>> 偶遇JobClient
这两年在在整一个云计算的东西,但工作主要集中在Client端。
对Hadoop早有耳闻,但一直没有机会,前几天看到了JobClient这个熟悉的字眼,所以就把Hadoop的源代码拖来,找个机会看看。倒不是想用Hadoop干什么事情,了解了解,免得“云深不知处”。
虽然Hadoop是用Java开发的,但问题不大,基本上能看懂。Hadoop当然是博大精深,包含了conf/DFS/io/ipc/MapReduce几个部分,但我也只是挑了MapReduce的代码作为观摩对象:
感兴趣的文件夹:
...\src\mapred\org\apache\hadoop\mapred
...\src\mapred\org\apache\hadoop\mapreduce
感兴趣的类:
JobTracker/TaskTracker/
JobID/JobProfile/JobContext
JobInProgress/TaskInProgress/MapTask/ReduceTask
JobHistory/JobHistoryServer
>> 关于MapReduce
MapReduce模型隐藏了并行化,容错,位置优化和负载均衡的细节,使用起来比较简洁。
1. MapReduce == Map -> Combine -> Reduce
Map-Reduce框架的运作完全基于
由于Key和value的类需要支持被序列化操作,它们必须要实现Writable接口。此外,key的类还必须实现WritableComparable接口,以便可以让框架对数据集的执行排序操作。
一个Map-Reduce任务的执行过程以及数据输入输出的类型如下所示:
(input)
2. 例子: WordCount 1.0
MapReduce Tutorial中有一个WordCount的例子,要求从读取两个文本文件并计算文本中每个单词的总数。
源代码:
package org.myorg;
import java.io.IOException;
import java.util.*;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.util.*;
public class WordCount {
// Mapper之Map方法
public static class Map extends MapReduceBase implements Mapper
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, OutputCollector
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
output.collect(word, one);
}
}
}
// Reducer之Reduce方法
public static class Reduce extends MapReduceBase implements Reducer
public void reduce(Text key, Iterator
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
// Job Configuraion
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("wordcount");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
// 设置Mapper/Combiner/Reducer
conf.setMapperClass(Map.class);
conf.setCombinerClass(Reduce.class);
conf.setReducerClass(Reduce.class);
// 设置输入/输出的格式,此处均为Text
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
// 运行Job
JobClient.runJob(conf);
}
}
Inputs(file01 & file02):
-------------------------------------------------------------------
../wordcount/input/file01: Hello World Bye World
../wordcount/input/file02: Hello Hadoop Goodbye Hadoop
-------------------------------------------------------------------
Output:
------------------
Bye 1
Goodbye 1
Hadoop 2
Hello 2
World 2
------------------
Workflow:
Step1: Mapper
Mapper通过map方法每次处理一行文本&#xff0c;然后利用StringTokenizer将其分离成Tokens&#xff0c;然后就将键值对<
----------------------------
the first map emits:
The second map emits:
-----------------------------
Step2: Combine
在WordCount这个例子中&#xff0c;Combiner与Reducer是一样的&#xff0c;Combiner类负责将相同key的值合并起来。
----------------------------------
The output of the first map:
The output of the second map:
----------------------------------
Step3&#xff1a; Reduce
Reducer类通过reduce方法&#xff0c;计算每个单词的总数&#xff0c;从而得到最终的输出。
-----------------------------------
Thus the output of the job is:
-----------------------------------
>> MapReduce Architecture
--------------------------------------------------------------------------------------------
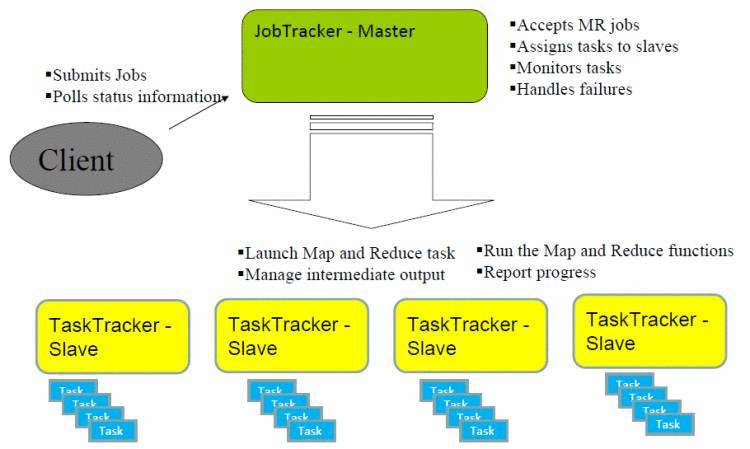
--------------------------------------------------------------------------------------------
>> JobClient
每一个job都会在用户端通过JobClient类将应用程序以及配置参数Configuration打包成jar文件存储在HDFS&#xff0c;并把路径提交到 JobTracker的master服务&#xff0c;然后由master创建每一个Task&#xff08;即MapTask和ReduceTask&#xff09;将它们分发到各个 TaskTracker服务中去执行。
Methods:
JobClient.runJob()
JobClient.submitJob
JobClient.killJob()
>> JobTracker
它们都是由一个master服务JobTracker和多个运行于多个节点的slaver服务TaskTracker两个类提供的服务调度的。 master负责调度job的每一个子任务task运行于slave上&#xff0c;并监控它们&#xff0c;如果发现有失败的task就重新运行它&#xff0c;slave则负责直接执行每 一个task。TaskTracker都需要运行在HDFS的DataNode上&#xff0c;而JobTracker则不需要&#xff0c;一般情况应该把JobTracker 部署在单独的机器上。
JobTracker is a daemon per pool that administers all aspects of mapred activities.
JobTracker keeps all the current jobs by containing instances of JobInProgress.
Methods:
JobTracker.submitJob(): creates/adds a JobInProgress to jobs and jobsByArrival
JobTracker.pollForNewTask()
>> JobInProgress/TaskInProgress
JobInProgress represents a job as it is being tracked by JobTracker.
TaskInProgress represents a set of tasks for a given unique input, where input is a split for map task or a partition for reduce task.
>> MapTask/ReduceTask:
MapTask offers method run() that calls MapRunner.run(), which in turn calls the user-supplied Mapper.map().
ReduceTask offers run() that sorts input files using SequenceFile.Sorter.sort(), and then calls user-supplied Reducer.reduce().
>> 其他
Hadoop的Task Recovery机制还是比较有意思的&#xff0c;它可以重新尝试运行失败的Task&#xff0c;具体可以看看JobTracker.RecoveryManager。
// I should borrow some concept of Hadoop to SolidMCP
// RunningJob
// Reporter
// JobClient
// JobHistory.HistoryCleaner
// JobHistory.JobInfo
// JobHistory.Listener
// JobProfile
// TaskReport
// TaskTracker
// TaskLog
// JobQueueInfo
// JobContext
// JobEndNotifier
// JobControl
References:
http://wiki.apache.org/hadoop/HadoopMapRedClasses
http://sebug.net/paper/databases/nosql/Nosql.html



![[大整数乘法] java代码实现](https://img1.php1.cn/3cd4a/24c6f/9f3/0133bb25da242824.jpeg)



 京公网安备 11010802041100号
京公网安备 11010802041100号