图片,在相似的位置上比对大略特征,CNN 能更好地分辨两张图片是否相同。
一张图片里的每个特征都像一张更小的图片,也就是更小的二维矩阵。 这些特征会捕捉图片中的共通要素。 以叉叉的图片为例,它最重要的特征包括对角线和中间的交叉。 也就是说,任何叉叉的线条或中心点应该都会符合这些特征。
卷积
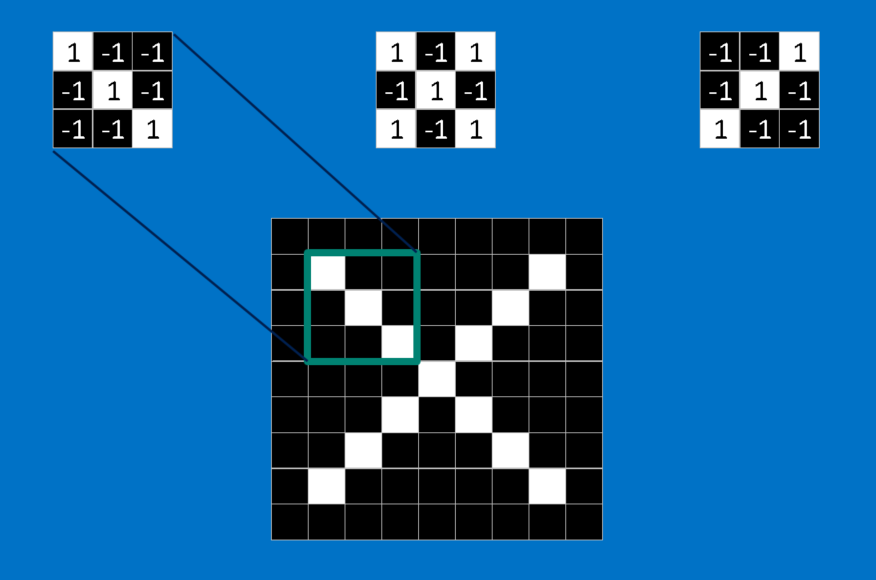
每当 CNN 分辨一张新图片时,在不知道上述特征在哪的情况下,CNN 会比对图片中的任何地方。 为了计算整张图片里有多少相符的特征,我们在这里创造了一套筛选机制。 这套机制背后的数学原理被称为卷积(convolution),也就是CNN的名称由来。
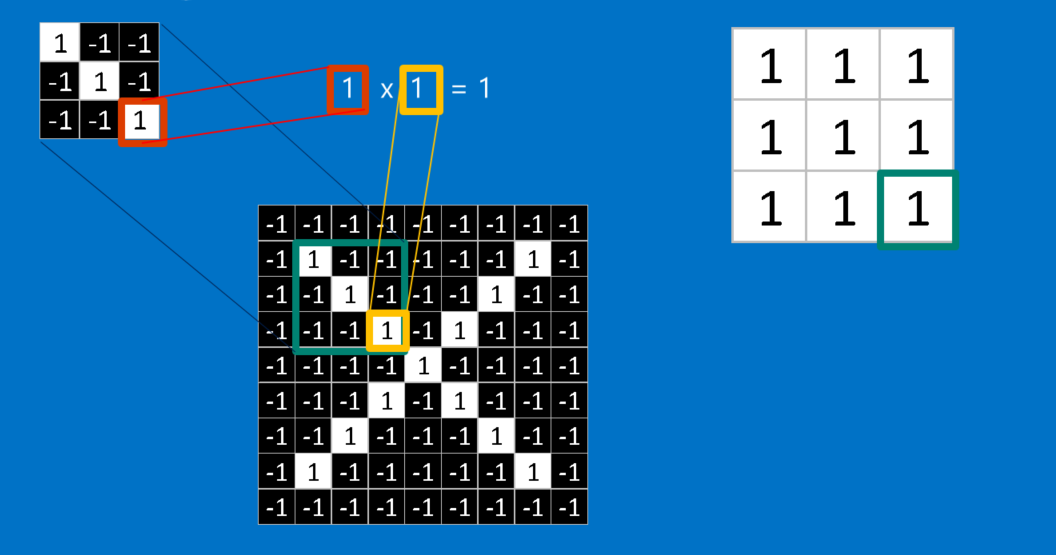
卷积的基本原理 , 要计算特征和图片局部的相符程度,只要将两者各个像素上的值相乘、再将总和除以像素的数量。 如果两个像素都是白色(值为 1),乘积就是 ;如果都是黑色(值为 -1),乘积就是 。 也就是说像素相符的乘积为 1,像素相异的乘积为 -1。 如果两张图的每个相素都相符,将这些乘积加总、再除以像素数量就会得到 1;反之,如果两者的像素完全相异,就会得到-1。1 * 1 = 1(-1) * (-1) = 1
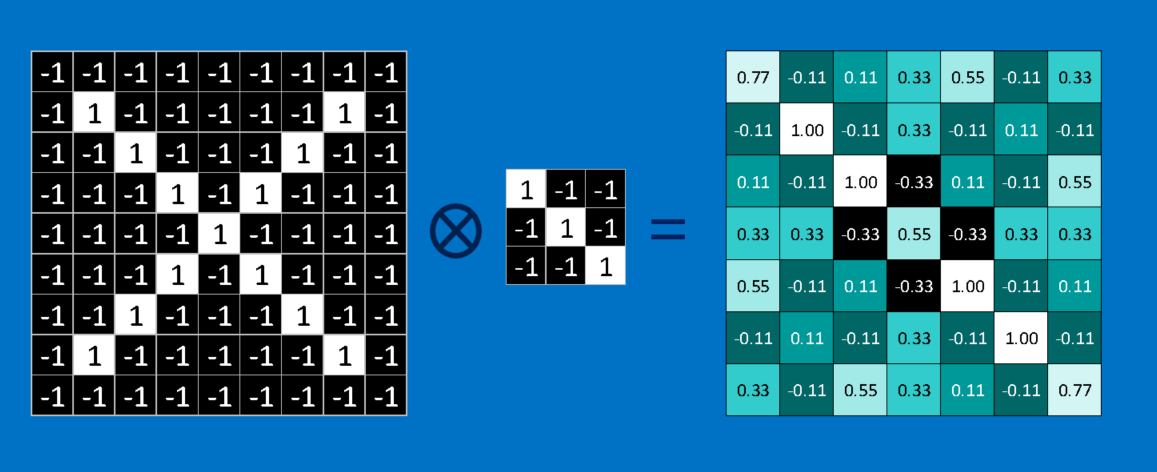
我们只要重复上述过程、归纳出图片中各种可能的特征,就能完成卷积。 然后,我们可以根据每次卷积的值和位置,制作一个新的二维矩阵。 这也就是利用特征筛选过后的原图,它可以告诉我们在原图的哪些地方可以找到该特征。 值越接近1的局部和该特征越相符,值越接近-1则相差越大,至于接近值接近0的局部,则几乎没有任何相似度可言。

