前言:现在开始安装Hadoop啦。
注意,每一个节点的安装和配置是相同的。实际工作中,通常在master 节点上完成安装和配置后,然后将安装目录复制到其他节点即可。
这里所有操作都是root用户权限
1.下载Hadoop安装
登录进入 http://hadoop.apache.org/ hadoop官网下载自己的Hadoop版本
(这里我们下载的是:hadoop-2.7.5.tar.gz)
2.解压安装包
找到 hadoop-2.7.5.tar.gz 将其上传到 master 节点的“ /opt/hadoop ”目录内,用xshell的xftp工具上传文件。
上传完后,在master主机进入/opt/hadoop目录,执行解压缩命令“tar -zxvf hadoop-2.7.5.tar.gz”,即可实现安装,回车后系统开始解压缩 tar -zxvf hadoop-2.7.5.tar.gz 文件,
屏幕上会不断显示解压过程信息,执行成功后,系统将在 Hadoop 下自动创建tar -zxvf hadoop-2.7.5 子目录,将" hadoop-2.7.5 ”文件夹名称修改为“ hadoop ”此即Hadoop安装目录。
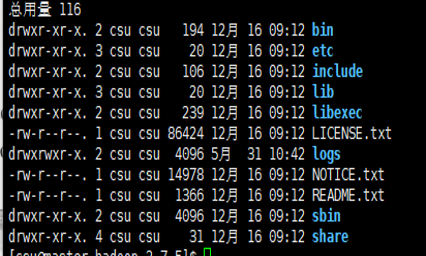
我们进入Hadoop安装目录,查看一下安装文件,如果显示如图所示的文件列表,说明解压缩成功。
2.配置env文件
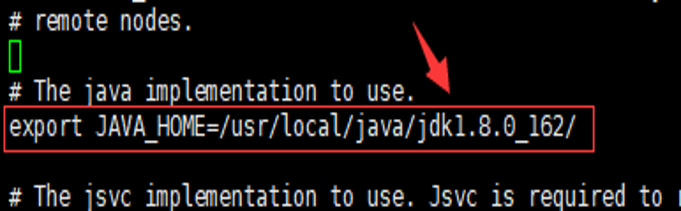
修改“ /opt/hadoop/hadoop/etc/hadoop/hadoop-env.sh ” 文件,找到“ export JAVA_HOME ”这行,配置jdk路径。如图
export JAVA_HOME=/user/local/java/jdk1.8.0.162/
编辑完毕,保存退出即可
3.配置核心组件文件
Hadoop 的核心组件文件是 core-site.xml,位于“/opt/hadoop/hadoop/etc/hadoop ”子目录下。
用 vi编辑 core-site.xml 文件,需要将下面的配置代码放在文件的
编辑完毕,保存退出即可。
4.配置文件系统
Hadoop 的文件系统配置文件是 hdfs-site.xml,也位于“/opt/hadoop/hadoop/etc/hadoop”子目录下。
用vi编辑该文件,需要将下面的代码填充到文件的
编辑完毕,保存退出即可。
5.配置yarn-site.xml文件
Yarn的站点配置文件是 yarn-site.xml,也位于“/opt/hadoop/hadoop/etc/hadoop”子目录下。
用vi编辑该文件,需要将下面的代码填充到文件的
编辑完毕,保存退出即可。
6.配置MapReduce计算框架文件
在“/opt/hadoop/hadoop/etc/hadoop”子目录下,系统已经有一个 mapred-site.xml.template文件,
我们需要将其复制并改名,位置不变,
