作者:欧阳俊俊2502921727 | 来源:互联网 | 2023-08-16 21:38
1ReduceJoin2MapJoin1.使用场景Map Join适用于一张表十分小、一张表很大的场景。2.优点思考:在Reduce端处理过多的表,非常容易产生数据倾斜。怎么办?在
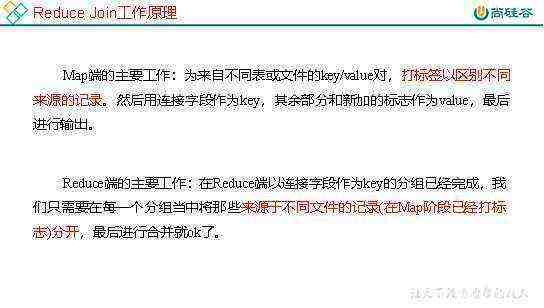
1 Reduce Join
2 Map Join
1.使用场景
Map Join适用于一张表十分小、一张表很大的场景。
2.优点
思考:在Reduce端处理过多的表,非常容易产生数据倾斜。怎么办?
在Map端缓存多张表,提前处理业务逻辑,这样增加Map端业务,减少Reduce端数据的压力,尽可能的减少数据倾斜。
3.具体办法:采用DistributedCache
(1)在Mapper的setup阶段,将文件读取到缓存集合中。
(2)在驱动函数中加载缓存。
// 缓存普通文件到Task运行节点。
job.addCacheFile(new URI("file://e:/cache/pd.txt"));







 京公网安备 11010802041100号
京公网安备 11010802041100号