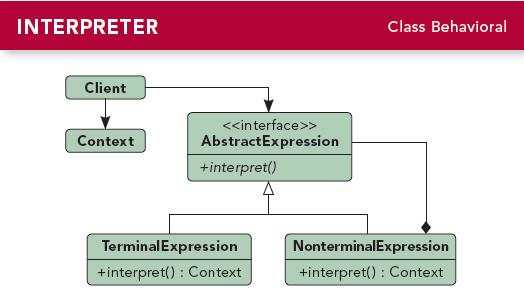
客户端连接HBase,常用的方式主要有两种,直连Zookeeper和连接HBase Thrift Server。第一种是Java中常用的方式,官方在hbase-client包里提供了丰富的API,另一种是HBase的thrift api,主要在跨语言环境中使用。
我们线上大部分的业务是由happybase封装的Python API来提供数据的读写服务,小部分业务则是用Java语言,例如:Flink实时作业中的HBaseSink。
实时程序读写HBase最开始使用的是hbase-client提供的API,随着越来越多实时业务的上线,被占用的zookeeper的连接资源也随之增加,甚至在有些极端场景下(也有可能是程序BUG),ZK的连接会被迅速消耗,导致HBase服务拒绝连接,流作业无法正常拉起。
基于上述因素,最后决定在Java环境中也使用HBase Thrift的api。但是,如果直接使用HBase Thrift提供的API读写HBase,你大概率会遇见如下问题:
因此,为了解决直接使用thrift api潜在的风险,我们需要为thrift api实现连接池,连接池应该至少具有以下功能。
以下内容将记录如何使用commons-pool2来实现HBase Thrift API的池化 ,commons-pool2比较典型的应用场景应该就是jedis啦,在我的设计中,也会或多或少参考jedis的源码实现,既然有造好的轮子,肯定选择优先使用。
出于文章的完整性考虑,第2小节中记录了commons-pool2的一些基础知识,使得文章略显冗余。大家可以直接跳读到自己感兴趣的段落。
commons-pool2是Apache的开源的一个优秀的对象池化组件,它对对象池化操作进行了很好的封装,基于此,我们只需要根据自己的业务需求重写或实现部分接口,就可以快速创建一个方便、简单、强大的对象连接池管理类。
这个是对象池实现的核心类,它实现了对对象池的管理,是一个基本的对象池实现,一般情况下,我们可以直接使用。在使用这个类的时候,我们需要传入两个重要的参数:GenericObjectPoolConfig类和PooledObjectFactory接口的实现。
在GenericObjectPool中,有两个我们会用到的方法:
// 对象使用完之后,归还到对象池
@Override
public void returnObject(final T obj) {
.....
}
// 从对象池中获取一个对象
@Override
public T borrowObject() throws Exception {
return borrowObject(getMaxWaitMillis());
}
其它还有一些方法,比如关闭对象池,销毁对象池,获取对象池中空闲的对象个数等,可以自行查看相关API,https://www.javadoc.io/doc/org.apache.commons/commons-pool2/2.5.0
这个接口是我们要实现的,它对要实现对象池化的对象做了一些管理。这个工厂接口就是为了让我们根据自己的业务创建和管理要对象池化的对象。也可以继承默认的抽象类:BasePooledObjectFactory
PooledObject
这个方法是用来创建一个对象,当在GenericObjectPool类中调用borrowObject方法时,如果当前对象池中没有空闲的对象,GenericObjectPool会调用这个方法,创建一个对象,并把这个对象封装到PooledObject类中,并交给对象池管理。