下一步是将同样的方法应用在不同特征上,在图片中各个部位的卷积。 最后我们会得到一组筛选过的原图,每一张图都对应了一个特征。 我们可以将整段卷积运算,简单想成单一的处理步骤。这个步骤被称为卷积层,这也代表后面还有更多层。
从CNN的运作原理,不难看出它很耗运算资源。 虽然我们可以只用一张纸解释完CNN如何运作,但运作途中相加、相乘和相除的数量可以增加得非常快。 用数学来表达,可以说这些运算的数量,会随着(一)图片中相素的数量、(二)每个特征中像素的数量、以及(三)特征的数量呈现性增长。 有了这么多影响运算数量的因素,CNN所处理的问题可以不费吹灰之力地变得非常复杂,也难怪一些芯片制造商为了因应CNNs的运算需求,正在设计和制造专用的芯片。
池化
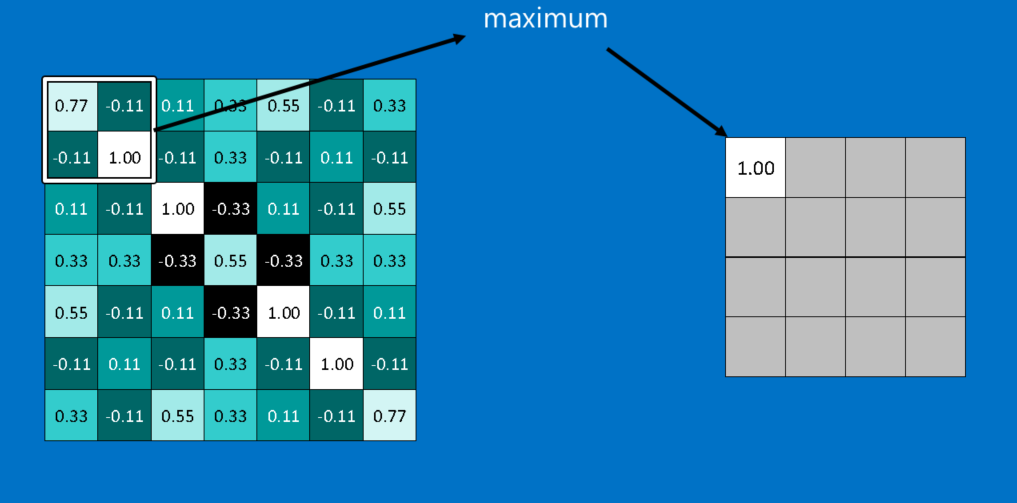
另一个CNN所使用的强大工具是池化(pooling) 。 池化是一个压缩图片并保留重要信息的方法, 池化会在图片上选取不同窗口(window),并在这个窗口范围中选择一个最大值。 实务上,边长为二或三的正方形范围,搭配两像素的间隔(stride)是满理想的设定。
原图经过池化以后,其所包含的像素数量会降为原本的四分之一,但因为池化后的图片包含了原图中各个范围的最大值,它还是保留了每个范围和各个特征的相符程度。 也就是说,池化后的信息更专注于图片中是否存在相符的特征,而非图片中哪里存在这些特征。 这能帮助CNN判断图片中是否包含某项特征,而不必分心于特征的位置。 这解决了前面提到电脑非常死板的问题。
