续前一篇:深度残差网络+自适应参数化ReLU激活函数(调参记录4)本文继续测试AdaptivelyParametricReLU(APReLU)激活函数在Cifar10图像集上的效果
续前一篇:
深度残差网络自适应参数化ReLU激活函数(调参记录4)
本文继续测试自适应参数回归激活函数在Cifar10图像集上的效果,每个残差模块包含两个33的卷积层,一共有27个残差模块,卷积核的个数分别是16个、32个和64个。
在APReLU激活函数中,全连接层的神经元个数,与输入特征图的通道数,保持一致。(这也是原始论文中的设置,在之前的四次调参中,将全连接层的神经元个数,设置成了输入特征图通道数的1/4,想着可以避免过拟合)
其中,自适应参数化ReLU是参数ReLU激活函数的改进版本:
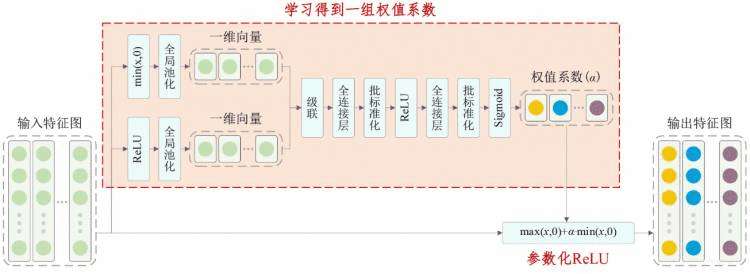
自适应参数化ReLU激活函数
Keras代码:
#!/usr/tldl/env pyt 3
# -*- coding: utf-8 -*-
'''
创建于2020年四月14日星期二04:17336046
使用TensorFlow 1.0.1和Keras 2.2.1实现
米(米的缩写))赵,钟少生,傅晓生,唐斌,董少生,佩契特,
用于故障诊断的具有自适应参数整流器线性单元的深度残差网络,
电气电子工程师学会工业电子交易,2020,DOI: 10.1109/TIE
@作者: M赵
'''
从__未来_ _导入打印功能
进口keras
将numpy作为铭牌导入
从keras.datasets导入cifar10
从角膜层导入密集、Conv2D、BatchNormalization、激活、最小值
从角膜层导入平均池2D,输入,全局平均池2D,连接,整形
来自keras.regularizers导入l2
从keras导入后端作为K
来自keras.models导入模型
来自keras导入优化器
来自喀拉斯。预处理。图像导入ImageDataGenerator
从喀拉斯。回调导入学习速率调度器
K.set _学习_阶段(1)
#数据,在列车和测试集之间分割
(x_train,y_train),(x_test,y_test)=cifar10.load_data()
#噪声数据
x _ train=x _ train。一种类型(' float 32 ')/255 .
x _ test=x _ testas类型(' float 32 ')/255 .
x_test=x_test-np.mean(x_train)
x _ train=x _ train-NP。平均值(x _ train)
打印(' x_train shape: ',x_train.shape)
打印(x_train.shape[0],"训练样本")
打印(x_test.shape[0],"测试样本")
#将类向量转换为三元类矩阵
y _ train=keras。utils。to _ classic(y _ train,10)
y _ test=keras。utils。to _ classic(y _ test,10)
#安排学习速度,每200个小时乘以0.1
极好的调度程序(纪元):
如果纪元% 200==0且纪元!=0:
lr=k . get _ value(模型。优化器。lr)
K.set_value(model.optimizer.lr,lr * 0.1)
打印(' lr已更改为{} '。格式(lr * 0.1))
返回K.get_value(model.optimizer.lr)
#自适应参数整流器链
ear unit (APReLU)
def aprelu(inputs):
# get the number of channels
channels = inputs.get_shape().as_list()[-1]
# get a zero feature map
zeros_input = keras.layers.subtract([inputs, inputs])
# get a feature map with positive features
pos_input = Activation('relu')(inputs)
# get a feature map with negative features
neg_input = Minimum()([inputs,zeros_input])
# define a network to obtain the scaling coefficients
scales_p = GlobalAveragePooling2D()(pos_input)
scales_n = GlobalAveragePooling2D()(neg_input)
scales = Concatenate()([scales_n, scales_p])
scales = Dense(channels, activation='linear', kernel_initializer='he_normal', kernel_regularizer=l2(1e-4))(scales)
scales = BatchNormalization()(scales)
scales = Activation('relu')(scales)
scales = Dense(channels, activation='linear', kernel_initializer='he_normal', kernel_regularizer=l2(1e-4))(scales)
scales = BatchNormalization()(scales)
scales = Activation('sigmoid')(scales)
scales = Reshape((1,1,channels))(scales)
# apply a paramtetric relu
neg_part = keras.layers.multiply([scales, neg_input])
return keras.layers.add([pos_input, neg_part])
# Residual Building block
def residual_block(incoming, nb_blocks, out_channels, downsample=False,
downsample_strides=2):
residual = incoming
in_channels = incoming.get_shape().as_list()[-1]
for i in range(nb_blocks):
identity = residual
if not downsample:
downsample_strides = 1
residual = BatchNormalization()(residual)
