Hbase
一、 概念
1. 什么是Hbase
官方解释 : Hbase是一个开源的非关系型分布式数据库。它是一个基于Hadoop的分布式,可扩展,巨大数据仓库。
总结 : Hbase是一个高可靠、高性能、面向列、可伸缩的分布式数据库。是谷歌BigTable的开源实现,主要用来存储非结构化和半结构化的松散数据。当用户需要对海量数据进行实时(时效性)、随机(记录级别数据)读/写,用户可以使用Hbase。
常见的NoSQL数据库分类:Key-Value型: Redis、SSDB文档型(Document): MongoDB、Elasticsearch、Solr列存储:HBase图像:Neo4j和关系型数据库不同,NoSQL不同种类之间不可相互替换。
2. HDFS和Hbase的区别
Hbase是构建在HDFS之上的一个数据库服务,能够使用户通过Hbase数据库服务间接的操作HDFS,能够使用户对HDFS上的数据实现CRUD操作(细粒度操作)。
3. Hbase特性
- 线性和模块化扩展
- 严格一致reads和writes
- 表的自动和可配置分片(自动分区)
- RegionServers之间的自动故障转移支持
- 方便的基类,用于使用Apache Hbase表支持Hadoop MapReduce作业。
- 易于使用的Java API,用于客户端访问。
- Block cache和Bloom Filters 以进行实时查询
4. Hbase的意义
-
Hbase可以满足大规模数据实时处理应用的需求: HadoopMapReduce编程框架的高延迟数据处理机制,使得Hadoop无法满足大规模数据实时处理应用的需求。
-
Hbase可以实现随机访问。
-
具有高扩展性和高性能: 传统的通用关系型数据库无法应对在数据规模剧增时导致的系统扩展性和性能问题
-
节省存储空间: 传统关系数据库在数据结构变化时一般需要停机维护;空列浪费存储空间。
5. 行存储的缺点
-
IO利用率低:当我们需要某些字段时,行存储读取的是一行的数据,所有会出现多余的字段部分。这一部分IO的读取对于系统而言浪费。
-
磁盘利用率低:关系型数据库不支持稀疏存储(null值不存储),导致null值也会占用磁盘空间,给系统带来磁盘空间的浪费。
6. Hbase的结构
-
命名空间:0.96版本开始支持,是对多个表的逻辑分组,类似于关系数据库的database。
-
表(table): 一张表中包含若干行。
-
行(row): 一行包括一个行键(Row Key)和若干列簇,一张表中的行按照行键排序,并用行键作为索引。
-
列簇(column family): 每个列簇包含若干个列,列簇需要在建表时预定义,运行期间可以动态加入新的列。
-
单元格(cell): 存储的每一个值存放在一个单元格中。
-
版本(时间戳):默认是时间戳格式,同一列中可能包含若干单元格,这些单元格有版本号唯一区分,根据版本号降序排列。
7.列存储


-
将IO特性相似的列归为一个簇,Hbase底层在检索的时候以列簇为最小文件加载单位。
-
Hbase中所有的记录都是按照一定顺序排列的,ROWKEY>列簇>列名字>时间戳。默认查询返回时间戳最新版本记录。
-
支持稀疏存储
-
磁盘IO利用率100%
缺点:查询的值包含ROWKEY/列信息/时间戳
二、Hbase安装(单机版)
HDFS基本环境
1.安装JDK,配置环境变量JAVA_HOME
rpm -ivh jdk-8u171-linux-x64.rpm (安装JDK)

vi .bashrc(配置用户环境变量。/etc/profile是系统环境变量)

source .bashrc(重新加载资源)
jps(查看java相关的进程)
2.关闭防火墙
systemctl stop firewalld # 关闭 服务
systemctl disable firewalld # 关闭开机自启动
3.配置主机名和IP映射关系
vi /etc/hostname

vi /etc/hosts(配置映射关系)

4.配置SSH免密登录
ssh-keygen -t rsa(生成公私钥对 rsa:以rsa算法生成公私钥)

ssh-copy-id CentOS(将公钥添加到受信列表)
5.上传Hadoop安装包,并解压到/usr目录

6.配置HADOOP_HOME环境变量

7. 修改core-site.xml
vi /usr/hadoop-2.9.2/etc/hadoop/core-site.xml
<!--nn访问入口-->
<property><name>fs.defaultFS</name><value>hdfs://CentOS:9000</value>
</property>
<!--hdfs工作基础目录-->
<property><name>hadoop.tmp.dir</name><value>/usr/hadoop-2.9.2/hadoop-${user.name}</value>
</property>
8. 修改hdfs-site.xml
vi /usr/hadoop-2.9.2/etc/hadoop/hdfs-site.xml
<!--block副本因子-->
<property><name>dfs.replication</name><value>1</value>
</property>
<!--配置Sencondary namenode所在物理主机-->
<property><name>dfs.namenode.secondary.http-address</name><value>CentOS:50090</value>
</property>
<!--设置datanode最大文件操作数-->
<property><name>dfs.datanode.max.xcievers</name><value>4096</value>
</property>
<!--设置datanode并行处理能力-->
<property><name>dfs.datanode.handler.count</name><value>6</value>
</property>
9.修改slaves
vi /usr/hadoop-2.9.2/etc/hadoop/slaves
CentOS
10. 格式化NameNode&#xff0c;生成fsimage

