作者:Liko2502860873 | 来源:互联网 | 2023-09-02 16:32
Hadoop的HDFS和MapReduce子框架主要是针对大数据文件来设计的,在小文件的处理上不但效率低下,而且十分消耗磁盘空间(每一个小文件占用一个Block,HDFS默认block大小为64M)。解决办法通常是选择一个容器,将这些小文件组织起来统一存储。HDFS提供了两种类型的容器,分别是SequenceFile和MapFile。
一、SequenceFile
SequenceFile的存储类似于Log文件,所不同的是Log File的每条记录的是纯文本数据,而SequenceFile的每条记录是可序列化的字符数组。
SequenceFile可通过如下API来完成新记录的添加操作:
fileWriter.append(key,value)
可以看到,每条记录以键值对的方式进行组织,但前提是Key和Value需具备序列化和反序列化的功能
Hadoop预定义了一些Key Class和Value Class,他们直接或间接实现了Writable接口,满足了该功能,包括:
Text 等同于Java中的String
IntWritable 等同于Java中的Int
BooleanWritable 等同于Java中的Boolean
.
.
在存储结构上,SequenceFile主要由一个Header后跟多条Record组成,如图所示:
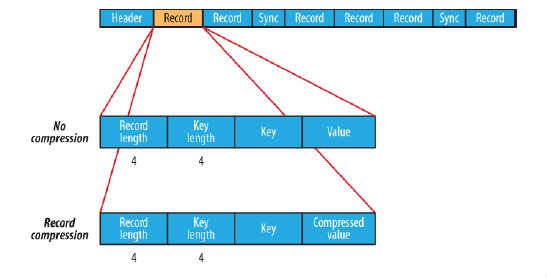
Header主要包含了Key classname,Value classname,存储压缩算法,用户自定义元数据等信息,此外,还包含了一些同步标识,用于快速定位到记录的边界。
每条Record以键值对的方式进行存储,用来表示它的字符数组可依次解析成:记录的长度、Key的长度、Key值和Value值,并且Value值的结构取决于该记录是否被压缩。
数据压缩有利于节省磁盘空间和加快网络传输,SeqeunceFile支持两种格式的数据压缩,分别是:record compression和block compression。
record compression如上图所示,是对每条记录的value进行压缩
block compression是将一连串的record组织到一起,统一压缩成一个block,如图所示:
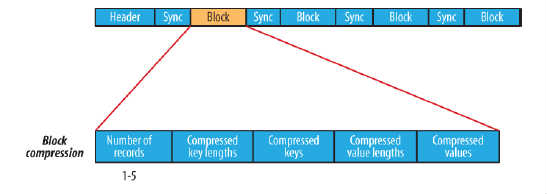
block信息主要存储了:块所包含的记录数、每条记录Key长度的集合、每条记录Key值的集合、每条记录Value长度的集合和每条记录Value值的集合







 京公网安备 11010802041100号
京公网安备 11010802041100号