作者:阿Love静_999 | 来源:互联网 | 2024-12-05 11:21
在分布式系统中,当多个服务器共同提供服务时,如何高效地将请求路由到正确的服务器是一个关键问题。传统的方法如简单哈希取模在服务器数量变化时会导致大量数据迁移。本文探讨了一致性哈希算法如何有效解决这一问题,确保系统的稳定性和高效性。
在分布式环境中,多个服务器协同工作以提供服务时,需要一种机制来决定特定的请求或数据应当被路由到哪个服务器。传统的哈希取模方法虽然简单直接,但在服务器数量变动时会导致大部分数据需要重新定位,影响系统性能和稳定性。为此,一致性哈希算法被提出并广泛应用,以最小化数据迁移量,保持系统的高效运行。
1. 一致性哈希算法的优势
一致性哈希算法设计之初即考虑了分布式环境下的几个核心需求:
- 均衡性:确保数据均匀分布于各个节点,避免某些节点过载。
- 单调性:当系统扩展或收缩时,已存在的数据尽可能保持原有分配,减少数据迁移。
- 分散性:保证同一数据项在不同客户端操作下的一致性,避免因客户端差异导致的数据分散。
- 负载均衡:确保每个缓存实例上的数据量大致相等,避免资源浪费。
这些特性使得一致性哈希成为处理大规模分布式数据的理想选择。
2. 一致性哈希的工作原理
一致性哈希的基本思路是将数据项和服务器节点都映射到一个固定的哈希环上。具体步骤包括:
- 对每个服务器节点执行哈希运算,确定其在哈希环上的位置。
- 同样对数据项执行相同的哈希运算,然后顺时针查找最近的一个服务器节点作为目标节点。
这样,即使有新的服务器加入或旧的服务器离开,也只有部分数据需要重新分配,大大减少了数据迁移的成本。
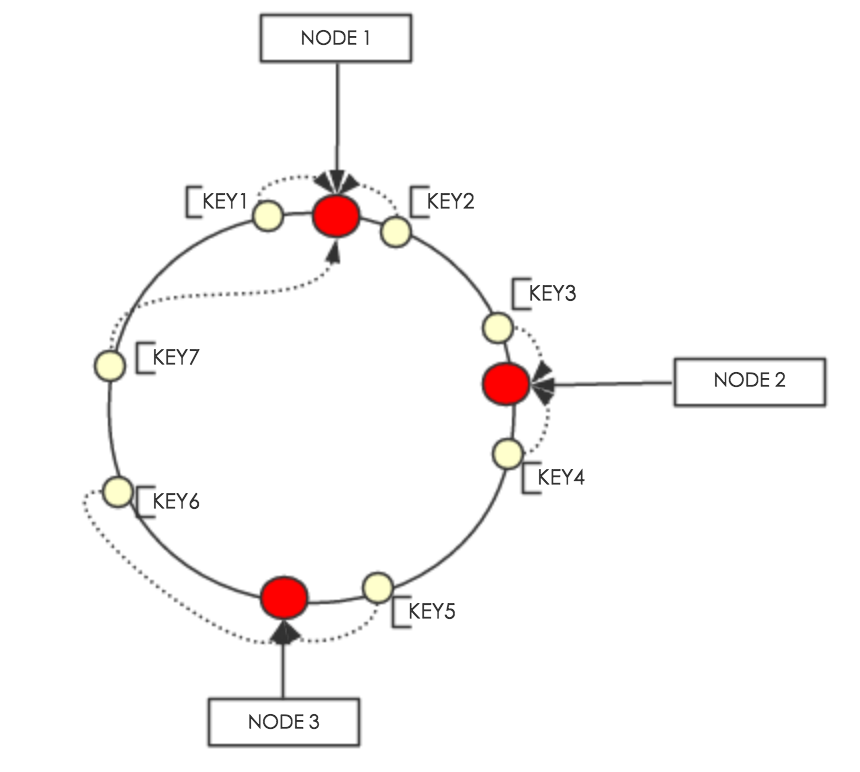