命令是“ cp /opt/hadoop/hadoop/etc/hadoop/mapred-site.xml.template /opt/hadoop/hadoop/etc/hadoop/mapred-site.xml”,
然后,用 vi编辑 mapred-site.xml 文件,需要将下面的代码填充到文件的
编辑完毕,保存退出即可。
7.配置master的slaves文件
slaves 文件给出了 Hadoop 集群的 Slave 节点列表。该文件十分重要,因为启动Hadoop 的时候,
系统总是根据当前 slaves 文件中 Slave 节点名称列表启动集群,不在列表中的Slave 节点便不会被视为计算节点。
用 vi编辑 slaves 文件,我们应当根据自己所搭建集群的实际情况进行编辑。例如,我们这里由于已经安装了 Slave0 和 Slave1,
并且计划将它们全部投入 Hadoop 集群运行,所以应当输入如下代码。
slave0
slave1
8.复制master上的Hadoop到slave节点
由于我们这里有Slave0 和 Slave1,所以要复制两次。复制命令是:
scp -r /opt/hadoop root@slave1:/opt/hadoop
命令是:“ vi ~/.bash_profile ”,将下述代码追加到文件的尾部:
#HADOOP
export HADOOP_HOME=/opt/hadoop/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
保存退出后,执行“ source ~/.bash_profile ”命令,使上述配置生效。
请读者注意,也要在其他节点进行上述配置。
注意,这里的数据目录名 “hadoopdata”与前面 Hadoop 核心组件文件 core-site.xml 中的配置:
是一致的。
11.格式化文件系统
该操作只需要在 Master 节点上进行,命令是“ hdfs namenode -format ”
12.启动和关闭Hadoop
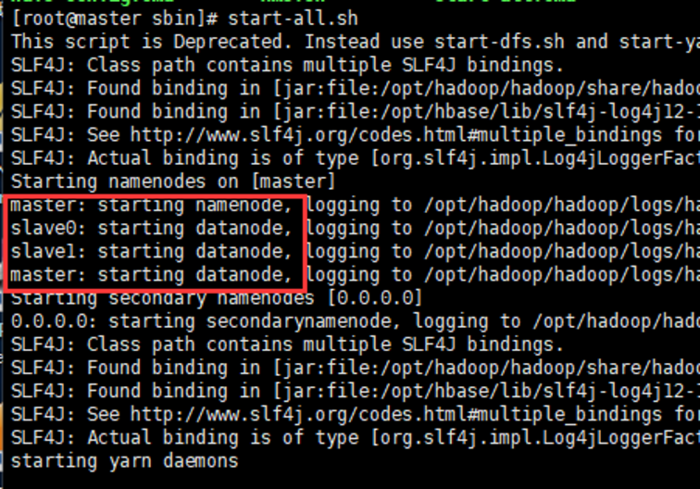
.首先进入 Hadoop 安装主目录,然后执行 sbin/start-all.sh 命令,执行命令后,
系统提示“ Are you sure want to continue connecting(yes/no)”,请输入yes,之后系统即可启动。
.要关闭 Hadoop 集群,可以使用 stop-all.sh 命令。
.下次启动 Hadoop 时候,无须 NameNode 的初始化,只需要使用start-dfs.sh 命令即可,然后接着使用 start-yarn.sh 启动 Yarn 。
.实际上,Hadoop 系统建议放弃(deprecated)使用 start-all. sh 和 stop-all.sh 一类的命令,而改用 start-dfs.sh 和 start-yarn .sh 命令。
13.验证Hadoop是否启动成功
(注:先看是否关闭或开起了防火墙,输入命令 hadoop dfsadmin -safemode leave)