residual = aprelu(residual)
residual = Conv2D(out_channels, 3, strides=(downsample_strides, downsample_strides),
padding='same', kernel_initializer='he_normal',
kernel_regularizer=l2(1e-4))(residual)
residual = BatchNormalization()(residual)
residual = aprelu(residual)
residual = Conv2D(out_channels, 3, padding='same', kernel_initializer='he_normal',
kernel_regularizer=l2(1e-4))(residual)
# Downsampling
if downsample_strides > 1:
identity = AveragePooling2D(pool_size=(1,1), strides=(2,2))(identity)
# Zero_padding to match channels
if in_channels != out_channels:
zeros_identity = keras.layers.subtract([identity, identity])
identity = keras.layers.concatenate([identity, zeros_identity])
in_channels = out_channels
residual = keras.layers.add([residual, identity])
return residual
# define and train a model
inputs = Input(shape=(32, 32, 3))
net = Conv2D(16, 3, padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(1e-4))(inputs)
net = residual_block(net, 9, 16, downsample=False)
net = residual_block(net, 1, 32, downsample=True)
net = residual_block(net, 8, 32, downsample=False)
net = residual_block(net, 1, 64, downsample=True)
net = residual_block(net, 8, 64, downsample=False)
net = BatchNormalization()(net)
net = aprelu(net)
net = GlobalAveragePooling2D()(net)
outputs = Dense(10, activation='softmax', kernel_initializer='he_normal', kernel_regularizer=l2(1e-4))(net)
model = Model(inputs=inputs, outputs=outputs)
sgd = optimizers.SGD(lr=0.1, decay=0., momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
# data augmentation
datagen = ImageDataGenerator(
# randomly rotate images in the range (deg 0 to 180)
rotation_range=30,
# randomly flip images
horizontal_flip=True,
# randomly shift images horizontally
width_shift_range=0.125,
# randomly shift images vertically
height_shift_range=0.125)
reduce_lr = LearningRateScheduler(scheduler)
# fit the model on the batches generated by datagen.flow().
model.fit_generator(datagen.flow(x_train, y_train, batch_size=100),
validation_data=(x_test, y_test), epochs=500,
verbose=1, callbacks=[reduce_lr], workers=4)
# get results
K.set_learning_phase(0)
DRSN_train_score1 = model.evaluate(x_train, y_train, batch_size=100, verbose=0)
print('Train loss:', DRSN_train_score1[0])
print('Train accuracy:', DRSN_train_score1[1])
DRSN_test_score1 = model.evaluate(x_test, y_test, batch_size=100, verbose=0)
print('Test loss:', DRSN_test_score1[0])
print('Test accuracy:', DRSN_test_score1[1])
程序结果:
Train loss: 0.09905459056794644
Train accuracy: 0.9974600024223328
Test loss: 0.4356186859309673
Test accuracy: 0.9252000027894973
测试准确率到了92.52%,还不错。其实训练集的loss还有下降的趋势。
M. Zhao, S. Zhong, X. Fu, B. Tang, S. Dong, M. Pecht, Deep Residual Networks with Adaptively Parametric Rectifier Linear Units for Fault Diagnosis, IEEE Transactions on Industrial Electronics, 2020, DOI: 10.1109/TIE.2020.2972458
https://ieeexplore.ieee.org/document/8998530







 京公网安备 11010802041100号
京公网安备 11010802041100号