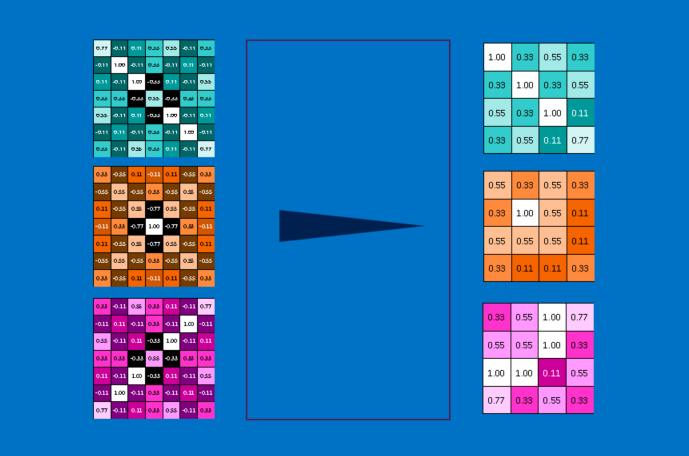
所以,池化层的功用是将一张或一些图片池化成更小的图片。 最终我们会得到一样数量、但包含更少像素的图片。 这也有助于改善刚才提到的耗费运算问题。 事先将一张八百万像素的图片简化成两百万像素,可以让后续工作变得更轻松。
线性整流单元
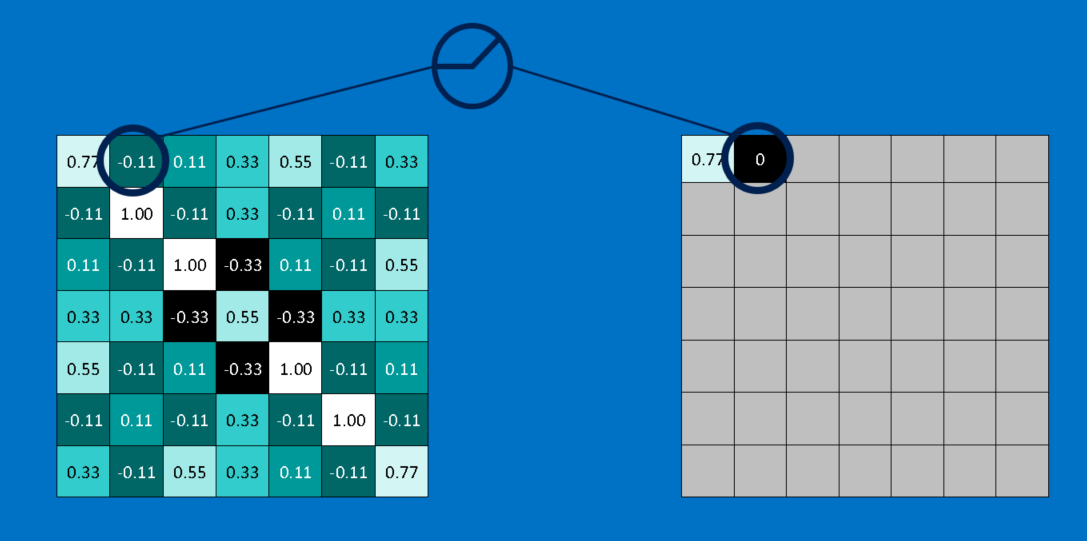
另一个细微但重要的步骤是线性整流单元(Rectified Linear Unit,ReLU),它的数学原理也很简单——将图片上的所有负数转为 0。 这个技巧可以避免 CNNs 的运算结果趋近 0 或无限大,它就像 CNNs 的车轴润滑剂一样——没有什么很酷的技术,但没有它 CNNs 也走不了多远。

线性整流后的结果和原图会有相同数量的像素,只不过所有的负值都会被换成零。
深度学习
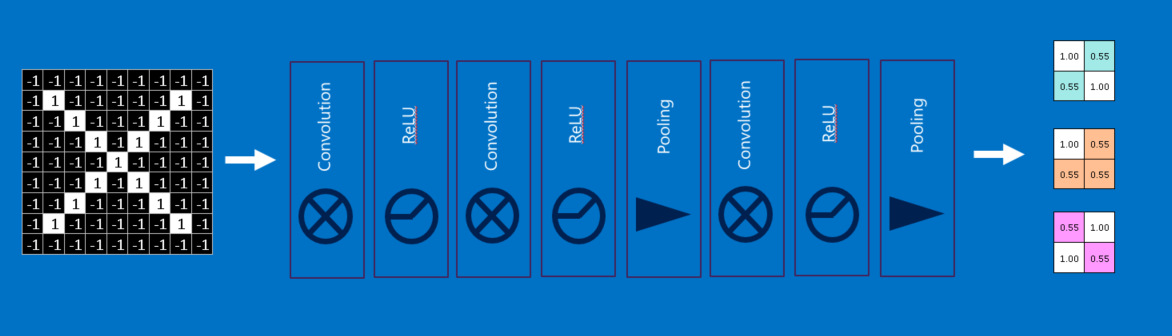
到这里,读者可能已经发现每一层运算的输入(二维矩阵)和输出(二维矩阵)都差不多,这代表我们可以像叠乐高积木一样,将每一层叠在一起。 所以原图在经过筛选、整流、池化之后会变成一组更小、包含特征信息的图片。 接下来,这些图片还可以再被筛选和压缩,它们的特征会随着每次处理变得更复杂,图片也会变得更小。 最后,比较低阶的处理层会包含一些简单的特征,例如棱角或光点;更高阶的处理层则会包含一些比较复杂的特征,像是形状或图案。 这些高级的特征通常已经变得很好识别,比方说在人脸识别的CNN中,我们可以在最高阶的处理层内看出完整的人脸。