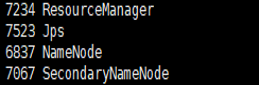
用户可以在终端执行 jps 命令查看 Hadoop 是否启动成功。在 Master 节点,
执行 jps后如果显示的结果是四个进程的名称: SecondaryNameNode、 ResourceManager、 Jps 和NameNode,
如下图所示,则表明主节点( Master )启动成功 。
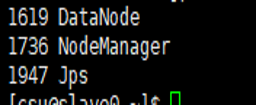
在 Slave0 节点执行 jps 命令,打印的结果中会显示三个进程,分别是 NodeManager、
Jps 和 DataNode ,如下图所示,表明从节点(Slave0)启动成功。其他节点可以类似验证。
14.在Hadoop集群中运行程序
在安装 Hadoop 的时候,系统给用户提供了一些 MapReduce 示例程序,其中有一个典型的用于计算圆周率 pi 的 Java 程序包,现在我们将其投入运行。
该 jar 包文件的位置和文件名是:
/opt/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar
我们在终端输入如下的运行命令:
hadoop jar /opt/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar pi 4 6
回车后即可开始运行。其中 pi 是类名,后面跟了两个10,它们是运行参数,第一个 10 表示 Map 次数,第二个 10 表示随机生成点的次数(与计算原理有关)。
如果执行中出现如下图所示的输出信息,表明程序在正常运行,系统处于良好状态 。
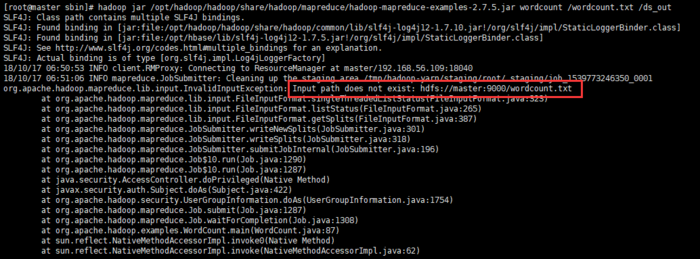
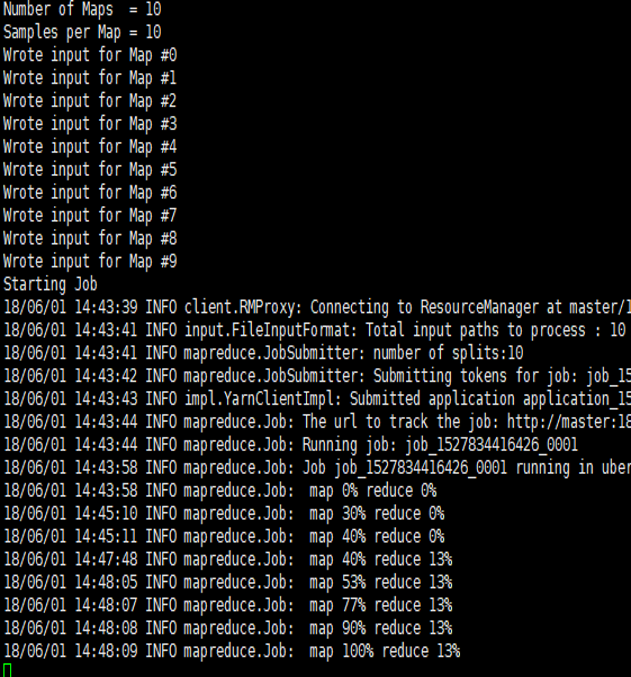

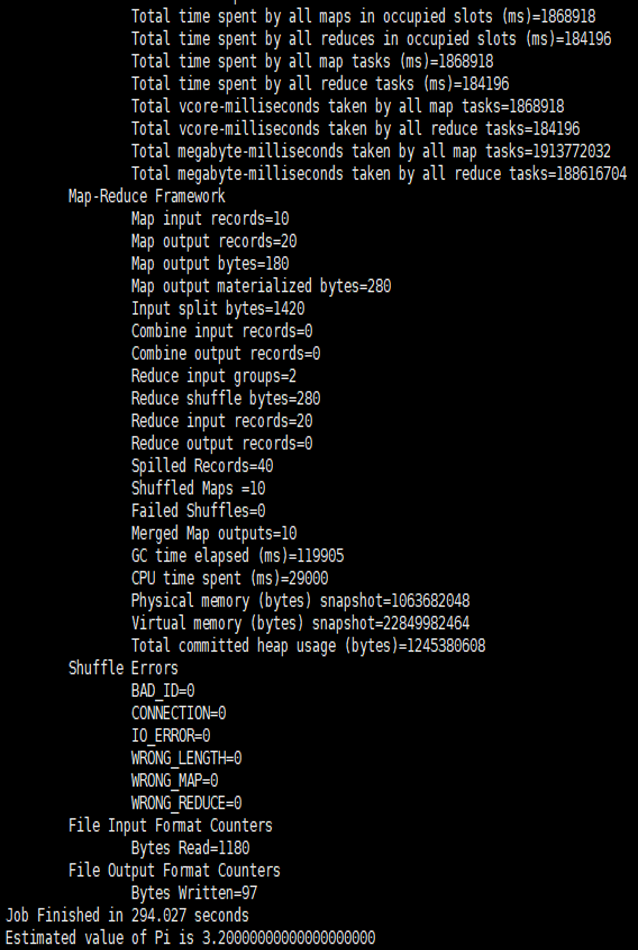
注:执行 Hadoop MapReduce 程序,是验证 Hadoop 系统是否正常启动的最后一个环节。实际上,
即使通过 jps 方式验证了系统己经启动,并且能够查看到状态信息,也不一定意味着系统可以正常工作。
例如,防火墙没有关闭的话, MapReduce程序执行不会成功。
hadoop dfsadmin -safemode leave
总结:本节主要介绍了 Hadoop 安装、配置、启动、运行简单程序。读者特别注意,
安装 Hadoop 以后,我们通过 jps 命令,分别在 Master 节点和 Slave 节点上查看NameNode 和 DataNode 进程是否启动;
运行一个MapReduce 程序,如典型的计算圆周率程序 Pi 。必须指出,如果这些验证都通过,才能说明系统安装成功,
如果运行程序不能成功,说明系统还存在问题,如防火墙没有关闭等。





 京公网安备 11010802041100号
京公网安备 11010802041100号