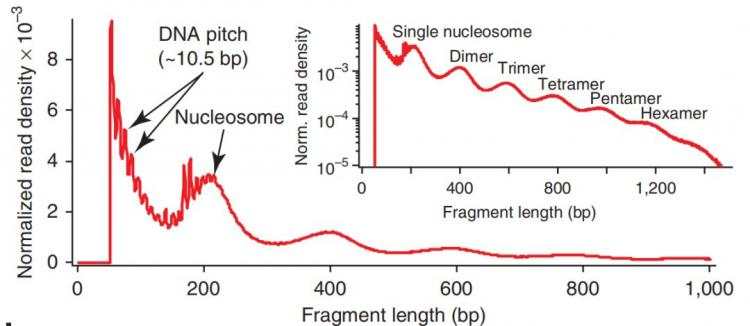
1 #!/usr/bin/env python 2 #_*_ coding:utf8 _*_ 3 #--Author--Tokay 4 ''' 5 @author:Tokay 6 @file:spider 7 @time:2018/11/28 8 ''' 9 from urllib.parse import urlencode 10 import pymongo 11 import requests 12 from lxml.etree import XMLSyntaxError 13 from requests.exceptions import ConnectionError 14 from pyquery import PyQuery as pq 15 from wx_config import * 16 17 #链接数据库 18 client = pymongo.MongoClient(MONGO_URI) 19 db = client[MONGO_DB] 20 21 #原始URL 22 base_url = 'https://weixin.sogou.com/weixin?' 23 24 #拼接headers信息 25 #COOKIE最好先登录一次在去获取,未使用COOKIE池 26 headers = { 27 'COOKIE': 'SUV=0094174DB715E6585BC3FE1950711692; IPLOC=CN4401; SUID=C34B43713020910A000000005BD32129; LSTMV=202%2C283; LCLKINT=5345; ABTEST=0|1543369487|v1; SNUID=AD70B5A49F9AE530288B692F9F14FD61; weixinIndexVisited=1; JSESSIOnID=aaaMTOQg0EtK5c_Cex6Cw; sct=3; ppinf=5|1543387462|1544597062|dHJ1c3Q6MToxfGNsaWVudGlkOjQ6MjAxN3x1bmlxbmFtZTo1NDolRTclODglQjElRTUlOTAlODMlRTUlQTUlQjYlRTklODUlQUElRTclOUElODQlRTclOEMlQUJ8Y3J0OjEwOjE1NDMzODc0NjJ8cmVmbmljazo1NDolRTclODglQjElRTUlOTAlODMlRTUlQTUlQjYlRTklODUlQUElRTclOUElODQlRTclOEMlQUJ8dXNlcmlkOjQ0Om85dDJsdUU3bG9rMWRsZkNNQVlka0VpWG9RRVVAd2VpeGluLnNvaHUuY29tfA; pprdig=JKiXOcRXslMUmqXyhN4ENi34_21yRh3DY84w1kXR9Rb34hQnBMY1JaWAygtf5rXz4CkKDJZM7IHylX86NGMR50RTG6NkICyfLzW2X5WIYCRRibfbehUItjTstuTJrfa9GBBT9EchpL_2qznzCXx8qU6ib_qQ4qzSDmMik-FK2Ns; sgid=02-36042859-AVvibOUYdic0W5tKL5W0hCiaqs; ppmdig=1543387462000000463e66125f125b9f2459029a31ff01dc', 28 'Host': 'weixin.sogou.com', 29 'Upgrade-Insecure-Requests': '1', 30 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36' 31 } 32 33 proxy = None 34 35 #获取代理IP 36 def get_proxy(): 37 try: 38 respOnse= requests.get(PROXY_POOL_URL) 39 if response.status_code == 200: 40 return response.text 41 return None 42 except ConnectionError as ec: 43 print(ec.args) 44 return None 45 46 47 #获取网页 48 def get_html(url,count=1): 49 print('获取的',url) 50 print('数量',count) 51 global proxy 52 if count >= MAX_COUNT: 53 print('最大统计数') 54 return None 55 try: 56 if proxy: 57 proxies = { 58 'http': 'http://' + proxy 59 } 60 respOnse= requests.get(url,allow_redirects=False,headers=headers,proxies=proxies) 61 else: 62 respOnse= requests.get(url, allow_redirects=False, headers=headers) 63 if response.status_code == 200: 64 return response.text 65 if response.status_code == 302: 66 #更换IP 67 print('302错误正在更换IP') 68 proxy = get_proxy() 69 if proxy: 70 print('正在使用proxy',proxy) 71 return get_html(url) 72 else: 73 print('获取代理失败') 74 return None 75 except ConnectionError as ec: 76 print('链接错误',ec.args) 77 proxy = get_proxy() 78 count += 1 79 return get_html(url,count) 80 81 #获取页面信息 82 def get_index(keyword,page): 83 data = { 84 'query': keyword, 85 'type': 2, 86 'page': page 87 } 88 queries = urlencode(data) 89 url = base_url + queries 90 html = get_html(url) 91 return html 92 93 #解析页面信息 94 def parse_index(html): 95 96 doc = pq(html) 97 items = doc('.news-box .news-list .txt-box h3 a').items() 98 for item in items: 99 yield item.attr('href') 100 101 #获取详情页 102 def get_detail(url): 103 try: 104 respOnse= requests.get(url) 105 if response.status_code == 200: 106 return response.text 107 return None 108 except ConnectionError as ec: 109 print('获取详情页错误') 110 return None 111 112 #解析详情页 113 def parse_detail(html): 114 try: 115 doc = pq(html) 116 title = doc('.rich_media_title').text() 117 cOntent= doc('.rich_media_content ').text() 118 date = doc('#publish_time').text() 119 nickname = doc('.rich_media_meta_list .rich_media_meta_nickname').text() 120 wechat = doc('#js_profile_qrcode > div > p:nth-child(3) > span').text() 121 return { 122 'title': title, 123 'content': content, 124 'date': date, 125 'nickname': nickname, 126 'wechat': wechat 127 } 128 except XMLSyntaxError: 129 print('解析详情页失败') 130 return None 131 #存入mongodb 132 def save_to_mondb(data): 133 if db['articles'].update({'title':data['title']},{'$set':data},True): 134 print('正在存储到数据库',data['title']) 135 else: 136 print('正在存储到数据库发生错误', data['title']) 137 def main(): 138 for page in range(1,101): 139 html = get_index(KEYWORD, page) 140 if html: 141 article_urls = parse_index(html) 142 for article_url in article_urls: 143 article_html = get_detail(article_url) 144 if article_html: 145 artticle_data = parse_detail(article_html) 146 print(artticle_data) 147 if artticle_data: 148 save_to_mondb(artticle_data) 149 150 if __name__ == '__main__': 151 main()
#ip代理池 PROXY_POOL_URL = 'http://127.0.0.1:5000/get' #搜索关键词 KEYWORD = '东京食种' #mongo连接地址 MONGO_URI = 'localhost' #数据库名 MONGO_DB = 'weixin_Tokay' #最大统计数 MAX_COUNT = 5






 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有