为了进一步促进中文自然语言处理的研究发展,哈工大讯飞联合实验室发布基于全词覆盖(Whole Word Masking)的中文BERT预训练模型。我们在多个中文数据集上得到了较好的结果,覆盖了句子级到篇章级任务。同时,我们对现有的中文预训练模型进行了对比,并且给出了若干使用建议。我们欢迎大家下载试用。
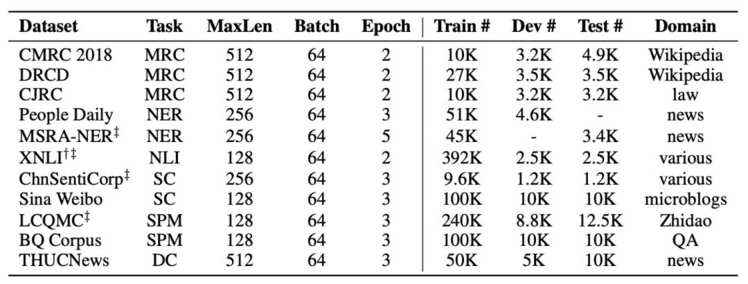
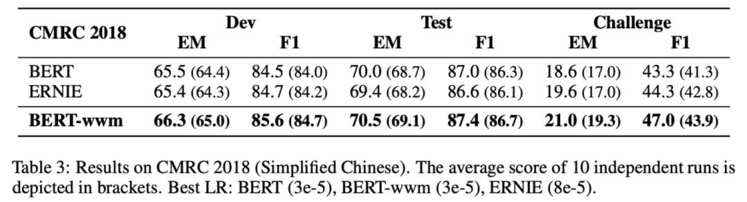
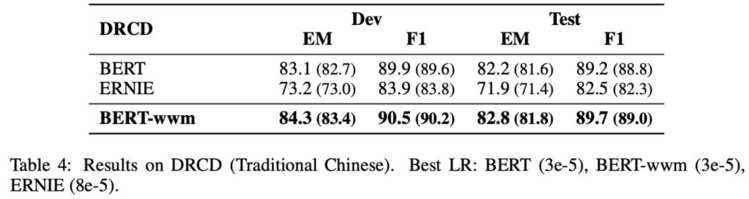
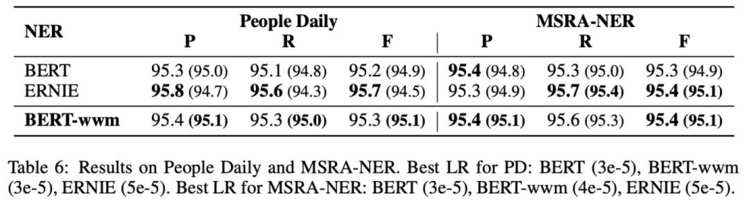
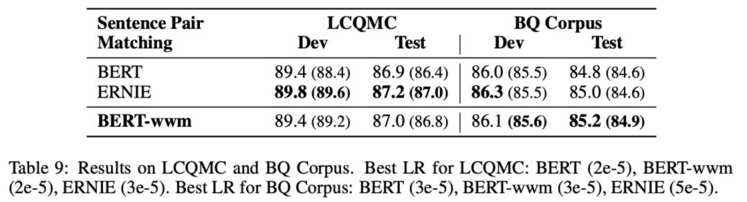
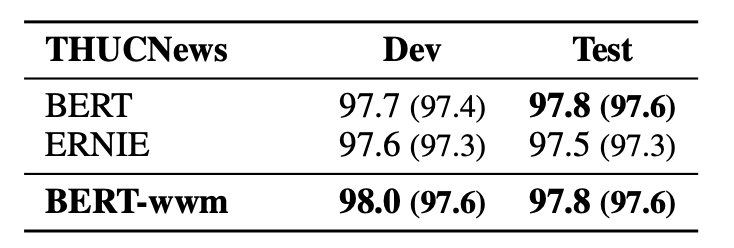
基于Transformers的双向编码表示(BERT)在多个自然语言处理任务中取得了广泛的性能提升。近期,谷歌发布了基于全词覆盖(Whold Word Masking)的BERT预训练模型,并且在SQuAD数据中取得了更好的结果。应用该技术后,在预训练阶段,同属同一个词的WordPiece会被全部覆盖掉,而不是孤立的覆盖其中的某些WordPiece,进一步提升了Masked Language Model (MLM)的难度。在本文中我们将WWM技术应用在了中文BERT中。我们采用中文维基百科数据进行了预训练。该模型在多个自然语言处理任务中得到了测试和验证,囊括了句子级到篇章级任务,包括:情感分类,命名实体识别,句对分类,篇章分类,机器阅读理解。实验结果表明,基于全词覆盖的中文BERT能够带来进一步性能提升。同时我们对现有的中文预训练模型BERT,ERNIE和本文的BERT-wwm进行了对比,并给出了若干使用建议。预训练模型将发布在:https://github.com/ymcui/Chinese-BERT-wwm
简介
Whole Word Masking (wwm),暂翻译为全词Mask,是谷歌在2019年5月31日发布的一项BERT的升级版本,主要更改了原预训练阶段的训练样本生成策略。简单来说,原有基于WordPiece的分词方式会把一个完整的词切分成若干个词缀,在生成训练样本时,这些被分开的词缀会随机被[MASK]替换。在全词Mask中,如果一个完整的词的部分WordPiece被[MASK]替换,则同属该词的其他部分也会被[MASK]替换,即全词Mask。

















 京公网安备 11010802041100号
京公网安备 11010802041100号