例如,在上图中,如果节点 NODE 2 失效,只有该节点上的数据需要迁移到下一个节点,而其他数据的位置保持不变。
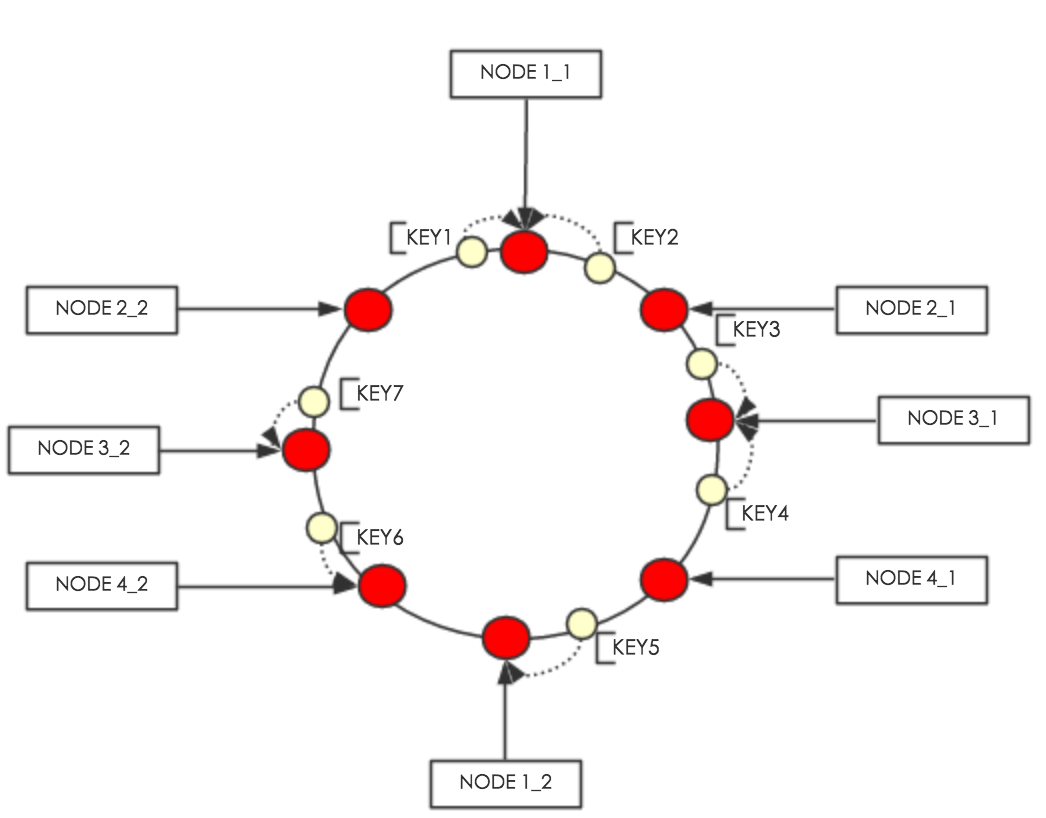
3. 虚拟节点的作用
为了进一步提高数据分布的均匀性,可以在每个物理节点上创建多个“虚拟节点”。这些虚拟节点同样分布在哈希环上,增加了哈希环上的点数,有助于更均匀地分布数据。如下图所示,每个物理节点被映射为多个虚拟节点,显著提高了数据分布的平衡性。
4. 一致性哈希与其他算法的比较
在分布式缓存中,除了简单哈希取模外,还有槽映射等方法。这些方法各有优缺点:
- 哈希取模:虽然实现简单,但在节点增减时会导致大量数据迁移。
- 槽映射:通过预定义的槽来分配数据,减少了数据迁移,但需要维护槽与节点的映射关系。
- 一致性哈希:结合了前两种方法的优点,既能有效减少数据迁移,又无需额外维护复杂的映射关系。
5. 实际应用与实现
在实际应用中,一致性哈希算法可以通过多种编程语言实现,例如使用 Go 语言实现时,可以考虑引入节点权重的概念,使得性能更好的节点承担更多的数据。相关实现代码可在 GitHub 上找到,如 https://github.com/g4zhuj/hashring。
6. 结论
一致性哈希算法通过其独特的设计,有效地解决了分布式系统中数据迁移的问题,提高了系统的稳定性和效率。无论是 Redis 的槽映射机制还是 Memcached 的一致性哈希实现,都是为了更好地适应分布式环境下的数据管理需求。随着技术的发展,一致性哈希将继续发挥重要作用。











 京公网安备 11010802041100号
京公网安备 11010802041100号