有没有注意到,云原生的代表技术里面提到了一个概念——不可变基础设施(Immutable Infrastructure)。其他的代表技术,像容器、微服务等概念早已深入人心,声明式 API 我们在第一讲 Kubernetes 的前世今生中也有所提及。那么这个不可变基础设施到底是什么含义,又与我们今天要讲的 Pod 有什么关系?
不可变基础设施,这个名词最早由 Chad Fowler 于 2013 年在他的文章“Trash Your Servers and Burn Your Code: Immutable Infrastructure and Disposable Components*”*中提出来。随后,Docker 带来的“容器革命”以及 Kubernetes 引领的“云原生时代”,让不可变基础设施这个概念变得越来越流行。
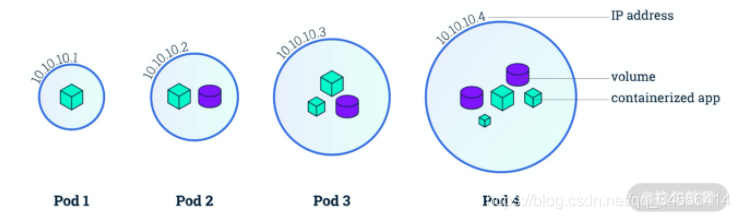
Pod 由一个或多个容器组成,如下图所示。Pod 中的容器不可分割,会作为一个整体运行在一个 Node 节点上,也就是说 Pod 是你在 Kubernetes 中可以创建和部署的最原子化的单位。
同一个 Pod 中的容器共享网络、存储资源。
每个 Pod 都会拥有一个独立的网络空间,其内部的所有容器都共享网络资源,即 IP 地址、端口。内部的容器直接通过 localhost 就可以通信。
Pod 可以挂载多个共享的存储卷(Volume),这时内部的各个容器就可以访问共享的 Volume 进行数据的读写。
既然一个 Pod 内支持定义多个容器,是不是意味着我可以任意组合,甚至将无关紧要的容器放进来都无所谓?不!这不是我们推荐的方式,也不是使用 Pod 的正确打开方式。
通常来说,如果在一个 Pod 内有多个容器,那么这几个容器最好是密切相关的,且可以共享一些资源的,比如网络、存储等。
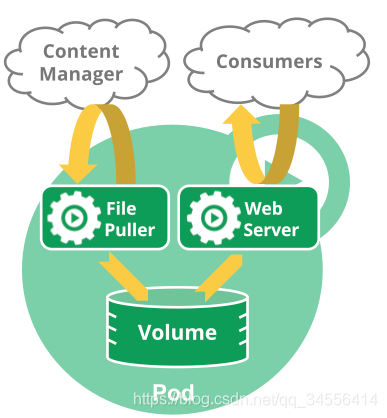
我们来看看官方文档中给的一个例子。这个 Pod 里面运行了两个容器 File Puller 和 Web Server。其中 File Puller 负责定期地从外部 Content Manager 同步内容,更新到挂载的共享存储卷(Volume)中,而 Web Server 只负责对外提供访问服务。两个容器之间通过共享的存储卷共享数据。
很多公司在刚开始容器化改造的时候,都会这么去使用容器,把容器当作 VM 来使用,有时候也叫作富容器模式。这其实是一种非常不好的尝试,也不符合不可变基础设施的理念。我们可以接受将富容器当作容器化改造的一个短暂的过渡形态,但不能将其作为改造的终态。后续,还需要进一步对这些富容器进行拆分、解耦。
看到这里,第二个问题的答案已经呼之欲出了。用一个 Pod 管理多个容器,既能够保持容器之间的隔离性,还能保证相关容器的环境一致性。使用粒度更小的容器,不仅可以使应用间的依赖解耦,还便于使用不同技术栈进行开发,同时还可以方便各个开发团队复用,减少重复造轮子。
如何声明一个 Pod
在 Kubernetes 中,所有对象都可以通过一个相似的 API 模板来描述,即元数据 (metadata)、规范(spec)和状态(status)。这种方式也是从 Borg 吸取的经验,避免过多的 API 定义设计,不利于统一和对接。Kubernetes 有了这种统一风格的 API 定义,方便了通过 REST 接口进行开发和管理。











 京公网安备 11010802041100号
京公网安备 11010802041100号