在连接池初始化时,初始化最小连接数,清除线程清除完过期连接后,池中连接数<最小连接数,需要调用此方法重新生成有效连接,使连接数达到池中最小连接数。获取新的连接时,池中连接对象均被占用,但当前连接数<最大连接数时,需要调用该方法产生一个新的连接。
void destroyObject(PooledObject
销毁对象,当对象池检测到某个对象的空闲时间(idle)超时,或使用完对象归还到对象池之前被检测到对象已经无效时,就会调用这个方法销毁对象。
对象的销毁一般和业务相关,但必须明确的是,当调用这个方法之后,对象的生命周期必须结束。如果是对象是线程,线程必须已结束,如果是socket,socket必须已close,如果是文件操作,文件数据必须已flush,且文件正常关闭。
对于实现这个方法来说非常重要的是要考虑到处理异常情况,另外实现必须考虑一个实例如果与垃圾回收器失去联系那么永远不会被销毁。
boolean validateObject(PooledObject
检测一个对象是否有效。在对象池中的对象必须是有效的,这个有效的概念是,从对象池中拿出的对象是可用的。比如,如果是socket,那么必须保证socket是连接可用的。在从对象池获取对象或归还对象到对象池时,有相应的参数配置,决定是否会调用这个方法,判断对象是否有效,如果无效就会销毁。
void activateObject(PooledObject
激活一个对象或者说启动对象的某些操作。比如,如果对象是socket,如果socket没有连接,或意外断开了,可以在这里启动socket的连接。它会在检测空闲对象的时候,如果设置了测试空闲对象是否可以用,就会调用这个方法,在borrowObject的时候也会调用。另外,如果对象是一个包含参数的对象,可以在这里进行初始化。让使用者感觉这是一个新创建的对象一样。
void passivateObject(PooledObject
钝化一个对象。在向对象池归还一个对象是会调用这个方法。这里可以对对象做一些清理操作。比如清理掉过期的数据,下次获得对象时,不受旧数据的影响。
一般来说activateObject和passivateObject是成对出现的。前者是在对象从对象池取出时做一些操作,后者是在对象归还到对象池做一些操作,可以根据自己的业务需要进行取舍。
这个抽象类是 PooledObjectFactory 接口的空现,并且透出了两个抽象方法必须实现。
public abstract T create() throws Exception;
创建一个对象实例,可以被wrap成一个PooledObject,这个方法必须支持并发和多线程。
public abstract PooledObject
把一个对象包装为一个PooledObject,此方法只在调用borrowObject方法的时候,且返回一个全新对象的时候执行,此方法处理create()方法的返回值。常见的处理方式是new DefaultPooledObject<>(obj)。可以在包装前进行其他逻辑的处理。
这种对象池和前面的GenericObjectPool对象池操作是一样的,不同的是对应的每个方法带一个key参数。你可以把这个GenericKeyedObjectPool的对象池看作是一个map的GenericObjectPool,每个key对应一个GenericObjectPool。它用于区别不同类型的对象。比如数据库连接,有可能会连接到不同地址的数据库上面。就可以用这个区分。
这个类允许使用者对对象池的一些参数进行调整,根据需要定制对象池。