全连接层
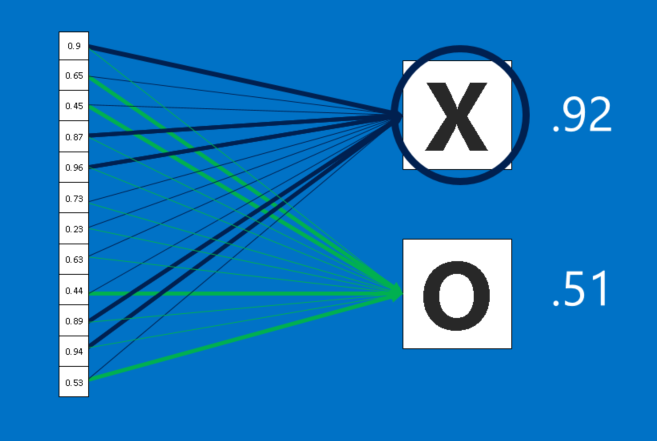
最后,CNN还有一项秘密武器——全连接层(fully connected layers)。 全连接层会集合高阶层中筛选过的图片,并将这些特征信息转化为票数。 在我们的例子里有两个选项:圈或叉。 在传统的神经网络架构中,全连接层所扮演的角色是主要构建单元(primary building block)。 当我们对这个单元输入图片时,它会将所有像素的值当成一个一维清单,而不是前面的二维矩阵。 清单里的每个值都可以决定图片中的符号是圈还是叉,不过这场选举并不全然民主。 由于某些值可以更好地判别叉,有些则更适合用来判断圈,这些值可以投的票数会比其他值还多。 所有值对不同选项所投下的票数,将会以权重(weight)或连结强度(connection strength)的方式来表示。
所以每当CNN判断一张新的图片时,这张图片会先经过许多低阶层,再抵达全链接层。 在投票表决之后,拥有最高票数的选项将成为这张图片的类别。

和其他阶层一样,多个全链接层也可以被组合在一起,因为它们输入(清单)和输出(投票结果)的形式非常相近。 实务上,我们可以将多个全链接层组合在一起,其中几层会出现一些虚拟、隐藏的投票选项。 每当我们新增一层全链接层,整个神经网络就可以学习更复杂的特征组合,所做出的判断也会更准确。
反向传播
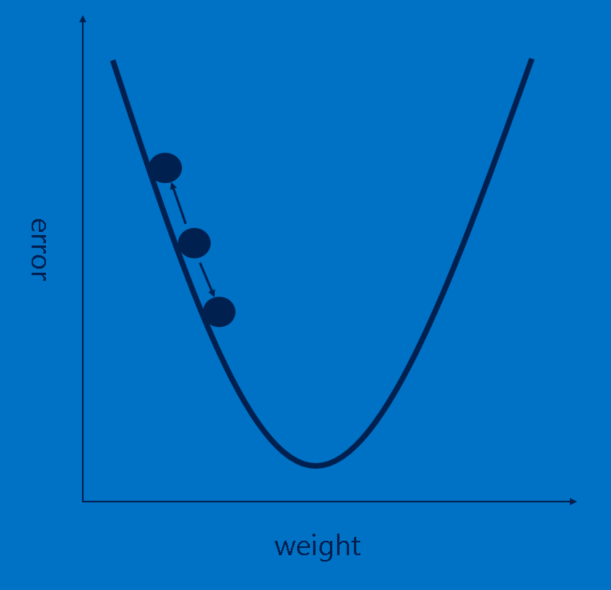
