作者:寒落落 | 来源:互联网 | 2023-10-10 14:24
上图是InputFormat的派生子类关系图,这篇主要讲解FileInputDormat的实现类——>NLineInputFormat由于InputFormat是一个抽象类,

上图是InputFormat的派生子类关系图,这篇主要讲解FileInputDormat的实现类——>NLineInputFormat
由于InputFormat是一个抽象类,不同的实现类,分片机制不同,如下图:
NLineInputFormat源码:
public class NLineInputFormat extends FileInputFormat {
public static final String LINES_PER_MAP =
"mapreduce.input.lineinputformat.linespermap";
public RecordReader createRecordReader(
InputSplit genericSplit, TaskAttemptContext context)
throws IOException {
context.setStatus(genericSplit.toString());
return new LineRecordReader();
}
/**
* Logically splits the set of input files for the job, splits N lines
* of the input as one split.
*
* @see FileInputFormat#getSplits(JobContext)
*/
public List getSplits(JobContext job)
throws IOException {
List splits = new ArrayList();
int numLinesPerSplit = getNumLinesPerSplit(job);
for (FileStatus status : listStatus(job)) {
splits.addAll(getSplitsForFile(status,
job.getConfiguration(), numLinesPerSplit));
}
return splits;
}
public static List getSplitsForFile(FileStatus status,
Configuration conf, int numLinesPerSplit) throws IOException {
List splits = new ArrayList ();
Path fileName = status.getPath();
if (status.isDirectory()) {
throw new IOException("Not a file: " + fileName);
}
FileSystem fs = fileName.getFileSystem(conf);
LineReader lr = null;
try {
FSDataInputStream in = fs.open(fileName);
lr = new LineReader(in, conf);
Text line = new Text();
int numLines = 0;
long begin = 0;
long length = 0;
int num = -1;
while ((num = lr.readLine(line)) > 0) {
numLines++;
length += num;
if (numLines == numLinesPerSplit) {
splits.add(createFileSplit(fileName, begin, length));
begin += length;
length = 0;
numLines = 0;
}
}
if (numLines != 0) {
splits.add(createFileSplit(fileName, begin, length));
}
} finally {
if (lr != null) {
lr.close();
}
}
return splits;
}
/**
* NLineInputFormat uses LineRecordReader, which always reads
* (and consumes) at least one character out of its upper split
* boundary. So to make sure that each mapper gets N lines, we
* move back the upper split limits of each split
* by one character here.
* @param fileName Path of file
* @param begin the position of the first byte in the file to process
* @param length number of bytes in InputSplit
* @return FileSplit
*/
protected static FileSplit createFileSplit(Path fileName, long begin, long length) {
return (begin == 0)
? new FileSplit(fileName, begin, length - 1, new String[] {})
: new FileSplit(fileName, begin - 1, length, new String[] {});
}
/**
* Set the number of lines per split
* @param job the job to modify
* @param numLines the number of lines per split
*/
public static void setNumLinesPerSplit(Job job, int numLines) {
job.getConfiguration().setInt(LINES_PER_MAP, numLines);
}
/**
* Get the number of lines per split
* @param job the job
* @return the number of lines per split
*/
public static int getNumLinesPerSplit(JobContext job) {
return job.getConfiguration().getInt(LINES_PER_MAP, 1);
}
}
发下他重写getSplit()方法,它的切片机制不同与FileInputFormat,不再按Block 块去划分,而是按NlineInputFormat指定的行数N来划分。即输入文件的总行数/N=切片数,如果不整除,切片数=商+1
例子:
输入四行数据。

使用案例:
1.需求
对每个单词进行个数统计,要求根据每个输入文件的行数来规定输出多少个切片。此案例要求每三行放入一个切片中。


代码实现:
package com.c21.mapreduce.nline;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class NLineMapper extends Mapper{
private Text k = new Text();
private LongWritable v = new LongWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 获取一行
String line = value.toString();
// 2 切割
String[] splited = line.split(" ");
// 3 循环写出
for (int i = 0; i
k.set(splited[i]);
context.write(k, v);
}
}
}
(2)编写Reducer类
package com.c21.mapreduce.nline;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class NLineReducer extends Reducer{
LongWritable v = new LongWritable();
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
long sum = 0l;
// 1 汇总
for (LongWritable value : values) {
sum += value.get();
}
v.set(sum);
// 2 输出
context.write(key, v);
}
}
(3)编写Driver类
package com.c21.mapreduce.nline;
import java.io.IOException;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.NLineInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class NLineDriver {
public static void main(String[] args) throws IOException, URISyntaxException, ClassNotFoundException, InterruptedException {
// 输入输出路径需要根据自己电脑上实际的输入输出路径设置
args = new String[] { "e:/input/inputword", "e:/output1" };
// 1 获取job对象
Configuration cOnfiguration= new Configuration();
Job job = Job.getInstance(configuration);
// 7设置每个切片InputSplit中划分三条记录
NLineInputFormat.setNumLinesPerSplit(job, 3);
// 8使用NLineInputFormat处理记录数
job.setInputFormatClass(NLineInputFormat.class);
// 2设置jar包位置,关联mapper和reducer
job.setJarByClass(NLineDriver.class);
job.setMapperClass(NLineMapper.class);
job.setReducerClass(NLineReducer.class);
// 3设置map输出kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 4设置最终输出kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 5设置输入输出数据路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 6提交job
job.waitForCompletion(true);
}
}
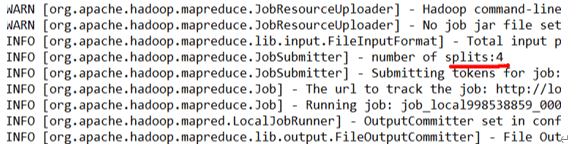
结果如图:




 京公网安备 11010802041100号
京公网安备 11010802041100号