lifo:对象池存储空闲对象是使用的LinkedBlockingDeque,它本质上是一个支持FIFO和FILO的双向的队列,common-pool2中的LinkedBlockingDeque不是Java原生的队列,而有common-pool2重新写的一个双向队列。如果为true,表示使用FIFO获取对象。默认值是true,建议使用默认值。
fairness:common-pool2实现的LinkedBlockingDeque双向阻塞队列使用的是Lock锁。这个参数就是表示在实例化一个LinkedBlockingDeque时,是否使用lock的公平锁。默认值是false,建议使用默认值。
maxWaitMillis:当没有空闲连接时,获取一个对象的最大等待时间。如果这个值小于0,则永不超时,一直等待,直到有空闲对象到来。如果大于0,则等待maxWaitMillis长时间,如果没有空闲对象,将抛出NoSuchElementException异常。默认值是-1;可以根据需要自己调整,单位是毫秒。
minEvictableIdleTimeMillis:对象最小的空闲时间。如果为小于等于0,是Long的最大值,如果大于0,当空闲的时间大于这个值时,执行移除这个对象操作。默认值是1000L * 60L * 30L;即30分钟。这个参数是强制性的,只要空闲时间超过这个值,就会移除。
softMinEvictableIdleTimeMillis:对象最小的空间时间,如果小于等于0,取Long的最大值,如果大于0,当对象的空闲时间超过这个值,并且当前空闲对象的数量大于最小空闲数量(minIdle)时,执行移除操作。这个和上面的minEvictableIdleTimeMillis的区别是,它会保留最小的空闲对象数量。而上面的不会,是强制性移除的。默认值是-1;
numTestsPerEvictionRun:检测空闲对象线程每次检测的空闲对象的数量。默认值是3;如果这个值小于0,则每次检测的空闲对象数量等于当前空闲对象数量除以这个值的绝对值,并对结果向上取整。
testOnCreate:在创建对象时检测对象是否有效,true是,默认值是false,一般新建对象都是有效的,所以建议为false。
testOnBorrow:在从对象池获取对象时是否检测对象有效,true是;默认值是false,尽量为false,每次获取对象都需要检测对象是否可用,会产生多余的网络开销,对性能有所影响。
testOnReturn:在向对象池中归还对象时是否检测对象有效,true是,默认值是false。
testWhileIdle:在检测空闲对象线程检测到对象不需要移除时,是否检测对象的有效性。true是,默认值是false。
timeBetweenEvictionRunsMillis:空闲对象检测线程的执行周期,即多长时候执行一次空闲对象检测。单位是毫秒数。如果小于等于0,则不执行检测线程。默认值是-1;
blockWhenExhausted:当对象池没有空闲对象时,新的获取对象的请求是否阻塞。true阻塞。默认值是true;
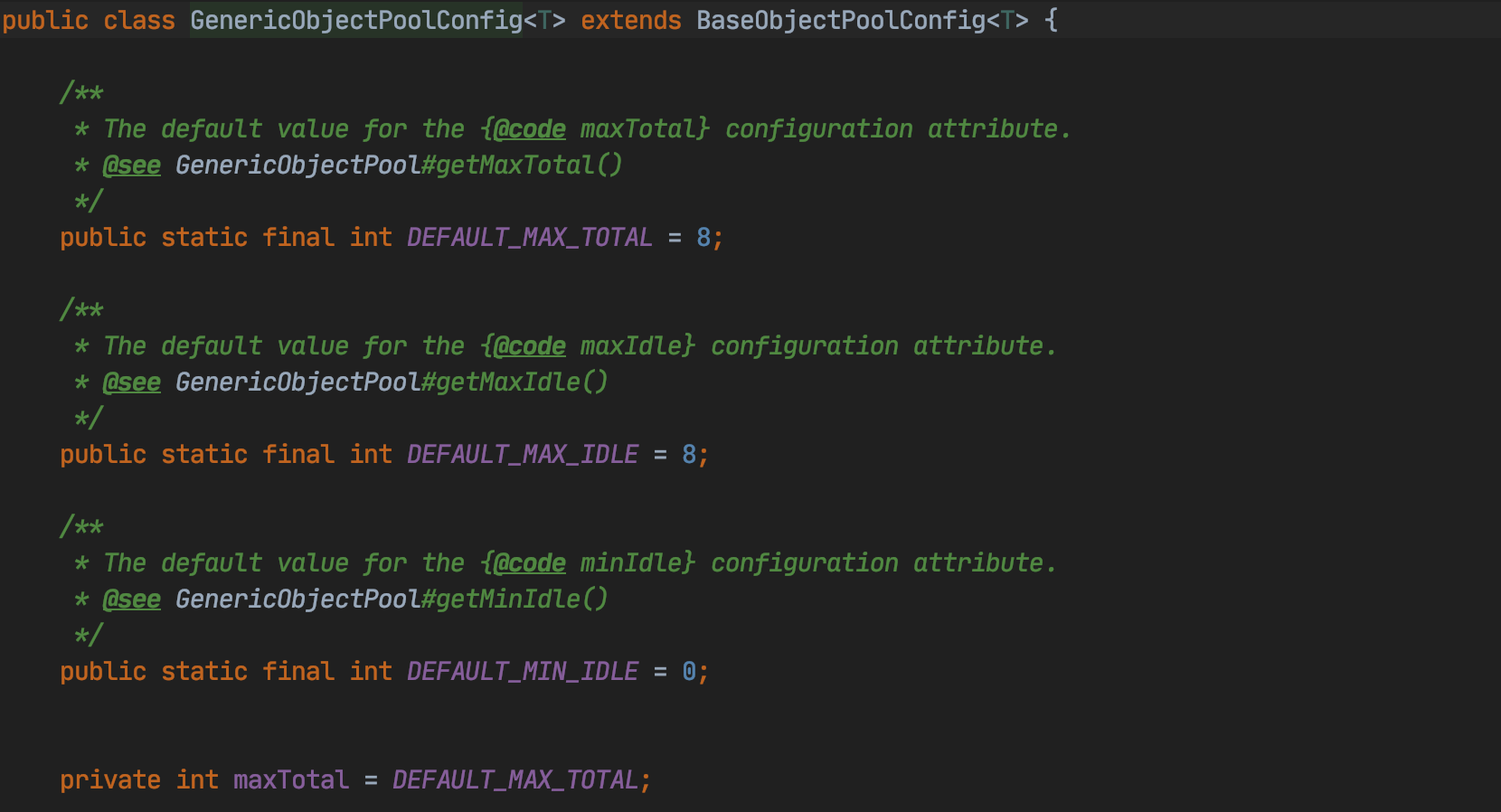
maxTotal:对象池中管理的最多对象个数。默认值是8。
maxIdle:对象池中最大的空闲对象个数。默认值是8。
minIdle:对象池中最小的空闲对象个数。默认值是0。
以上就是common-pool2对象池的配置参数,使用的时候可以根据自己的需要进行调整。这些参数更详细的说明以及调优建议,可以参考阿里云数据库Redis的实践文档: https://help.aliyun.com/document_detail/98726.html
上述内容的参考链接:
https://blog.csdn.net/u_ascend/article/details/80594306https://help.aliyun.com/document_detail/98726.html这里只记录连接池实现的思路与关键代码的实现,完整的源码和测试用例,可以参考hbase-sdk项目中的hbase-sdk-thrift-core模块,功能上的不足和建议也希望大家踊跃提issue。项目的地址:
https://gitee.com/weixiaotome/hbase-sdk
https://github.com/CCweixiao/hbase-sdk
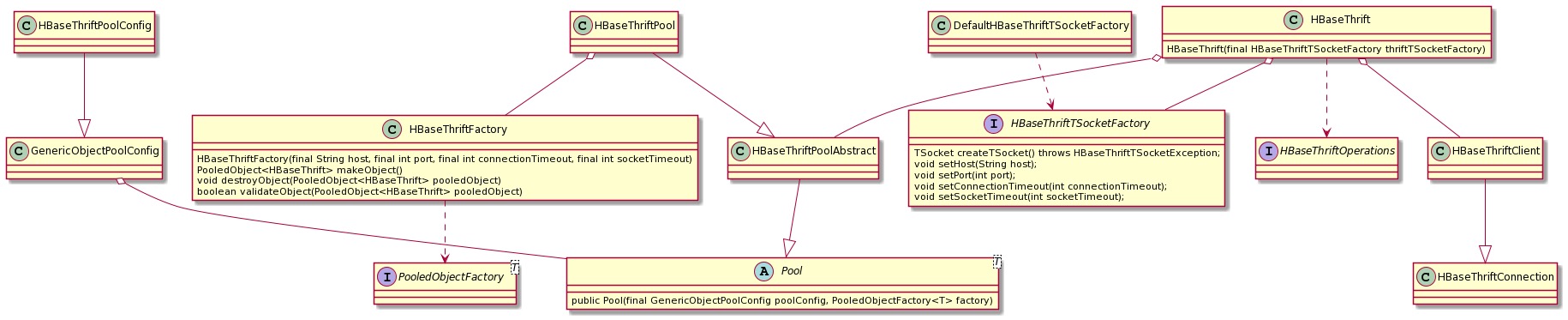
上图大致列举了连接池实现时所需的类与接口,及其之间的各种继承和组合关系。整个功能的实现基于 commons-pool2组件中几个核心的接口与类,代码简洁,逻辑清晰,无需在此处浪费过多笔墨,粘贴所有代码。
Pool是一个泛型抽象类,其核心功能是在池中产生托管对象和归还对象到池中,其初始化时需要提供GenericObjectPoolConfig的对象来设置连接池的参数,同时,传递PooledObjectFactory的工厂对象来提供连接创建等的具体方法。
HBaseThriftFactory实现了PooledObjectFactory所提供的接口,请重点关注以下三个核心方法:
PooledObject
destroyObject(PooledObject
validateObject(PooledObject
HBaseThriftConnection被HBaseThriftClient继承,HBaseThriftConnection与HBaseThriftTSocketFactory
接口的组合,实现了TSocket的声明周期管理,HBaseThriftTSocketFactory接口中提供了TSocket的声明方法:
TSocket createTSocket() throws HBaseThriftTSocketException;
该方法在DefaultHBaseThriftTSocketFactory类中被具体实现:
@Override
public TSocket createTSocket() throws HBaseThriftTSocketException {
TSocket socket = new TSocket(getHost(), getPort());
socket.setConnectTimeout(getConnectionTimeout());
try {
socket.open();
socket.setSocketTimeout(getSocketTimeout());
return socket;
} catch (TTransportException ex) {
socket.close();
throw new HBaseThriftTSocketException("The TSocket of HBase thrift server create or open failed", ex);
}
}
HBaseThrift类中融合了连接的创建以及各类读写HBase API的实现,在这个类中,需要重点关注,连接获取、销毁与归还等的逻辑。
如果你不想使用连接池,则可以直接直接创建这个类的对象,然后用其API来操作HBase。以上只是简单梳理了几个核心类大致的功能和关系,更细节的实现,感兴趣的伙伴可以参考hbase-sdk中的thrift API模块的源码。