到目前为止的说明看起来都很不错,但其实背后还有一个大问题——特征从何而来? 以及在全链接层中,我们该如何决定权重? 如果我们得亲手完成这些工作,CNN应该不会像现在一样热门。 幸好,有个名叫反向传播(backpropagation)的机器学习技巧可以帮助我们解决这个问题。
为了使用反向传播,我们需要先准备一些已经有答案的图片。 这代表我们需要先静下心来,为几千张图片标上圈和叉。 接着我们得准备一个未经训练的CNN,其中任何像素、特征、权重和全连接层的值都是随机决定的。 然后我们就可以用一张张标好的图片训练这个 CNN。
经过CNN的处理,每张图片最终都会有一轮决定类别的选举。 和之前标好的正解相比,这场选举中的误判,也就是辨识误差,可以告诉我们怎样才是好的特征跟权重。 我们可以通过调整特征和权重,让选举所产生的误差降低。 在每次调整后,这些特征和权重会被微调高一点或低一点,误差也会被重新计算,成功降低误差的调整将被保留。 所以当我们调整过卷积层里的每个像素、和全链接层里的每个权重以后,我们可以得到一组稍微更擅于判断当前图片的权重。 接着我们可以重复以上步骤,辨认更多已标记的图片。 训练过程中,个别图片里的误判会过去,但这些图片中共通的特征和权重会留下。 如果有够多的已标记图片,这些特征和权重的值最后会趋近一个擅于辨识大多数图片的稳定状态。
不用说,反向传导也是个很耗费运算资源的步骤,这也是另一个驱使厂商生产特殊元件的原因。
超参数
除了以上说明,CNN还是有些很难解释和学习的面向。 CNN的设计者需要做很多决定,包括以下问题。
- 每个卷积层中该有多少特征? 每个特征中该有多少像素?
- 每个池化层中的窗口大小为何? 间隔又该多长?
- 每个额外的全链接层该有多少隐藏神经元(选项)?