11. 启动HDFS服务
start-dfs.sh
Zookeeper安装(协调)
1. 上传zookeeper的安装包,并解压在/usr目录下
tar -zxf zookeeper-3.4.12.tar.gz -C /usr/
2.配置Zookepeer的zoo.cfg


3. 创建zookeeper的数据目录
mkdir /root/zkdata
**4.启动zookeeper服务 **

Hbase配置与安装(数据库服务)
1. 上传Hbase安装包,并解压到/usr目录下
tar -zxf hbase-1.2.4-bin.tar.gz -C /usr/
2.配置Hbase环境变量HBASE_HOME

3.配置hbase-site.xml
cd /usr/hbase-1.2.4/
vi conf/hbase-site.xml
<property><name>hbase.rootdir</name><value>hdfs://CentOS:9000/hbase</value>
</property>
<property><name>hbase.cluster.distributed</name><value>true</value>
</property>
<property><name>hbase.zookeeper.quorum</name><value>CentOS</value>
</property>
<property><name>hbase.zookeeper.property.clientPort</name><value>2181</value>
</property>
4.修改hbase-env.sh,将HBASE_MANAGES_ZK修改为false

export HBASE_MANAGES_ZK&#61;false告知Hbase,使用外部Zookeeper
** 5. 启动Hbase**

**6.验证Hbase安装是否成功 **



Shell命令
1. 打开Hbase Shell

2. 获取帮助
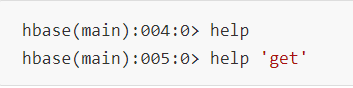
3. 查看服务器状态

4.查看版本信息

Namespace-数据库
1. 创建namespace

2.查看namespace详情

3. 修改namespace

4. 查看所有的namespace

5. 查看namespace的表
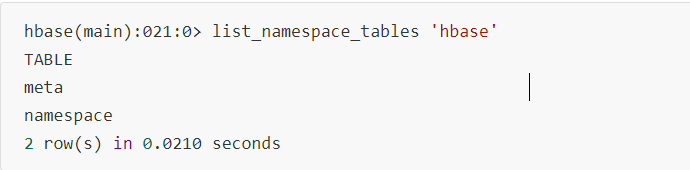
6. 删除namespace

表的操作
1. 查看所有表-(用户表)
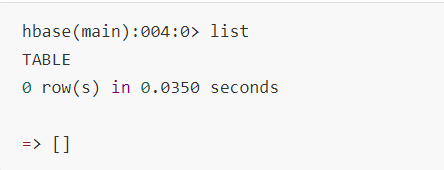
2. 创建表
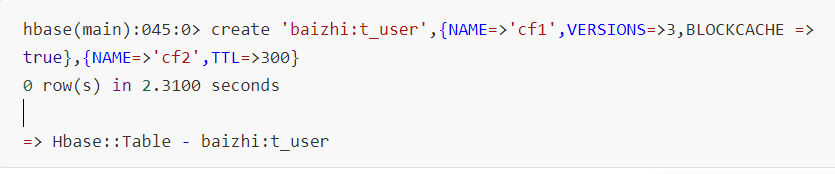
- VERSIONS:保留数据版本&#xff0c;默认值1(一共查询到的数量)
- TTL&#xff1a; 列簇下列存活时间&#xff0c;默认是FOREVER
- BLOCKCACHE:是否开启缓存&#xff0c;用于加快读
- IN_MEMORY:设置是否将列簇下所有数据加载内存中&#xff0c;加速读写&#xff0c;默认值false
- BLOOMFILTER:配置布隆过滤器(一种数据文件过滤机制)&#xff0c;默认值ROW&#xff0c;可选值两个
- ROW|ROWCOL:如果修改为ROWCOL系统需要额外开销存储列信息作为过滤文件的索引
3. 查看table详情

4. 禁用表

**5.启用表 **

6.截断表
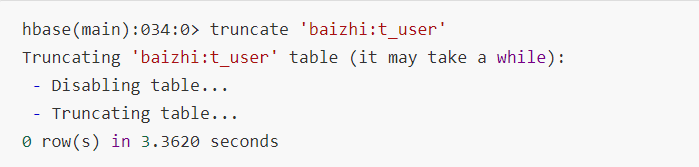
7.删除表

DML操作
1.put

2.get

3.delete/deleteal

4.scan









 京公网安备 11010802041100号
京公网安备 11010802041100号