以下内容将从实例入手,主要叙述连接池的核心功能,以及一些需要重点关注的地方。
@Test
public void testPut(){
// 声明连接池的配置对象
HBaseThriftPoolConfig cOnfig= new HBaseThriftPoolConfig();
// 创建HBase Thrift连接池
HBaseThriftPool hBaseThriftPool = new HBaseThriftPool(config, "localhost", 9090);
// 从连接池中获取到HBaseThrift对象,HBaseThrift中封装了对HBase的读写操作
final HBaseThrift hBaseThrift = hBaseThriftPool.getResource();
Map
data.put("info:name", "leo");
data.put("info:age", "18");
data.put("info:address", "shanghai");
// 保存数据
hBaseThrift.save("leo_test", "a10002", data);
// 关闭hBaseThrift对象,关闭即把该对象放回连接池中
hBaseThrift.close();
}
HBaseThriftPoolConfig继承GenericObjectPoolConfig,针对HBase Thrift服务端的配置以及所需需求,设置对象池的参数,以覆盖原有的参数。
public class HBaseThriftPoolConfig extends GenericObjectPoolConfig {
public HBaseThriftPoolConfig() {
// 连接池中的最大连接数,默认8,根据服务端可以容纳的最大连接数和当前并发数进行合理设置
setMaxTotal(1);
// 连接池中确保的最少空闲连接数
setMinIdle(1);
// 连接池中允许的最大空闲连接数
setMaxIdle(1);
// 连接池用尽后,调用者是否等待,为true时,maxWaitMillis才生效
setBlockWhenExhausted(true);
// 连接池用尽后,调用者的最大等待时间,毫秒,默认-1,表示永不超时
setMaxWaitMillis(6000);
// 每次从资源池中拿/归还连接是否校验连接的有效性,默认false,避免每次使用或归还连接与服务端进行一次连接开销
setTestOnBorrow(false);
setTestOnReturn(false);
// 开启JMX监控
setJmxEnabled(true);
// 是否开启空闲连接检测,默认false,建议true
setTestWhileIdle(true);
// 空闲连接的检测周期,毫秒,默认-1不进行检测,此处周期设置为1分钟
setTimeBetweenEvictionRunsMillis(60 * 1000);
// 空闲连接检测时,每次检测资源的个数,设置为-1,就是对所有连接进行检测
setNumTestsPerEvictionRun(-1);
// 连接池中连接的最小空闲时间,默认180000毫秒,30分钟,此处设置为1分钟
setMinEvictableIdleTimeMillis(60 * 1000);
}
}