除了这些问题,我们还需要考虑很多高阶的结构问题,像是CNN中该有多少处理层、顺序为何。 有些深度神经网络可能包括上千个处理层,设计上也就有非常多可能性。
有了这么多排列组合,我们只能测试其中一小部分的CNN设定。 因此CNN的设计通常会随着机器学习社群所累积下来的知识演进,效能上偶尔会出现一些出乎意料的提升。 虽然我们已经介绍了一些基本的CNN结构,但除此之外还有很多经测试后发现有效的改进技巧,例如使用新型处理层,或用更复杂的方式连接不同处理层。
图形处理之外
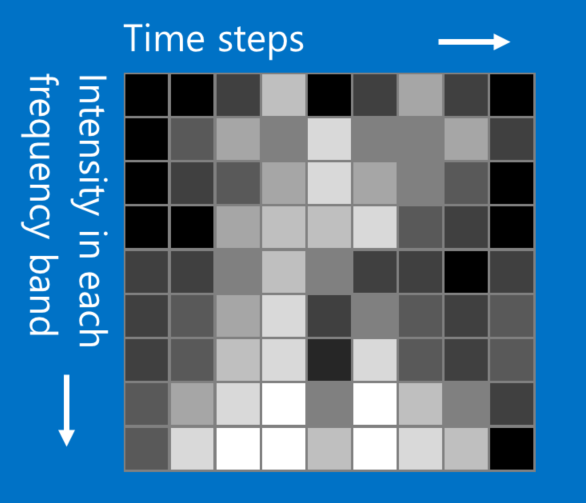
我们的圈和叉例子和图像识别有关,不过 CNN 也能处理其他型态的数据,技巧是将任何数据转成类似图片的形式。 例如,我们可以将音频根据时间细分,再将每一小段的声音分成低音、中音、高音或其他更高的频率。 如此一来,我们就可以把这些信息组成一个二维矩阵,其中各行代表不同时间、各列代表不同频率。 在这张假图片里,越相近的「像素」,彼此之间的关联性越高。 CNN 很擅长处理这样的数据,研究者们也发挥创意,将自然语言处理(natural language processing)中的文字数据、和新药研发过程中的化学数据都转成CNN可以处理的形式。
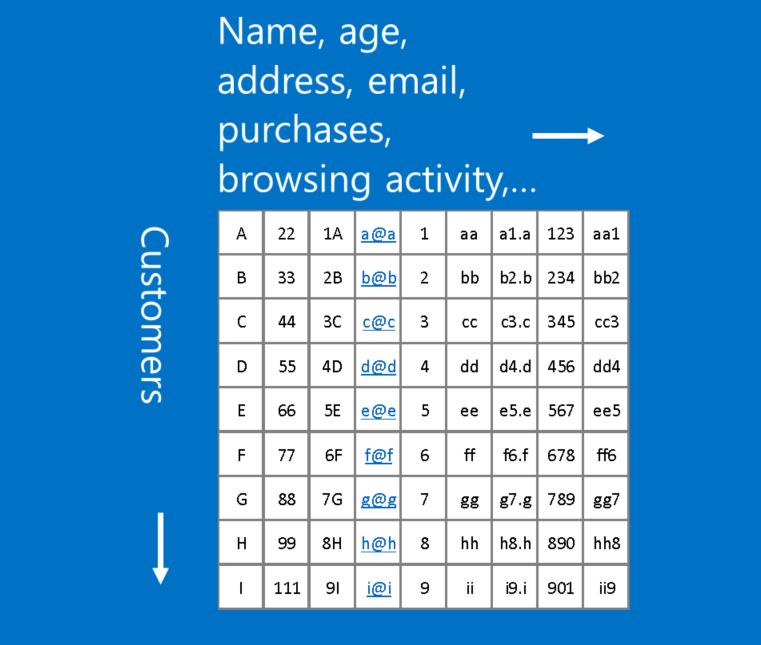
不过当每一横列(row)代表一位顾客、每一直行(column)分别代表这位顾客的姓名、邮箱、购买和浏览纪录等不同信息时,这种顾客数据并非CNN可以处理的形式。 因为在这个例子里,行和列的位置并不重要,也就是说在不影响信息的情况下,它们可以被任意排列。 相较之下,一张图片里像素的行列位置如果被调换,通常会丧失原本的意义。
所以使用CNN的一个诀窍是如果数据不会受改变行列顺序所影响,这种数据就不适合使用CNN处理。 不过如果可以将问题转成类似图片识别的形式,那 CNN 很可能是最理想的工具。
扩展阅读:CS231n课堂笔记
参考
- https://e2eml.school/how_convolutional_neural_networks_work.html
- https://brohrer.mcknote.com/zh-Hant/how_machine_learning_works/how_convolutional_neural_networks_work.html
- https://www.youtube.com/watch?v=FmpDIaiMIeA&t=3s











 京公网安备 11010802041100号
京公网安备 11010802041100号