我们可以根据自己的业务场景来设置合理的连接池大小,在HBase Thrift API的使用场景中,我们需要特别注意对连接对象有效性的检查,此处我们开启空闲连接检测,并设置检测周期为60秒,同时设置连接池中最小空闲时间也是60秒,这个参数配比主要为了解决,客户端超过一定时间不与服务端进行连接(在HBaseThriftServer中,默认60s之后,会断开客户端的空闲回话,由参数hbase.thrift.server.socket.read.timeout控制),服务端便会把此回话断开,当客户端再次尝试连接,就会报错:
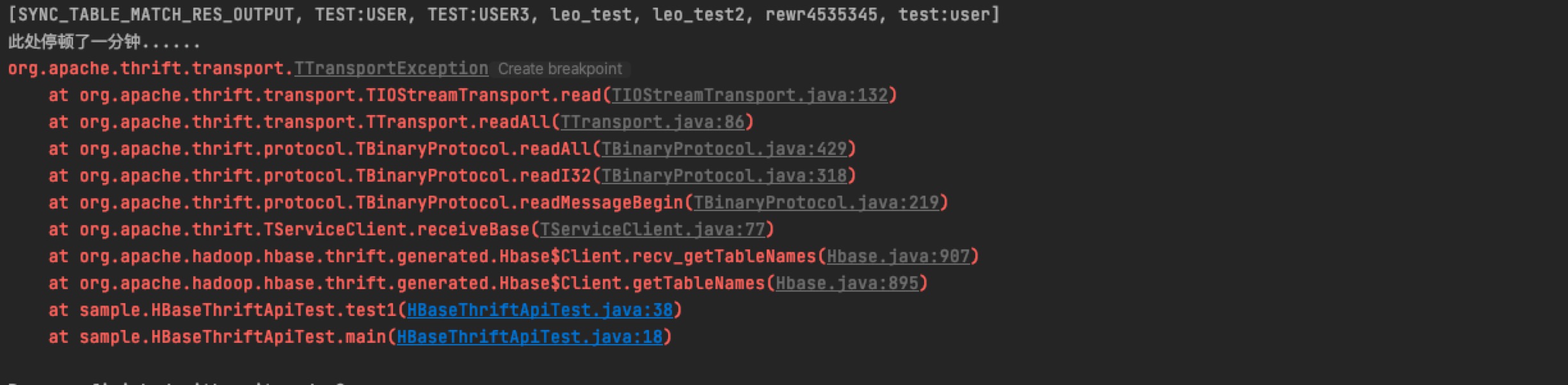
连接池中会自动检测连接的有效性,并及时清除超时闲置的链接,保证客户端每次获取的连接都是可用的,我们禁止在获取连接和归还连接时检测连接是否有效,主要为了避免多余的请求开销。因为,我们对连接检测的逻辑是:
@Override
public List
ArrayList
try {
for (ByteBuffer name : hbaseClient.getTableNames()) {
tableNames.add(ByteBufferUtil.byteBufferToString(name));
}
return tableNames;
} catch (TException e) {
throw new HBaseThriftException(e);
}
}
public void ping() {
getTableNames();
}
这里我ping的逻辑是获取集群的表名称列表,而不是调用TScoket的相关API来判断连接的有效性,如:TSocket中类似isOpen()的方法。Socket中诸如此类的方法来判断Socket的有效性,只能说明客户端中TSocket的连接状态是有效的,而在服务端,该对象对应的回话早已失效。
其次,我们需要业务方的并发需求,给连接池设置一个合理的参数,设置多了,会产生过多无用的连接;设置少了,又会增加客户端并发等待的时间,影响读写效率。如果没有连接池的机制,想要做到合理地使用这些连接对象,可能会产生比较多的问题,另一个典型的异常就是,业务高峰期,过多连接被突然创建,耗费本地机器过多端口,超出限制,造成本地短连接过多等问题。
先来看我们最终的调用效果
@Test
public void testPut2(){
HBaseThriftService hBaseThriftService = HBaseThriftServiceHolder.getInstance("localhost", 9090);
Map
data.put("info:name", "leo");
data.put("info:age", "18");
data.put("info:address", "shanghai");
// 保存数据
hBaseThriftService.save("leo_test", "a10003", data);
}
HBaseThriftServiceHolder是一个单例容器,单例模式保证我们在同一个进程中,连接池的对象只初始化一次。特别是在多线程的环境中,可以减少连接池资源创建的开销。
单例模式是一个非常常用且简单的设计模式,其实现的方式也有不下七八种,各有优劣,此处不再过多赘述。
此篇文章记述了在使用HBase Thrift 原生API的过程中遇到的一些问题,并参考jedis以及happybase对连接池的实现思路,基于commons-pool2实现客户端连接池,解决了客户端连接闲置超时的异常、短连接过多的隐患、以及对平衡性能与资源消耗的一些思考。文中或许有描述不当之处,在代码的实现上也许还可以再提高、再优化。希望读到朋友多多包涵,并积极指正。







 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有